

Getting started aggregating data in MongoDB
MongoDB is an open-source, NoSQL database built to simplify storage of large, document-based, unstructured data. This article is the first of a 3-part series on MongoDB analytics, with the purpose of showing how to aggregate data in MongoDB and learn correct MongoDB query syntax using Knowi.
Why put data in MongoDB?
Unstructured data has become more prevalent throughout the past decade as the number of collection points have increased across most business technology stacks — with the IDC estimating that 80% of enterprise data remains unstructured.
Each new collection point provides a different lens to view an organization's health: mobile data is growing exponentially from phones & laptops across the world, while text-based information such as customer support conversations and web-page traffic provide new ways to understand the channels of communication that drive every forward-thinking business. The amount of unstructured information across business ecosystems will continue to expand dramatically throughout the 2020's.
Given the velocity and volume of data from these sources, MongoDB offers a premier, NoSQL solution to flexibly store, index, and query the proliferating mass of unstructured data. Unlike relational databases, MongoDB does not require a schema defined upfront; each data object is stored as a separate document inside a "collection". Queries on MongoDB can be executed ad-hoc to return data based on fields, ranges, or regular expression using Javascript.
Perfect for building fast-scaling apps, Mongo is simple to set-up. The rest of this article will explore how to aggregate MongoDB-based data to prepare it for downstream purposes.
How to aggregate data in MongoDB
Most organizations run queries against MongoDB using the default Javascript command line client. However, MongoDB can also be queried using Python, PHP, C#, Perl, Ruby, or MongoDB Compass GUI.
Here's an example of how to execute a query in MongoDB:
db['Collection_to_query'].find(
{},
{"metric":1,"_id":0}
).limit(10000)This will return all of the metrics associated to the 'Collection to query' specified inside MongoDB.
Aggregation is critical for processing data to return computed results. In Mongo, aggregations can be used to group values from multiple documents and perform calculations on the grouped data to return a single result. This is a vital step to prepare data for analytics, as aggregating unstructured data enables teams to find trends and correlations between data-points and prepare for downstream analytics functions.
Inside MongoDB, there are three main ways to aggregate data: the aggregation pipeline, the map-reduce function, and single purpose aggregation methods (links to MongoDB documentation provided).
MongoDB's aggregation framework is modeled on the concept of data processing pipelines. Documents enter a multi-stage pipeline that transforms the documents into an aggregated result. A few important examples include -
- $group — groups documents by specified expression & outputs to next stage by distinct grouping characterized by _id field. Outputted documents can include accumulator expressions as part of the grouping by _id field. This is expressed as:
{ $group: { _id: <expression>, <field1>: { <accumulator1> : <expression1> }, … } }- $filter — will pull a specific subset based on specified filter condition including only elements that match the condition. This is expressed as:
{ $filter: { input: <array>, as: <string>, cond: <expression> } }- $match — can be used to filter the number of documents passed between stages. Match should be used early in the aggregation pipeline. This is expressed as:
{ $match: { $expr: { <aggregation expression> } } }- $limit — limits the documents for the next stage by specified number, only passing through the amount of documents specified. This is expressed as:
{ $limit: <positive integer> }- $project — pass documents with specified fields to next stage, helping aggregate data by specific categories. This is expressed as:
{ $project: { <specification(s)> } }These aggregations can be used to drive functionality from data including building analytics visualizations, machine-learning prediction workflows, and pushing data into applications. For more specifics on different aggregation methods possible inside of MongoDB, check out their documentation page here.
Learning & Practicing MongoDB aggregations using Knowi
Knowi is an augmented analytics platform that enables teams to create queries on NoSQL databases like MongoDB, Couchbase, and Cassandra using a point & click interface. Knowi can be used to generate queries on MongoDB, and review proper syntax for aggregating data. Let's walk through an example of setting up a MongoDB aggregation in Knowi
First — head to Knowi's MongoDB Querying page. From here, you can immediately access a cloud-hosted live demo of MongoDB database, start running queries, and aggregating data using Knowi on the cloud.
Second — in the "Query Builder" section — click on Collections & choose "sendingActivity". Notice that as you changed the MongoDB collection, the native MongoDB query generator automatically built the query under the "query editor". This is a great way to learn how to write aggregations and queries in MongoDB, feel free to try the different steps with other collections hosted in the Knowi trial database or your own MongoDB data.
