

At Booking.com, we are proud of our data-driven culture. A hallmark of this is our extensive use of A/B testing everywhere in the company. At any point in time, we are running about 1000 experiments in parallel on our in-house experimentation platform, which is maintained and developed by a centralized experimentation team. Experimentation is democratized: everyone can set up and run an experiment, and experimenters are responsible for the quality and the decision of the experiment. [1]
Experiments help us to make data-driven decisions to improve our products. However, these decisions are only as good as the experiments themselves. Only with high-quality experiments can we make the right product decisions, learn from the behavior of our customers, and lead our product development in the right direction. While teams are free to set up their own experiments and empowered to make decisions on those results, the experimentation platform must provide guidance on good experimentation practices. Therefore, we made experimentation quality the main KPI of our experimentation platform team. [2]
Setting up high-quality experiments can be complex: from formulating the hypothesis to selecting metrics and target segments, to ensuring sufficient statistical power. We have observed that some experimenters find this process challenging. As the team taking care of the in-house experimentation platform, we support them by running experimentation training, reaching out into the community, and changing the UX of our experimentation platform to help guide experimenters towards running high-quality experiments. But how do we know that our interventions are actually effective?
As an experimentation platform team, we often rely on qualitative feedback from experimenters. We also look at how aspects of experimentation quality develop over time and try to correlate it to our interventions. However, these approaches make it difficult to causally attribute improvements to interventions and to quantify impact reliably. When Booking.com's traveler-facing product teams want to assess the impact of their efforts, they run an A/B test. Can we do the same, and test our own interventions with randomized controlled trials? I.e. can we run experiments on the experimentation process, or "meta-experiments"?
Can we experiment on the experimentation process?
When considering running meta-experiments, we asked ourselves questions like: "What should be the randomization unit?", "Will we have enough statistical power to see improvements on our target KPI?", "Do other companies run meta-experiments?", and "Should we even experiment on our own colleagues?".
One of the main concerns was statistical power for the meta-experiment. Our usual experiments on the website or apps have millions of visitors, but for the internal experimentation platform, "only" 1000 experiments are run by "only" a few hundred teams at any given time. Can we achieve sufficient power for such small sample sizes? We know that smaller companies run A/B tests with a lot smaller traffic than we are used to, and medical studies often require less than 100 participants in total [5]. Therefore; it should be possible to run meta-experiments given tens or hundreds of experiments, or similar numbers of experimenters.
Satisfied that we should be able to test a change with the traffic on our internal platform, we set out to do what our customers (the product teams running experiments) do: run an experiment to see if a change to the experimentation platform could improve the quality of our customers' experiments. Here we will showcase the experiment we ran to test sending low-power alerts to our users.
New Feature: Low-Power Alerts
One specific aspect that experimenters struggle with is statistical power. It is a complex statistical concept, and correctly powering an experiment requires information about how decision metrics and traffic behave on the targeted audience. Since experiments can have very specific customer targets, and we have strong seasonality, it can often be difficult to get these numbers right. In addition, experimenters often struggle with deciding minimal relevant effects or non-inferiority margins, and generally prefer short over long experiment runtimes. As a consequence, some of our experiments end up underpowered.
To address the challenge of power, we designed a "low-power alert": experimenters would receive an alert when their experiment was not sufficiently powered. This alert provided an explanation of power and its business impact, as well as a link to set experiment parameters for sufficient power with one click. In the control group, experimenters did not receive such an alert. We want to measure whether this intervention increases the number of sufficiently powered experiments.
Randomizing experimenters or experiments?
To run an experiment, one has to choose the randomization unit. In the case of a meta-experiment, obvious choices are experimenters or experiments. Both have pros and cons.
Since the actors to be influenced for better experimentation are the experimenters, experimenters are a natural randomization unit. Usually experimentation is a team effort, so randomizing on experimenting product teams could be even better. However, biases can arise due to variant spillover when different product teams collaborate to run experiments, or when experimenters present experiments to each other.
In our example of the meta-experiment with low-power alerts, experimenters or experimenting teams are not a good choice of randomization unit, because our success metric is not on experimenter level. Rather, our target metric is measuring whether experiments are sufficiently powered. Since experiment metrics must always be measured on the randomization unit, experiments are our best choice for the unit of randomization. This choice gave rise to the term "meta-experiment" in order to distinguish our meta-experiment from the sample experiments within it.
A disadvantage of using experiments as the randomization unit is that they do not correspond to the actor — we require experimenters to act. When the same experimenter runs many experiments during the meta-experiment, she may be exposed to both base and variant, leading to variant spillover. In our case, we expect this bias to "amplify" the impact of our treatment (see next section).
Sufficient power for low-power alerts
When designing our meta-experiments to test the low-power alerts, we had to make sure that it was sufficiently powered. After all, it would be quite embarrassing to receive a low-power alert for our own meta-experiment where we hoped to reduce low-power experiments!
To achieve sufficient power, we chose a treatment with a potentially large effect size: We knew from user research and support questions that experimenters struggled with power, and were looking for advice and suggestions from the experimentation platform. We also quantified the past number of low-powered experiments to assess sample size, and made sure to only include low-powered experiments in our meta -experiments to avoid over-tracking [4]. Nevertheless, we had to run our meta-experiment much longer than most of our customer-facing experiments: a few months as compared to a few weeks. These longer runtimes did not only help increase sample size, but additionally made sure that most of the experiments in our sample could run to completion. In this way, we made sure that our meta-experiment had sufficient power and didn't end up part of its own sample set; that would have been too meta!
