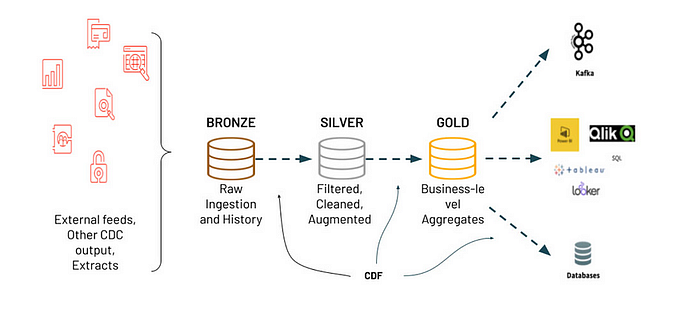

After explaining what Delta Live Tables are and then going in depth on how we can record data source changes of those tables with Change Data Capture (CDC), there is yet another useful feature for your Delta Tables called Change Data Feed or CDF. This feature will record changes in your data at the row-level while also optimizing your ETL pipelines performance.
But before I explain Change Data Feed, for those of you reading my articles for the first time, let me provide a brief summary of what Delta Tables, Delta Live Tables, and Change Data Capture are:
What are Delta Tables in Databricks?
Remember that all things Delta in Databricks refers to the storage layer of the Delta Lake, with the capabilities of handling real-time and batch big data. A Delta Table is the default data table structure used within data lakes for data ingestion via streaming or batches. A general way of creating a DT in databricks is provided below. Please note, you do not have to import and initialize your spark session as Databricks already includes this but adding for reference:
# Import libraries for spark session
from pyspark.sql import SparkSession
from delta import DeltaTable
# Initialize spark session
spark = SparkSession.builder \
.appName("CreateDeltaTable") \
.getOrCreate()
# Import necessary libaries to load dataframe as csv
import pandas as pd
import csv
# Bring in your csv file as a dataframe using pandas
df = pd.read_csv(file_location)
# Load dataframe to a Delta Table
delta_table_path = "/mnt/data/delta_table"
delta_table = spark.read.format("delta").load(delta_table_path)
# Define hive database and table
hive_database = "database_name"
hive_table = "your_table_name"
# rite Delta Table to Hive Metastore
delta_table.write \
.format("delta") \
.saveAsTable(f"{hive_database}.{hive_table}")What are Delta Live Tables in Databricks?
Delta Live tables take these Delta tables to the next stage of data management where you can manage the flow of data for your data pipelines. These DLTs for short allow you to orchestrate, monitor, and establish data quality practices with your pipelines via Databricks UI on the platform. Delta Live tables need to be created by using the "Steaming Live Table" when creating them. I am using a prior example in my previous articles outlining DLT creation:
# Create a DLT for streaming data
spark.sql("""
CREATE OR REFRESH STREAMING LIVE TABLE streaming_data
COMMENT "Real-time streaming data"
AS
SELECT
CAST(event_timestamp AS TIMESTAMP) as event_timestamp,
value
FROM
kafka.`topic_name`
OPTION (
'startingOffsets' 'earliest',
'endingOffsets' 'latest',
'subscribe' 'topic_name'
)
""")What is Change Data Capture in Databricks?
Change Data Capture was explained in my previous article but primarily this is a feature in Databricks which allows you track changes from your data source as data is being ingested into your ETL pipelines. Here I am using my previous article as an artificial table on product information called "product_catalog". Here, I am monitoring every change to the data source as it comes into the table every 3 seconds:
# Import libraries for spark session
from pyspark.sql import SparkSession
from pyspark.sql.functions import lit
import time
# Initialize your Spark session
spark = SparkSession.builder \
.appName("CDC") \
.getOrCreate()
# Define your Delta Lake table path
delta_path = "/mnt/delta/product_catalog"
# Create a DataFrame with initial product data
data = [(1, "Product A", 100.00), (2, "Product B", 200.00)]
columns = ["product_id", "product_title", "price"]
df = spark.createDataFrame(data, columns)
# Write the DataFrame to the Delta Lake table
df.write.format("delta").mode("overwrite").save(delta_path)
# Function to simulate changing product data (CDC)
def change_product_data(product_id, new_name, new_price):
change_data = [(product_id, new_name, new_price)]
change_df = spark.createDataFrame(change_data, columns)
change_df.write.format("delta").mode("append").save(delta_path)
# Simulate changing product data every 3 seconds
while True:
# Change data for Product ID 1
change_product_data(1, "New Product A", 12.00)
# Simulate a delay of 3 seconds
time.sleep(3)
# Stop the Spark session
spark.stop()What is Change Data Feed in Databricks?
So now that we understand that we are creating Delta Tables to construct our ETL pipelines with Delta Live Tables, and then recording our data changes real time with CDC, we can optimize the entire ETL process with Change Data Feed or CDF. Change data feed is defined in the Databricks documentation below:
"Change data feed allows Databricks to track row-level changes between versions of a Delta table. When enabled on a Delta table, the runtime records change events for all the data written into the table. This includes the row data along with metadata indicating whether the specified row was inserted, deleted, or updated."
What this means is that by using CDF, you can monitor incremental changes to your data as it comes in. I would like to consider a scenario where you are collecting emails at a transactional level and you are then storing them in your data warehouse. I am making an example just for reference:

