

Imagine your app, handling thousands of orders per second simultaneously, suddenly crashing. Users are furious, revenue drops 30% within an hour, and your brand takes a major hit. Sounds like a disaster, right?
To prevent nightmare scenarios, it's crucial to design cloud applications that perform well under pressure. Resilience isn't about eliminating failures, as transient network issues, database hiccups, and temporary service outages are inevitable. However, with smart strategies, your application can gracefully navigate these challenges, minimizing downtime and ensuring smooth operations.
This guide explores key strategies and patterns to empower you in building resilient applications. We'll cover techniques like retry logic and circuit breakers for handling temporary issues, bulkheads for isolating failures, and proactive monitoring to identify and address potential problems. The aim is to provide your application with the strength to handle obstacles and maintain seamless operations.
By the end, you'll be equipped to build applications that never break, always adapt, and consistently deliver a seamless experience for your users.
Non-members on Medium can still explore the full story — simply click here!
What is Resilience?
Resilience simply means your application can bounce back from failures. It's not about avoiding them entirely, but about designing your system to handle them gracefully. Unlike traditional monolithic applications, cloud systems are distributed, with components working independently. Think of each component as a "worker" communicating with others. These workers need to be ready for challenges like:
- Slow connections
- Temporary service issues
- Component crashes and restarts
In the following sections, we'll explore simple strategies for both your services and cloud resources. These strategies serve as a guide to assist your system in managing problems, ensuring minimal downtime and disruptions.
Building Resilience: Your Toolbox
To enhance the resilience of your applications without creating a custom framework, consider using existing transient-fault-handling libraries like Polly, Polly-JS, Resilience4j, or others. These libraries allow developers to articulate resiliency policies clearly and in a thread-safe manner, applicable to applications built with them. Resiliency features, known as policies, can be applied individually or combined, including Retry, Circuit Breaker, Timeout, Bulkhead, Cache, and Fallback.
In the depicted scenario, these policies target request messages from external clients or back-end services, compensating for potential service unavailability during brief interruptions indicated by specific HTTP status codes (e.g., 404, 408, 429, 502, 503, and 504).
When dealing with HTTP status codes, it's essential to discern when to retry. For instance, a 403 status code (Forbidden) signals proper system functioning but unauthorized access, making retrying unnecessary.
Now, let's explore some key strategies and patterns to build resilient cloud applications:
Retry Logic
In distributed cloud environments, service calls and interactions with cloud resources may encounter transient (short-lived) failures that often self-correct after a brief duration. To address these issues, the implementation of a retry strategy proves invaluable for cloud services.
Not all failures are uniform, and transient network issues or temporary service interruptions are commonplace. By incorporating retry mechanisms, your application gains a second or third opportunity to recover, mitigating unnecessary downtime and user frustration. Picture it as granting your system a built-in "do-over" button.
For more detailed insights into implementing Retry Logic, refer to Building Self-Healing Applications with Retry Logic: A Practical Guide.
Additionally, the figure below demonstrates the Retry pattern with the Polly in action for a request operation. This configuration allows up to four retries, initiating with a two-second wait time that doubles with each subsequent attempt.
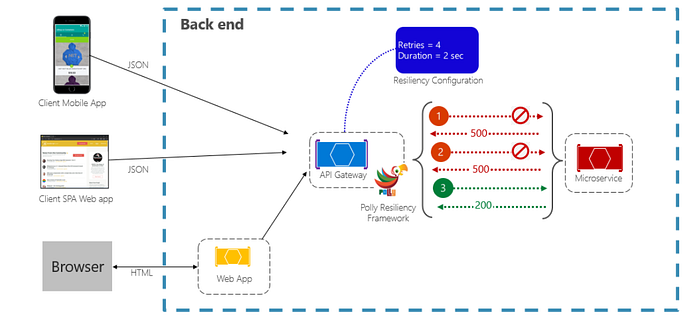
- The first attempt encounters failure with an HTTP status code of 500. Following a two-second wait, the system initiates a retry.
- The second attempt also fails, triggering a four-second wait before reattempting.
- The third attempt succeeds, concluding the retry cycle.
This setup permits four retry attempts, each with an incremented wait time, ensuring an effective and graceful approach. In the event of a fourth retry failure, a fallback policy comes into play. Increasing the backoff period between retries provides the service with sufficient time for self-correction, underlining the importance of an exponentially increasing backoff for optimal correction time.
Circuit Breaker Pattern
When faced with partial failures, retrying a request is a common strategy. However, continuous retries on a non-responsive service in situations of persistent issues, like partial connection loss or complete service failure, can be counterproductive. It may lead to resource overload and even denial of service. In such cases, it's more effective for the operation to fail immediately, with an attempt at service invocation only if success is highly likely.
