


Introduction:
From the title, you can easily guess that I am writing this article about Web Scraping. But I am not traditionally writing this article- taking a website and teaching you the scraping using BeautifulSoup or Scrapy library. When we go through a web scraping tutorial, we can easily do those things which are taught in that tutorial, but there is one thing in which we face difficulties when we are going to scrap the web by ourselves - i.e. writing CSS selectors and the XPath. Sometimes, we are trying so many times with different sequences of CSS selector but still, we can't extract the desired text from it. Then we gave up and quit web scraping. Believe me, I know that pain😣.
In this article, we are going to learn how to write XPath and CSS selectors for extracting the desired text properly. If there is anybody who doesn't know these two things. Don't worry. At the end of this article, you have everything to start web scraping. Just keep patience and read on.
Let's start coding😎:
This article is mainly specific to the Scrapy python library, the most popular web scraping framework. The code is written here all works perfectly with Scrapy.
For demonstration purposes, I am using a sample html code which is given below.
Hey, 'Choose me!'🤗:
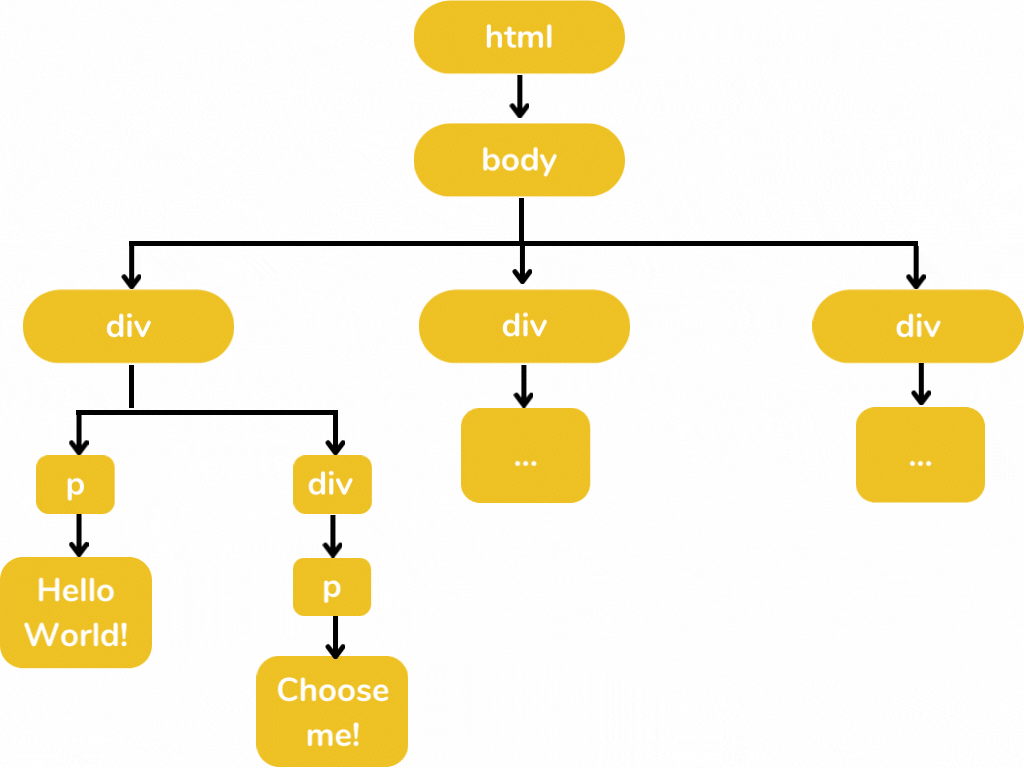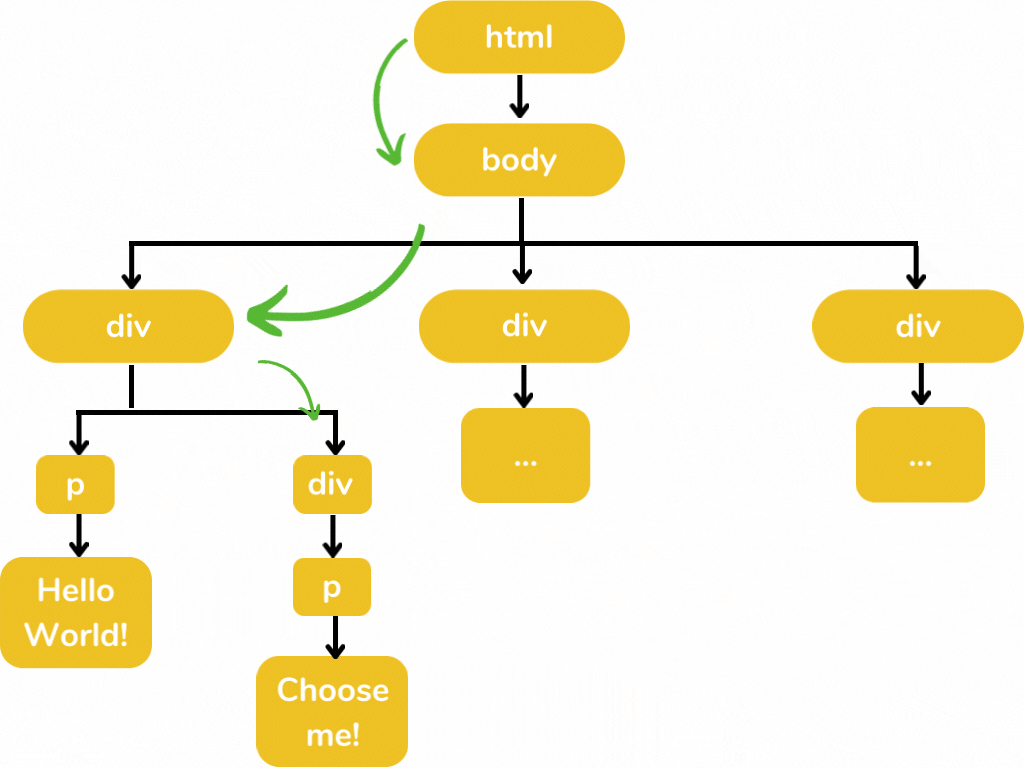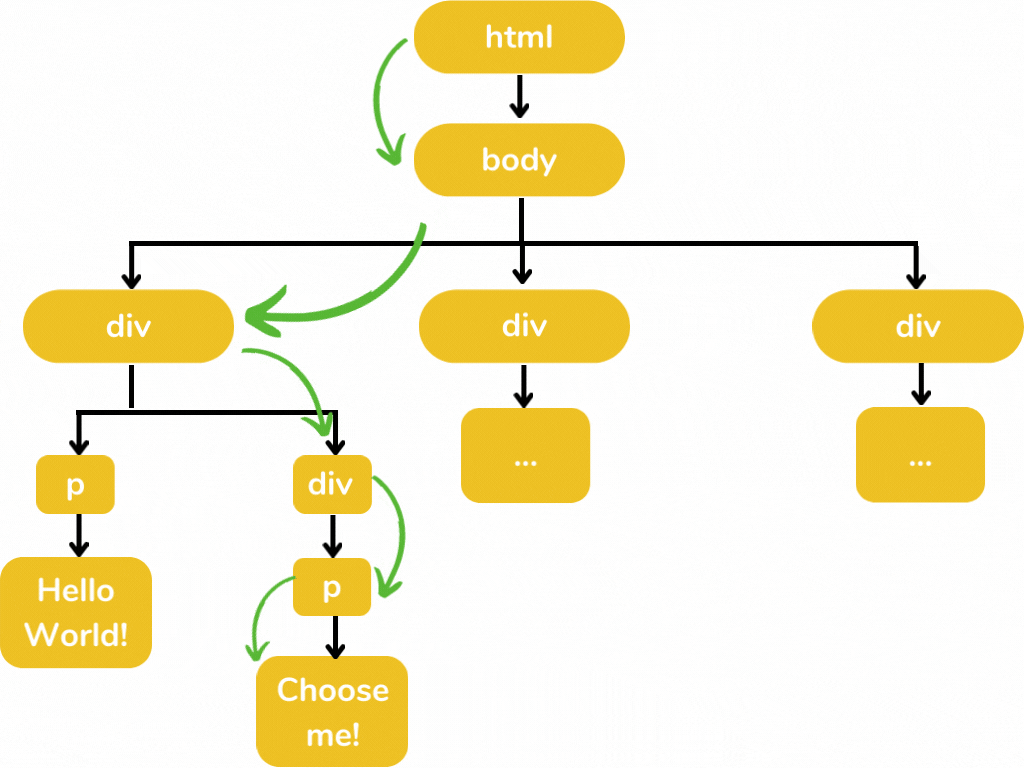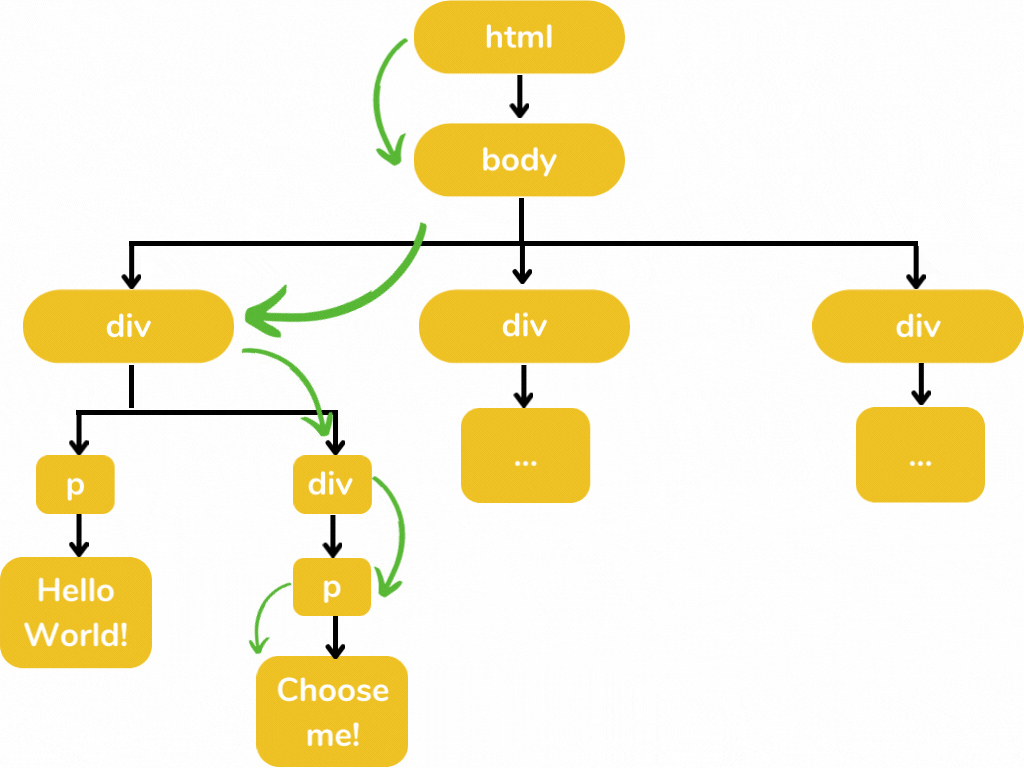
We can easily notice from the above code that there is a tree like structure. Remember when we want to import data for data analysis using Pandas, we have to tell Pandas the absolute path of that data. Just like "C://Users//data//tutorial.csv". In the same procedure we are select the specific portion of webpage using xpath and css. For example, if we want to take the "Choose me!" text from this sample code, we have to just define the xpath in that way -