Third — let's run through an aggregation. Click the drop-down for "Measures and Groups" & click into the metrics box. Select "customer" and "sent" as the metrics to query. Notice that as each field is selected, the query automatically updates on the right side of the screen.
Double click the box for "Sent", in the operations box choose "Sum" and Ok. In the query-editor on the right, you can immediately see that the query has been edited with the sum aggregation included to look like. This functionality can be used to see how to write MongoDB aggregations inside Knowi
db['sendingActivity'].aggregate([ {
"$group" : {
"customer" : {
"$first" : "$customer"
},
"Sum of sent" : {
"$sum" : "$sent"
},
"_id" : null
}
}, {
"$project" : {
"customer" : 1,
"Sum of sent" : 1,
"_id" : 0
}
}, {
"$limit" : 10000
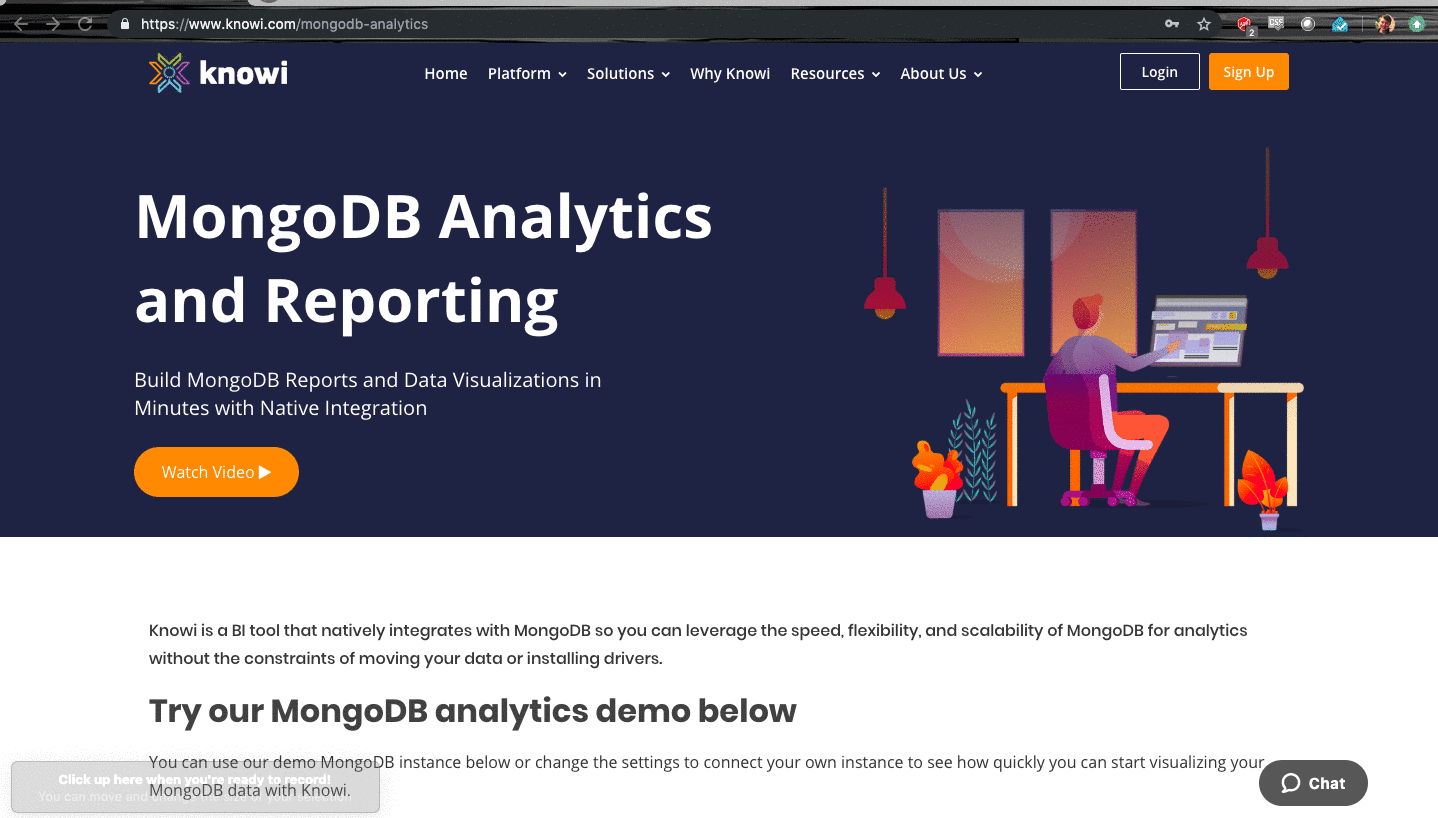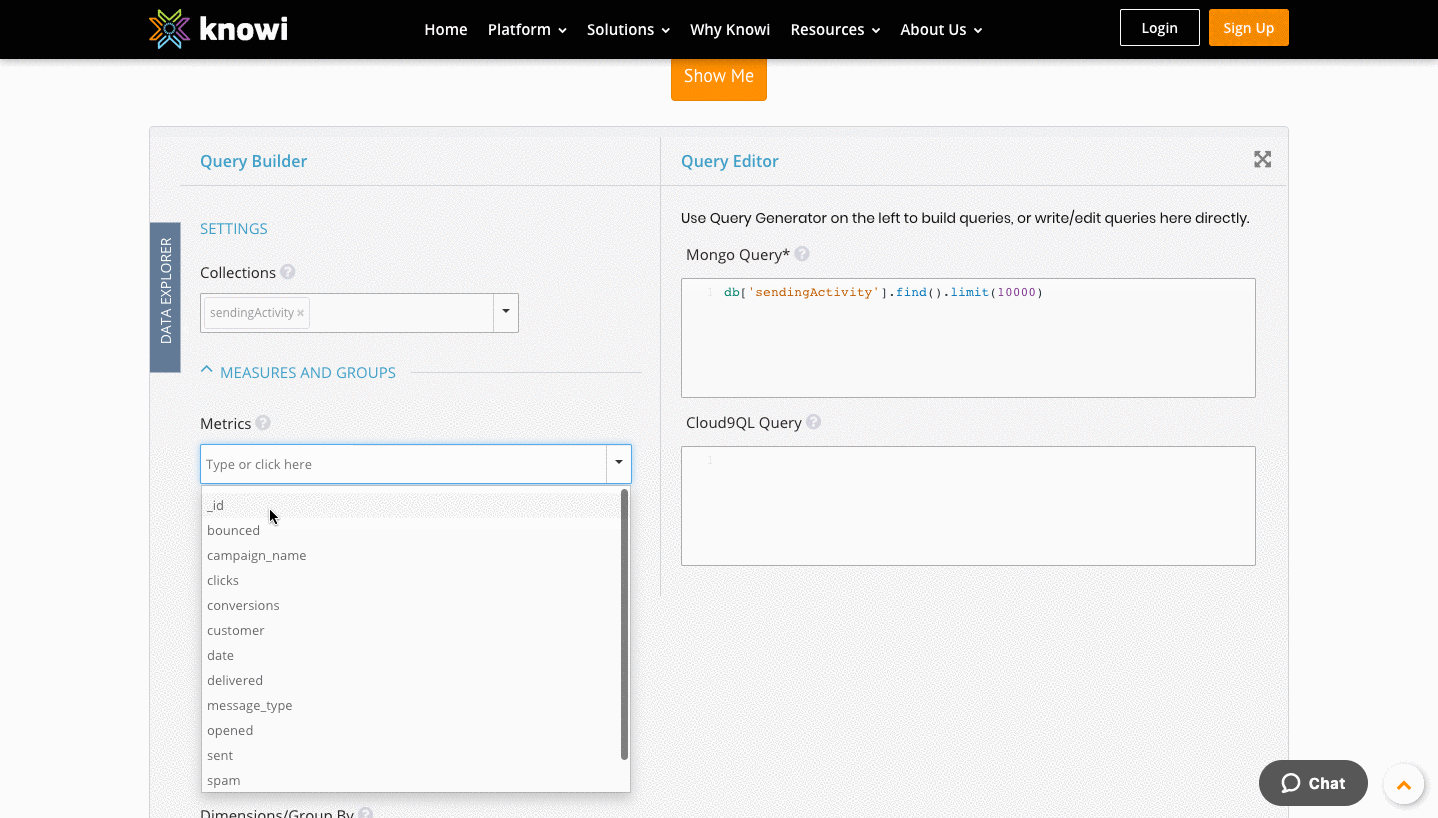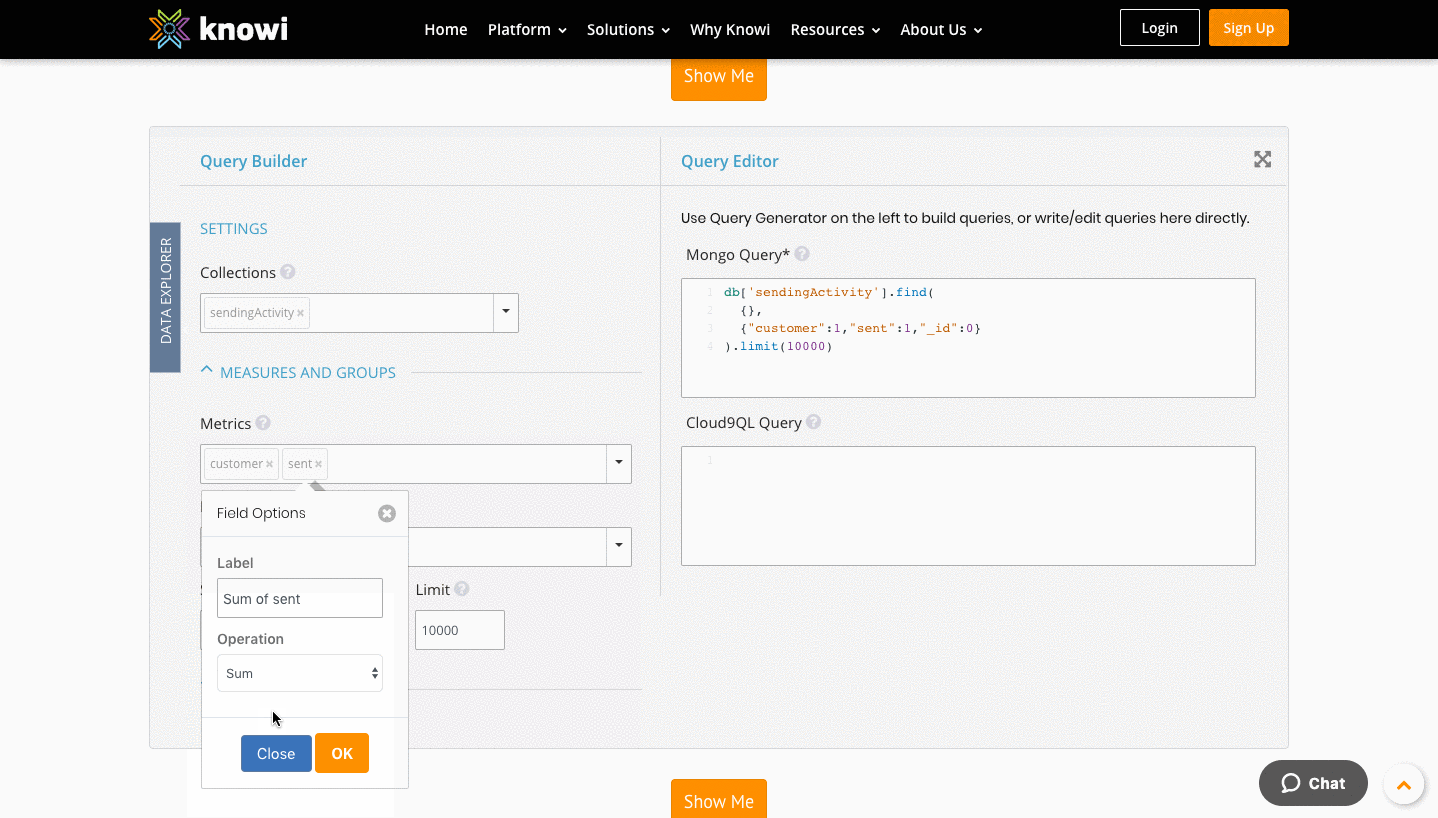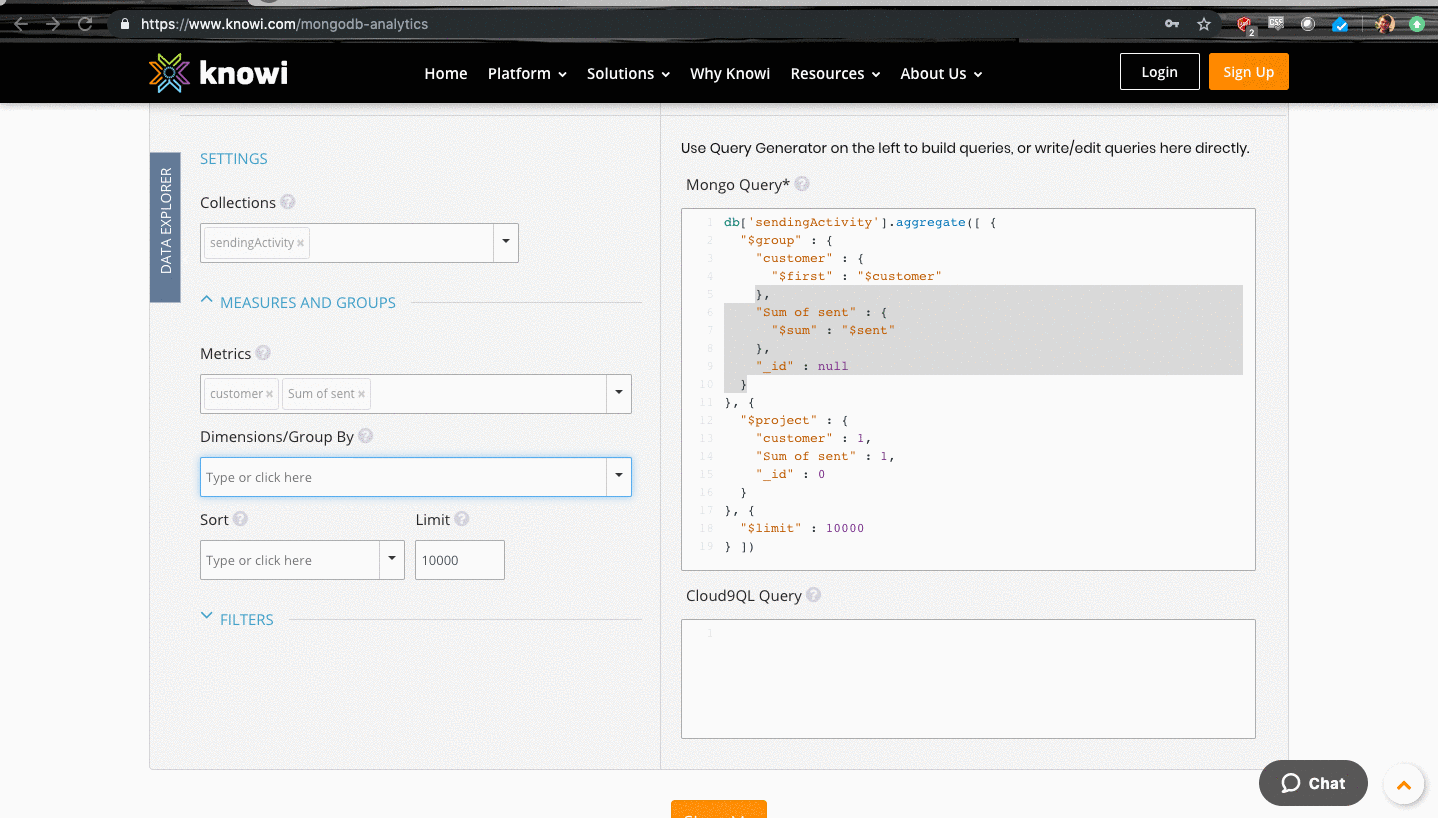
} ]Using Knowi's UI, any MongoDB novice can quickly begin writing queries to help unlock their understanding of the data available, and the best aggregations to perform on said data. Now let's try a grouping aggregation using Knowi. Press into the "Dimensions/Group By" box and select "date" — this will be immediately reflected in the query editor, where the $group sequence has been completed with date as the grouping id.
db['sendingActivity'].aggregate([ {
"$group" : {
"customer" : {
"$first" : "$customer"
},
"Sum of sent" : {
"$sum" : "$sent"
},
"_id" : {
"date" : "$date"
}
}
}, {
"$project" : {
"customer" : 1,
"date" : "$_id.date",
"Sum of sent" : 1,
"_id" : 0
}
}, {
"$limit" : 10000
} ])We've now performed two aggregations in MongoDB using Know including a summation of the number of sent messages in a Mongo collection & grouping of documents by date. The value of this will become apparent when you select "Show me", as the result of aggregations can be immediately displayed.
In the upcoming MongoDB Aggregations — Part 2, we'll explore how Knowi can help you blend collections of data in MongoDB with other sources of unstructured data like CouchBase and DataStax, as well as relational data systems like PostgreSQL or Snowflake,