The Circuit Breaker pattern plays a crucial role in enhancing application resilience. It prevents repeated attempts at an operation that is likely to fail. After a predetermined number of failed calls, it imposes a hold on all traffic to the service. Periodically, it allows a trial call to check if the fault has been resolved. In the figure below, you can observe the Circuit Breaker pattern in action, leveraging the Polly transient-fault-handling library. After 100 failed requests, it stops further calls to the service.
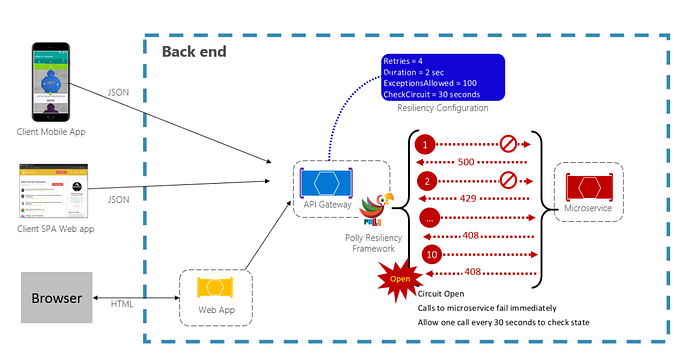
The CheckCircuit value, set at 30 seconds, determines how often the library permits a request to go through. If the call succeeds, the circuit closes, and the service becomes available again.
It's essential to distinguish the Circuit Breaker pattern from the Retry pattern. While the Retry pattern aims to retry an operation expecting success, the Circuit Breaker pattern prevents an application from attempting an operation likely to fail. Typically, applications use both patterns, employing the Retry pattern to invoke an operation through a circuit break.
For a deeper understanding of the Circuit Breaker pattern and to fortify your application's resilience, refer to Circuit Breaker Pattern in C#: Enhancing Cloud Application Resilience.
Bulkhead Pattern
The Bulkhead pattern stands as a crucial element in fortifying the resilience of your software systems. Picture your system as a ship navigating through the unpredictable waters of potential failures. Now, envision the Bulkhead pattern as a mechanism that divides your application into different sections, akin to separate rooms on a ship. The significance lies in the fact that if one section encounters a problem, it won't lead to a catastrophic failure of the entire application.
By segregating your system into isolated groups, the Bulkhead pattern ensures that if one group faces an issue, it won't propagate into a system-wide failure. Think of it as having partitions that can contain and isolate issues, similar to how a leak in one compartment of a ship doesn't sink the entire vessel.
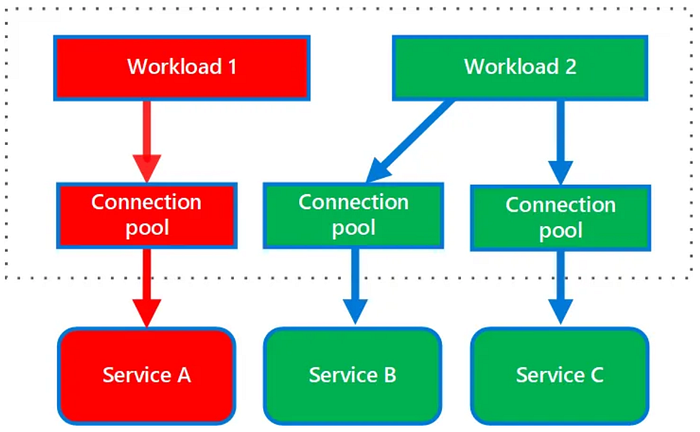
Delve into the intricacies of the Bulkhead Pattern and gain a more in-depth understanding by exploring the details provided in the article "Understanding the Bulkhead Pattern for Robust Software Systems in C#."
Cache Pattern
The Cache pattern stands as a cornerstone for resilient cloud applications, adeptly addressing challenges like service unavailability and latency by automatically storing responses. Through strategic caching of frequently accessed data, this pattern ensures swift access even amidst disruptions, significantly optimizing data retrieval processes and reducing dependencies on real-time availability. In the architectural landscape, cloud services seamlessly integrate distributed caching systems such as Redis or Memcached. These in-memory data stores play a pivotal role, facilitating rapid and efficient access to cached information, thereby elevating the overall performance of the system. Whether leveraging Redis, Memcached, or analogous caching services, the Cache pattern actively fortifies resilience in cloud architectures, effectively mitigating the impact of disruptions and guaranteeing reliable access to critical data.
Fallback Pattern
In the cloud environment, Fallback mechanisms act as indispensable safety measures during service failures, ensuring uninterrupted functionality. Deploying redundant service instances across zones, employing dynamic load balancing, leveraging caching for expeditious data access, selectively degrading non-essential features, implementing automatic failover to backups, dynamically redirecting traffic through intelligent routing, and bolstering the system with robust monitoring and automated alerts — these specific strategies collectively augment system resilience. They empower the system to adapt seamlessly, maintaining essential operations even when faced with disruptions, thus fortifying the overall resilience of the system.