Here I use Scrapy's Selector class which helps us to select the specific element from the HTML. It takes the HTML code as a string as an argument. Let's see the tree structure for this specific selection.

Here I am only displaying those elements in which we are interested. Displaying all the elements makes this illustration a little bit messy 😥. The below illustration defines how we select those elements from this tree structure.
'html/body/div/div/p'- this is the path in which we are interested. For selecting the text in the <p> element, we have to add ./text() for xpath and :: text for css.
Here we specify the XPath and CSS selector. Just one difference, in XPath we are using '/', but for CSS, we are using '>' for defining the required path. In XPath, '/' means we are selecting a single element. In CSS, for selecting a single element, we use the '>' sign. For selecting multiple elements, we use '//' for XPath and Space for CSS.
From the above code snippet, you can see that I am using multiple CSS and XPath methods from the sel object. you can write the whole path only in one method, but dividing the path and gluing them with multiple CSS and XPath methods is helpful when you have a large path.
Selecting the 3rd div and its text:
Now let's see the third div element of the body in our example HTML code.

We can easily see that there are two texts in the third div element and there is also a text inside the <a> tag. we can select the 3rd div by specifying 3 within the square bracket beside the div in XPath.
xpath = '/html/body/div[3]'For css, we have to use 'nth-of-type'.
css = 'html > body > div:nth-of-type(3)'Now we can extract text easily by adding text attribute.
Now there is one thing. If you use the above code snippet, you will get only the two texts inside the div. you don't get the text which is inside the <a> tag. Sometimes it happens that we need that text too. Just add // before text() in xpath and for css, you have to add space before text.
