


User Defined Functions in Apache Spark allow extending the functionality of Spark and Spark SQL by adding custom logic. These are similar to functions in SQL. We define some logic in functions and store them in the database and use them in queries.
UDFs is that they act on one row, and therefore, are invoked for every row in the data set. So UDF can be used to replace separate for-loops for faster performance.
from pyspark import SparkConf
from pyspark.sql import SparkSession
import pyspark.sql.functions as spark_func
from pyspark.sql.types import IntegerType, StructType, StructField, ArrayType, StringType, DateType, MapType
def create_spark_session(app_name: str) -> SparkSession:
conf = SparkConf().set("spark.driver.memory", "8g")
spark_session = SparkSession\
.builder\
.master("local[*]")\
.config(conf=conf)\
.appName(app_name) \
.getOrCreate()
return spark_session
def create_df(spark: SparkSession) -> DataFrame:
...
return data_df
# Creating UDF using Annotation/Decorator
@spark_func.udf(returnType=MapType(StringType(), LongType()))
def aggregate_maps(input_maps: List[Dict[str, int]]) -> Dict[str, int]:
# function definition
...
return agg_result
if __name__ == '__main__':
spark = create_spark_session(app_name="udf_demo")
data_df = create_df(spark=spark)
aggregated_df = data_df\
.groupby("make", "model")\
.agg(spark_func.collect_list("sales_by_city").alias("sales_by_city"))
result_df = aggregated_df.withColumn("agg_sales", aggregate_maps("sales_by_city"))
result_df.show(truncate=False)We can also register udf
from pyspark.sql.functions import udf
def cool_function(input_1: input_type, input_2: input_type) -> return_type:
return return_obj
udf_name = udf(lambda input_1, input_2: cool_function(input_1, input_2), return_type)
df.withColumn('new_col_name', udf_name(df.col1, df.col2)).show()To use it with PySpark SQL
spark.udf.register("udf_name", cool_function, return_type)Important points to note
The default Type in UDF Function is StringType(). Also, we need to handle NULLs explicitly otherwise, we will see side effects. If we have a column that contains the value null on some records, it will through an AttributeError. We should check for nulls in our function.
PySpark SQL doesn't give ensure the order of evaluation of subexpressions. For example, if a UDF function is trying to leverage short-circuiting in SQL for null checking, there's no guarantee that the NULL check will happen before invoking the UDF.
A PySpark UDF will return a column of NULLs if the input data type doesn't match the output data type. So we need to ensure the correct data type of the UDF.
Pandas UDF in PySpark
Pandas UDF also known as vectorized UDF is a user-defined function in Spark which uses Apache Arrow to transfer data to and from Pandas and is executed in a vectorized way.
Pandas UDF in Pyspark take in a batch of rows and execute them together and return the result back as a batch. Hence, a Pandas UDF is invoked for every batch of rows instead of a row-by-row execution.
from pyspark.sql.functions import pandas_udf, PandasUDFType
from pyspark.sql.types import StringType
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
spark.conf.set("spark.sql.execution.arrow.fallback.enabled", "true")
@pandas_udf("string", functionType=PandasUDFType.SCALAR)
def pandas_odd_or_even(x):