Timeout Pattern
The Timeout pattern is crucial for enhancing system resilience in distributed environments. Its primary role is to prevent prolonged waits for unresponsive services, ensuring swift identification and response to situations where a service or operation becomes non-responsive. By setting specific time limits for service responses, incorporating retry mechanisms, and implementing fallback strategies, the Timeout pattern guarantees an adaptive and responsive system behavior. This is especially important in scenarios such as e-commerce platforms, where timely responses are essential for maintaining a seamless user experience. In essence, the Timeout pattern helps prevent resource bottlenecks and averts cascading failures, contributing to the overall robustness of the system.
Code Example
The provided sample code introduces the essential resilience patterns using the Polly and C# language.
using Polly;
using System;
using System.Net.Http;
using System.Threading.Tasks;
class Program
{
static void Main()
{
// Define HttpClient for making HTTP requests
var httpClient = new HttpClient();
// Timeout Pattern
var timeoutPolicy = Policy
.Timeout(30)
.Handle<TimeoutException>();
// Retry Pattern
var retryPolicy = Policy
.Handle<HttpRequestException>()
.WaitAndRetryAsync(3, retryAttempt =>
{
if (retryAttempt == 1)
{
Console.WriteLine("Retrying request once due to network issue.");
}
else if (retryAttempt == 2)
{
Console.WriteLine("Retrying request again with longer delay.");
return TimeSpan.FromSeconds(5); // Jitter
}
});
// Circuit Breaker Pattern
var circuitBreakerPolicy = Policy
.Handle<HttpRequestException>()
.CircuitBreakerAsync(3, TimeSpan.FromSeconds(30),
onBreak: ex => Console.WriteLine("Circuit breaker open due to repeated failures."),
onReset: () => Console.WriteLine("Circuit breaker reset, accepting requests again."));
// Fallback Pattern
var fallbackPolicy = Policy
.Handle<HttpRequestException>()
.FallbackAsync(async ctx =>
{
Console.WriteLine("Fallback: Unable to retrieve real-time flight information.");
var cachedFlights = await GetCachedFlights(ctx.OperationKey); // User-specific cached data
if (cachedFlights != null)
{
Console.WriteLine("Displaying cached flights for your search.");
await ShowFlightsAsync(cachedFlights);
}
else
{
Console.WriteLine("No cached data available. Please try again later.");
}
});
// Bulkhead Pattern
var bulkheadPolicy = Policy
.BulkheadAsync(2, 10, queueLimit: 5,
onQueueOverflow: ex => Console.WriteLine("Queue full, request waiting."));
// Execute the operation with chained policies
timeoutPolicy.ExecuteAsync(() =>
{
retryPolicy.ExecuteAsync(() =>
{
circuitBreakerPolicy.ExecuteAsync(() =>
{
fallbackPolicy.ExecuteAsync(() =>
{
bulkheadPolicy.ExecuteAsync(async () =>
{
// Simulate making an HTTP request to the flight availability API
var response = await httpClient.GetAsync("https://flight-api/api/availability");
if (response.IsSuccessStatusCode)
{
// Actual flight booking logic would go here
var flight = await ProcessFlightResponse(response);
Console.WriteLine($"Flight booked successfully: {flight.Destination}, {flight.Date}");
}
});
});
});
});
});
Console.WriteLine("Press any key to exit.");
Console.ReadKey();
}
// Additional helper methods for cached data and flight processing
private static Task<List<Flight>> GetCachedFlights(string key)
{
// Implement logic to retrieve cached flights based on key (e.g., user search criteria)
}
private static Task ShowFlightsAsync(List<Flight> flights)
{
// Implement logic to display cached flights to the user
}
private static Task<Flight> ProcessFlightResponse(HttpResponseMessage response)
{
// Implement logic to parse response and return a Flight object
}
// Class definitions for Flight and other relevant data structures
}Testing and Monitoring
Testing and monitoring are vital for ensuring the resilience of cloud applications. To enhance testing, use fault injection for thorough validation of system resilience. Embrace Chaos Engineering with tools like Chaos-monkey for proactive assessment of system robustness.
Effective monitoring, using services like Azure Monitor and AWS CloudWatch, swiftly detects and understands failure causes. Implement best practices in application logging, including essential operations like retries, for continuous vigilance over application health.
Introducing Chaos-monkey alongside testing and monitoring ensures comprehensive resilience testing. This approach ensures cloud applications are resilient and well-prepared for unexpected challenges in production.
Resilience is Not Just a Feature, a Necessity
Building resilient cloud applications requires a combination of strategies, patterns, testing, and monitoring. This investment ensures a system that adapts and thrives in the dynamic world of cloud computing. Remember, resilience is not just a bonus, it's a fundamental characteristic of successful cloud applications.
Want to learn more? Explore the resources below to dive deeper into each resilience pattern and start building your robust cloud applications!
- Architecting Cloud-Native .Net Apps for Azure — Microsoft
- Retry Pattern
- Bulkhead Pattern
- Chaos-monkey
- What is Chaos Engineering?