print(sel.xpath(xpath).xpath('.//text()').extract())
print(sel.css(css).css(' ::text()').extract())Sometimes we also want to extract href from <a> tag. For this, we have to specify paths for XPath and CSS defined below.
Selecting by classes and ids:
Sometimes selection with tags is not enough, as we can't count the position of a specific tag position on a large website. So there is a way to select the tags with their classes and ids. If you are familiar with Web Development, you will know what I mean. In Web Development, we define class and id names with the tags, which makes our life easier while selecting those tags in CSS and Javascript. Exactly for the same purpose, we are also using those class and id names in Scrapy too.
In the above code snippet, I described everything about the selection of classes and ids. Just go through the all comments written in the code snippet. I described everything in the code rather than describing it separately for better understanding.
Conclusion:
And those are everything you need to make your spider in Scrapy like a Pro. You learned about -
- Writing Xpath and CSS selector properly for scraping a website.
- Select all texts even if they are in another tag.
- Select specific HTML tags by their classes and their ids.
If you are reading this line, I just want to tell you one thing - Congratulations and Thank you for reading this article so far😇.
If you have any queries, just let me know in the comments 😁.
Further Reading
In Plain English 🚀
Thank you for being a part of the In Plain English community! Before you go:
- Be sure to clap and follow the writer ️👏️️
- Follow us: X | LinkedIn | YouTube | Discord | Newsletter
- Visit our other platforms: CoFeed | Differ
- More content at PlainEnglish.io