

Parametric actions to improve reinforcement learning
RL algorithms learn via trial and error. The agent searches the state space early on and takes random actions to learn what leads to a good reward. Pretty straightforward.
Unfortunately, this isn't terribly efficient, especially if we already know something about what makes a good vs. bad action in some states. Thankfully, we can use action masking — a simple technique that sets the probability of bad actions to 0 — to speed learning and improve our policies.
TL;DR
We enforce constraints via action masking for a knapsack packing environment and show how to do this using RLlib.
Enforcing Constraints
Let's use the classic knapsack problem to develop a concrete example.
The knapsack problem (KP) asks you to pack a knapsack to maximize the value in the bag without overloading it. If you have a collection of items like we have shown below, the optimal packing is going to contain three of the yellow boxes and three of the gray boxes for a total of $36 and 15kg (this is the unbounded knapsack problem because you have no limit on how many boxes you can choose).
Typically, this problem is solved using dynamic programming or math programming. If we set it up following a math program, we can write out the model as follows:
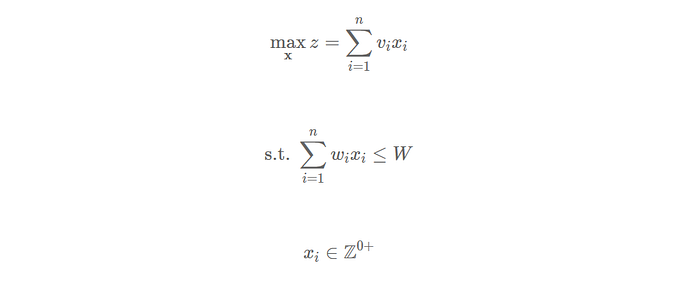
In this case, x_i is can be any value ≥0 and symbolizes the number of items i we place into the knapsack. v_i and w_i, are the values and weights of the items respectively.
In plain language, this small model is saying we want to maximize the value in the knapsack (which we call z). We do this by finding the largest number of items (x_i) and their values (v_i) without exceeding the weight limit of the knapsack (W). This formulation is known as an Integer Program (IP) because we have integer decision variables (we can't pack parts of items, just full, integer values) and is solved using a solver like CPLEX, Gurobi, or GLPK (the last one is free and open source).
Enforcing those constraints are built into the model, but it's not naturally built into RL. The RL model may need to pack the green, 12kg box a few times before learning that it can't pack that and the yellow, 4kg box, by getting hit with a large, negative reward a few times. The negative reward for over packing is a "soft constraint" because we aren't explicitly forbidding the algorithm from making these bad decisions. But, if we use action masking, we can ensure that the model doesn't make dumb choices, which will also help it learn better policies, faster.
The KP Environment
Let's put this into action by packing a knapsack using the or-gym library, which contains some classic environments from the operations research field that we can use to train RL agents. If you're familiar with OpenAI Gym, you'll use this in the same way. You can install it with pip install or-gym.
Once that's installed, import it and build the Knapsack-v0 environment, which is the unbounded knapsack problem we described above.
import or_gym
import numpy as np
env = or_gym.make('Knapsack-v0')The default settings for this environment has 200 different items to choose from and has a maximum weight capacity of 200kg.
print("Max weight capacity:\t{}kg".format(env.max_weight))
print("Number of items:\t{}".format(env.N))
[out]
Max weight capacity: 200kg
Number of items: 200This is fine, but 200 items are a little much to see clearly, so we can pass an env_config dictionary to change some of these parameters to match the example above. Additionally, we can turn action masking on and off by passing mask: True or mask: False to the configuration dictionary.
env_config = {'N': 5,
'max_weight': 15,
'item_weights': np.array([1, 12, 2, 1, 4]),
'item_values': np.array([2, 4, 2, 1, 10]),
'mask': True}
env = or_gym.make('Knapsack-v0', env_config=env_config)
print("Max weight capacity:\t{}kg".format(env.max_weight))
print("Number of items:\t{}".format(env.N))
[out]
Max weight capacity: 15kg
Number of items: 5Now our environment matches the example above. Let's look at our state briefly.
env.state
[out]
{'action_mask': array([1, 1, 1, 1, 1]),
'avail_actions': array([1., 1., 1., 1., 1.]),
'state': array([ 1, 12, 2, 1, 4, 2, 4, 2, 1, 10, 0])}When we set the action mask option to True, we get a dictionary output as the state that contains three entries, action_mask, avail_actions, and state. This is the same format for all environments in the or-gym library. The mask is a binary vector where 1 indicates an action is allowed and 0 indicates it is going to break some constraint. In this case, our only constraint is the weight, so if a given item would push the model over weight, it is going to receive a large, negative penalty.
The available actions correspond to each of the five items the agent can select for packing. The state is the input that gets passed to the neural network. In this case, we have a vector that has concatenated the item weights and values, and has the current weight tacked on the end (0 when you initialize the environment).
If we go ahead and select the 12kg item to pack, we should see that action mask update to eliminate packing any other item that puts the model over the weight limit.
state, reward, done, _ = env.step(1)
state
{'action_mask': array([1, 0, 1, 1, 0]),
'avail_actions': array([1., 1., 1., 1., 1.]),
'state': array([ 1, 12, 2, 1, 4, 2, 4, 2, 1, 10, 12])}If you look at the action_mask, that's exactly what we see. The environment is returning information that we can use to prevent the agent from selecting either the 12kg or the 4kg item because it will violate our constraint.