Meta-experiment results
The main success metric was whether our users' experiments were sufficiently powered. Since we only included experiments in our meta-experiment which were low-powered at alerting time, this binary metric directly measured our success. We also added as a behavioral supporting metric of whether power-related experiment settings were changed. Both metrics increased significantly. As a result, we shipped our meta-experiment, and now all low-powered experiments running on our experimentation platform receive low-power alerts.
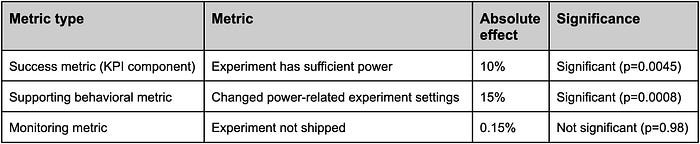
We also monitored additional metrics, such as whether an experiment was shipped. We hypothesized that in variant, experiments might ship less because experimenters could "give up" seeing that they did not have sufficient power to conclude the experiment in a reasonable amount of time. Conversely, experiments could ship more due to being better at detecting true effects. In our meta-experient, we did not detect any significant effect on this metric.
Due to spillover between variants (some experimenters ran multiple experiments during our meta-experiments), we expect some bias in our quantitative measurements. We believe that this bias "amplifies" our effects. We saw that experimenters started to rely on low-power alerts to set power and therefore might have missed power problems in experiments that were part of base. We therefore think that our quantitative success measure possibly overestimates the impact of our treatment, but that the decision to ship the meta-experiment is correct.
Experimentation dogfooding
Experimentation at Booking.com is democratized, which means that product teams run their experiments independently and self-serve on our experimentation platform. As a centralized team taking care of this platform, we have deep knowledge of experimentation, and we talk a lot to experimenters. But we generally do not run experiments ourselves. Running meta-experiments therefore provides a good "dogfooding" experience: using our own product as our customers would. Having to choose experimentation units and metrics, struggling with low sample size, interacting with our UX "for real", and being emotionally invested in the meta-experiment outcome brought home pain points that we knew from our user support and user research but had not experienced ourselves. The experience increased our empathy for our users, which will help us support them and guide future development of our experimentation platform.
Conclusion
We showed how we enhance the experimentation process through "meta-experiments"; by running experiments on experiments. Running an A/B test on our A/B testing platform enabled us to causally link our intervention to improvements in a specific aspect of the experimentation team's KPI, the number of sufficiently powered experiments. This would not have been possible via time series analysis, e.g. using the number of properly powered experiments, because other factors like experiment training or the type of experiments being run influence power. In addition, while our effect was large enough to be detectable in a proper randomized controlled trial, the effect was not clearly visible in the timeline due to too many fluctuations with the relatively low number of affected experiments over time.
Running meta-experiments comes with challenges: due to small sample sizes, long runtimes, or large effect sizes are required for sufficient power, potentially reducing the velocity of the experimentation team. Another challenge arises from biases and potential user confusion due to variant spillovers when experimenters get exposed to different variants. We therefore only conduct a few of our interventions as meta-experiments. These instances occur when we aim to move a KPI, rather than stack modernization or bug fixes. We use meta experiments when we are particularly interested in causal attribution or impact estimation. Additional criteria are that we expect large enough effect sizes to be detectable in a reasonable amount of time, and that the intervention is not confusing to experimenters should they see the treatment of different variants.
While running meta-experiments can be challenging and consumes effort and time, we believe that experimenting on the experimentation process is valuable. While our primary motivations are causal attribution and impact quantification, we also appreciate the "dogfooding" effect for the experimentation team of running their own experiments, in order to increase product knowledge and user empathy.
Acknowledgements
Meta-experiments on our experimentation platform were a team effort. Many thanks to Carolin Grahlmann and Nils Skotara for the meta-experiment design; Alberto de Murga, Chad Davis, Cyprian Mwangi, João Arruda, and Sebastian Sastoque for the meta-experiment implementation; and Sergey Alimskiy for the meta-experiment UX design, and also for the pictures in this article. Finally, thanks to Kelly Pisane and Daisy Duursma for thoroughly reviewing this article.
References
[1] S Thomke, Building a Culture of Experimentation, Harvard Business Review March–April 2020, https://hbr.org/2020/03/building-a-culture-of-experimentation
[2] C Perrin, 2021. Why we use experimentation quality as the main KPI for our experimentation platform. https://medium.com/booking-product/why-we-use-experimentation-quality-As-the-main-kpi-for-our-experimentation-platform-f4c1ce381b81
[3] JJ Riva, KM Malik, SJ Burnie, AR Endicott, JW Busse. What is your research question? An introduction to the PICOT format for clinicians. J Can Chiropr Assoc. 2012 Sep;56(3):167–71. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3430448/
[4] P Estevez, Overtracking and trigger analysis: reducing sample sizes while INCREASING the sensitivity of experiments. https://booking.ai/overtracking-and-trigger-analysis-how-to-reduce-sample-sizes-and-increase-the-sensitivity-of-71755bad0e5f
ArXiv version of this blog post:
MJI Müller, Meta-experiments: Improving experimentation through experimentation, arXiv:2406.16629, https://arxiv.org/abs/2406.16629