From utf8 to utf8mb4 in MySQL 5.7 with Django
Didn't know that MySQL 5.7 defaults to a 3-byte limit on UTF-8 characters? Me neither. But it does, and it's a problem if you're using MySQL. This post will show you how to automate migrating your database from utf8 to utf8mb4, in a way that doesn't break your Django app.
Why is this a problem?
I won't go into the nitty-gritty details but the short version is:
- MySQL's utf8 encoding isn't UTF-8 so when a user tries to save a 4-byte character, like an emoji 🙃, you'll start getting errors like this:
django.db.utils.OperationalError: (1366, "Incorrect string value: '\\xF0\\x9F\\x99\\x83' for column 'name' at row 1")2. MySQL 5.7 reaches end-of-life in October of 2023 and its default encoding is utf8, whereas MySQL 8, the default encoding is now utf8mb4. So eventually you'll want to migrate to utf8mb4 anyway — or have a bunch of mismatched character sets across tables.
If you're interested in the why, these two articles do a great job:
- An in depth DBA's guide to migrating a MySQL database from the `utf8` to the `utf8mb4` charset
- How to support full Unicode in MySQL databases
How to fix it?
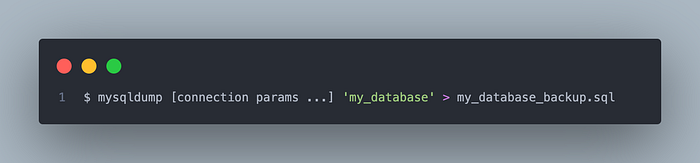
Step 1: Safety first Create a backup using the awesome django-dbbackup app or with mysqldump like so:
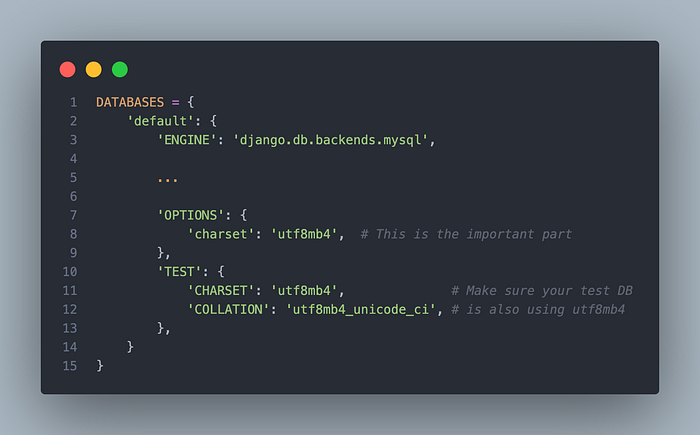
Step 2: Update your Django settings If you haven't already done so, in your settings.py make sure you're using utf8mb4 as the default encoding. This tells the MySQL server that your app will be sending it utf8mb4 encoded data (instead of the utf8 default).
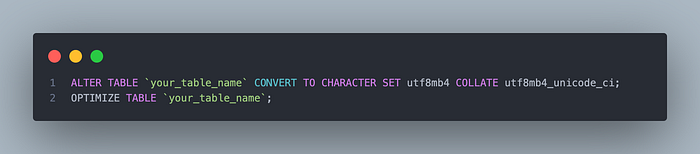
Step 3: Update your database, tables, and columns to use utf8mb4 Historically, this was where things became a bit tedious. Before MySQL 5.7, you would need to create custom statements for all text-based columns and indexes based on their data type and max length as described here.
Fortunately, as of MySQL 5.7 things are a bit easier and I've included a handy script that will do this for you below. Here's how it works:
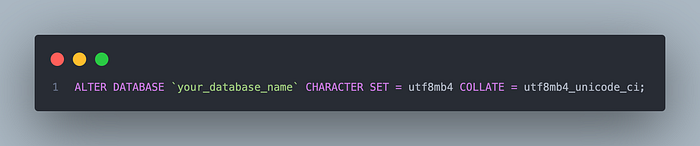
First, it changes the default character set and collation for the database to utf8mb4 and utf8mb4_unicode_ci, respectively. This tells the database that it should use utf8mb4 as the default encoding for all new tables.
Next, it changes the default character set and collation for all existing tables and then runs ANALYZE + RECREATE on each. The former will automatically apply the character set and collation to all existing tables and text-based columns/indexes — resizing as needed — while the latter is just good practice.