The concept here is really straightforward to apply. After you complete the forward pass through your policy network, you use the mask to update the values for the illegal actions so that they become large, negative numbers. That way, when you pass it through the softmax function, the probabilities associated with these are going to be 0.
Now, let's turn to using RLlib to train a model to respect these constraints.
Action Masking in RLlib
Action masking in RLlib requires building a custom model that handles the logits directly. For a custom environment with action masking, this isn't as straightforward as I'd like, so I'll walk you through it step-by-step.
There are a lot of pieces we're going to need to import first. ray and our ray.rllib.agents should be obvious if you're familiar with the library, but we'll also need tune, gym.spaces, ModelCatalog, a Tensorflow or PyTorch model (depending on your preference, for this I'll just stick to TF), and a utility in the or_gym library called create_env that we wrote to make this a bit smoother.
import ray
from ray.rllib import agents
from ray import tune
from ray.rllib.models import ModelCatalog
from ray.rllib.models.tf.tf_modelv2 import TFModelV2
from ray.rllib.models.tf.fcnet import FullyConnectedNetwork
from ray.rllib.utils import try_import_tf
from gym import spaces
from or_gym.utils import create_env
tf = try_import_tf()Building a Custom Model
We need to tell our neural network explicitly how to handle the different values in our state dictionary. For this, we'll build a custom model based on the TFModelV2 module from RLlib. This will enable us to build a custom model class and add a forward method to the model in order to use it. Within the forward method, we apply the masks as shown below:
class KP0ActionMaskModel(TFModelV2):
def __init__(self, obs_space, action_space, num_outputs,
model_config, name, true_obs_shape=(11,),
action_embed_size=5, *args, **kwargs):
super(KP0ActionMaskModel, self).__init__(obs_space,
action_space, num_outputs, model_config, name,
*args, **kwargs)
self.action_embed_model = FullyConnectedNetwork(
spaces.Box(0, 1, shape=true_obs_shape),
action_space, action_embed_size,
model_config, name + "_action_embedding")
self.register_variables(self.action_embed_model.variables())
def forward(self, input_dict, state, seq_lens):
avail_actions = input_dict["obs"]["avail_actions"]
action_mask = input_dict["obs"]["action_mask"]
action_embedding, _ = self.action_embed_model({
"obs": input_dict["obs"]["state"]})
intent_vector = tf.expand_dims(action_embedding, 1)
action_logits = tf.reduce_sum(avail_actions * intent_vector,
axis=1)
inf_mask = tf.maximum(tf.log(action_mask), tf.float32.min)
return action_logits + inf_mask, state
def value_function(self):
return self.action_embed_model.value_function()To walk through this, we first initialize the model and pass our true_obs_shape, which is going to match the size of the state. If we stick with our reduced KP, that will be a vector with 11 entries. The other value we need to provide is the action_embed_size, which is going to be the size of our action space (5). From here, the model initializes a FullyConnectedNetwork based on the input values we provided and registers these values.
The actual masking takes place in the forward method where we unpack the mask, actions, and state from the observation dictionary provided by our environment. The state yields our action embeddings which gets combined with our mask to provide logits with the smallest value we can provide. This will get passed to a softmax output which will reduce the probability of selecting these actions to 0, effectively blocking the agent from ever taking these illegal actions.
Once we have our model in place, we need to register it with the ModelCatalog so RLlib can use it during training.
ModelCatalog.register_custom_model('kp_mask', KP0ActionMaskModel)Additionally, we need to register our custom environment to be callable with RLlib. Below, I have a little helper function called register_env which we use to wrap our create_env function and tune's register_env function. Tune needs the base class, not an instance of the environment like we get from or_gym.make(env_name) to work with. So we need to pass this to register_env using a lambda function as shown below.
def register_env(env_name, env_config={}):
env = create_env(env_name)
tune.register_env(env_name, lambda env_name: env(env_name, env_config=env_config))
register_env('Knapsack-v0', env_config=env_config)Finally, we can initialize ray, and pass the model and setup to our trainer.
ray.init(ignore_reinit_error=True)
trainer_config = {
"model": {
"custom_model": "kp_mask"
},
"env_config": env_config
}
trainer = agents.ppo.PPOTrainer(env='Knapsack-v0', config=trainer_config)To demonstrate that our constraint works, we can mask a given action by setting one of the values to 0.
env = trainer.env_creator('Knapsack-v0')
state = env.state
state['action_mask'][0] = 0We masked action 0, so we shouldn't see the agent select 0 at all.
actions = np.array([trainer.compute_action(state) for i in range(10000)])
any(actions==0)
[out]
FalseAnd there we have it! We've successfully restricted our output with a custom model in RLlib to enforce constraints. You can use this same setup with tune as well to constrain the action space and provide parametric actions.
Masks Work
Masking can work very effectively to free an agent from pernicious local minima. Here, we built a virtual machine assignment environment for or-gym where the model with masking quickly found an excellent policy, while the model without masking got stuck in a local optima. We tried a lot with the reward function first to get it out of that rut, but nothing worked until we applied a mask!