return (x%2).map({0: "even", 1: "odd"})
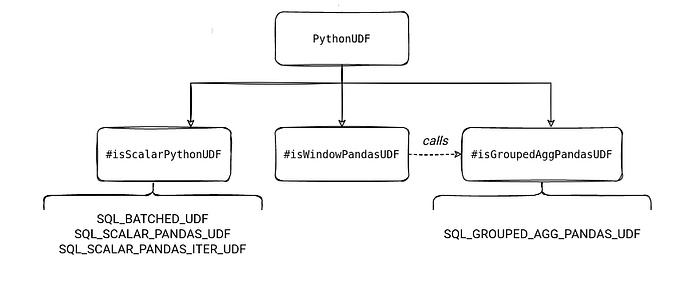
Since PySpark supports two types of UDFs row-by-row and vectorized one (pandas), PySpark distinguishes a vectorized function from a standard one with the evalType
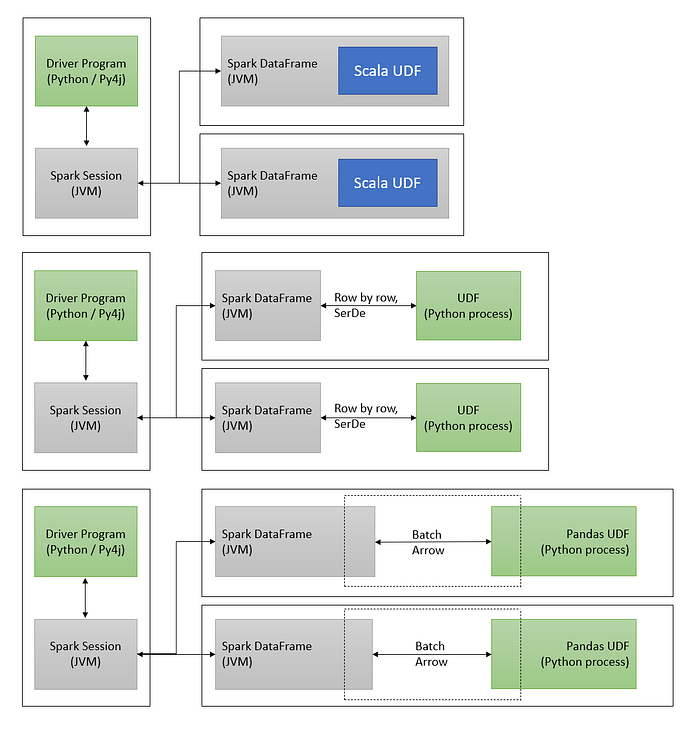
The UDF developed in Python acts as an alien to spark JVM. It spins out as a separate Python process. This process creates unnecessary overhead and SerDe operations. To improve on this we can write UDFs in Java and create a jar out of it and place it in the PySpark environment.
.config('spark.jars', "/path/to/udf.jar")
# OR
--jar /path/to/udf.jar
spark.udf.registerJavaFunction("udf_name", "java.package.name")Higher Order Function > UDF scala with python wrappers ≥ Scala UDF > RDD scala > Pandas UDF > Python UDF > RDD Python (In terms of performance)
While working with Pyspark SQL and UDF, Spark will give random names to the transformed column, we will need to wrap the SQL into a select so that the defined column names can be used in the where clause for filtering.
UDFs considered deterministic. This leads to a scenario where UDF will be executed multiple times for each record, affecting overall application performance. Workaround for this is to cache the DataFrame or make the function non-deterministic while registering .asNondeterministic().
Drawbacks
- UDFs are black-box for optimization, and therefore, cannot be properly optimized by Spark. For example, optimizations such as filter pushdown to source data are not applied if those filters are defined in UDFs.
- There is additional overhead in using UDFs in PySpark, because the structures native to the JVM environment that Spark runs in, have to be converted to Python data structures to be passed to UDFs, and then the results of UDFs have to be converted back.
- Debugging issues linked to UDFs are hard
- UDFs needs special care while moving between version.
- UDF might get executed more times than expected.
- If UDF is non-deterministic some optimization will be skipped.
- UDF removes the information about the data distribution, so it might cause additional shuffle.
Creating Python wrapper on scala udf
We can write utility UDFs in Scala and ship these as packages in the Spark environment.
package customsparkudf
import org.apache.spark.sql.functions._
object UDFs {
import org.apache.spark.sql.functions.udf
def demo_func(field: Double): Double = field * 1000
def udf_demo_func = udf(demo_func _)
}
from pyspark.sql.column import Column
from pyspark.sql.column import _to_java_column
from pyspark.sql.column import _to_seq
from pyspark.sql.functions import col
def udf_demo_func_wrapper(field):
_udf_demo_func = sc._jvm.customsparkudf.UDFs.udf_demo_func()
return Column(__udf_demo_func.apply(_to_seq(sc, [field], _to_java_column)))
df.select(udf_demo_func_wrapper(col("X")).alias("scaled")).show()In most of the cases, Performance of the wrapper function will be better than other python methods.
Best Practices
- Use PySpark API as long as feasible before writing UDFs
- Explicitly define input & output schema.
- Handle null values properly
- Keep your UDFs simple
To summarize, User Defined Functions (UDFs) should be the last choice, and as much as possible, built-in Higher Order functions should be used. from pyspark.sql.functions import aggregate, lit, length, size
Thanks!!