As you look, John Doe and Lady Jane have their emails submitted on 10/7 and 10/8 respectively and uniquely identified under "Subject_ID". To initialize and use CDF for this table, you must then follow the below steps outlined:
- Enable CDF: You must enable each Delta Table you create in order to use CDF. I am providing an example below of the table provided above:
CREATE TABLE customer_transactions(
Subject_ID STRING,
First_Name STRING,
Last_Name STRING,
Email STRING,
Transaction_Date TIMESTAMP
)
USING delta
TBLPROPERTIES (delta.enableChangeDataFeed = true)- Process and Load Changes: The table now has enabled CDF so it will track all updates, merge, and delete actions on the table. Now as time progresses, you will see the change type and time of change. An example is provided below from our previous view to now:

As you can see, John Doe and Lady Jane updated their email with their middle initial the day after they registered their initial email. This happened on the first initial event since their first submission was of Version 0 and since updated is now Version 1.
Next, we need to load these changes to the data warehouse. We will do an inner join of our first initial table to the updated table to reflect those changes in Databricks. Since both John Doe and Lady Jane updated their emails, both "Subject_ID" will be reflected with those updates as Version 1:

Your table will now reflect row-level changes at the update, insert, and merge commands:
# Import SparkSession
from pyspark.sql import SparkSession
# Create a new SparkSession, called Changed_records_using_CDF
spark = SparkSession.builder \
.appName("Changed_records_using_CDF") \
.getOrCreate()
# Read the changed data from version 0 to 1 for table Email_List
changes_df = spark.sql("""
SELECT *
FROM table_changes('Email_List', 0, 1)
""")
# Separate the different types of changes
email_df = changes_df.filter(changes_df.change_type == "Initial_data")
updates_email_df = changes_df.filter(changes_df.change_type == "Updated_data")
new_data_df = changes_df.filter(changes_df.change_type == "Inserted_data")
# Join initial vs updated by email
joined_df = email_df.alias("initial") \
.join(updates_email_df.alias("Updated"),
on="Subject_ID",
how="inner") \
.selectExpr("initial.Subject_ID as Subject",
"initial.Email as Old_Email",
"Updated.Email as New_Email")
# Show the joined updates
joined_df.show()
# Example: Write the inserted transactions to a Delta table
new_data_df.write.format("delta").mode("append").save("/path/to/inserts_delta_table")
# Stop the Spark session when done
spark.stop()How does this optimize your ETL pipelines?
Incorporating CDF allows you to integrate with your ETL process so that the pipeline only incorporates the changes that are needed instead of your entire dataset. Furthermore, within the CDF, there's a provision for version control, enabling the historical monitoring of alterations and compliance with the table's data retention guidelines, thus preventing excessive storage usage. Additionally, CDF supports versioning for historical tracking, adheres to retention policies, and integrates with tools like Apache Spark, making CDC more efficient and adaptable for pipelines.
Key Advantages of Change Data Feed:
- Scalable with your Delta Tables: Change Data Feed (CDF) accommodates growing datasets and tracks these changes.
- Incremental Updates to downstream tables: CDF allows you to provide incremental updates to downstream tables, reducing the need for complete data reloading and improving data synchronization.
- Improve ELT Pipeline Performance: By tracking and processing only the changes that occur, CDF significantly enhances ELT pipeline performance, reducing time and resources.
Challenges and Limitations:
- Data Storage Cost: Storing change data logs can incur additional storage costs, primarily for large datasets with heavy changes.
- Hive Metastore or Unity Catalog: Integration with Hive Metastore or Unity Catalog may be required for optimal management of metadata and table tracking, which adds complexity.
In conclusion, CDF provides a way for you to keep row-level changes on your Delta Tables that can optimize and speed up your ETL pipelines. It serves as a feature that can keep an audit trail on your data changes while also helping to create an organized approach to data streaming and batched loading at your fingertips. Understanding and implementing this feature will be useful for many practitioners who come across numerous changes to their data over time.
For references directly related to Databricks CDF and associated material worth reading, please see below:
- Change Data Feed, Original Databricks Documentation: https://docs.databricks.com/en/delta/delta-change-data-feed.html
- Delta Lake official CDF example: https://delta.io/blog/2023-07-14-delta-lake-change-data-feed-cdf/
- Delta Lake Change Data Feed: https://docs.delta.io/2.0.0/delta-change-data-feed.html