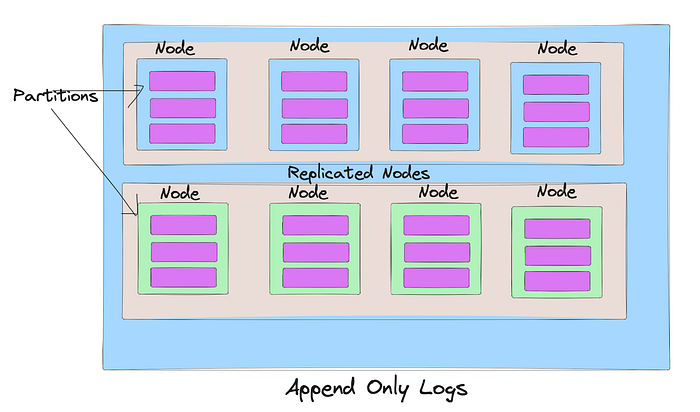

A distributed commit log is a system designed to handle the storage, replication, and dissemination of records (log entries) across multiple servers or nodes within a network.
It's a fundamental component in distributed systems and databases, ensuring high availability, durability, and fault tolerance.
Here's a breakdown of its key aspects:
Core Principles
- Immutability: Entries in the commit log are immutable once written. This simplifies replication, data recovery, and consistency checks, as logs can be replayed to rebuild state.
- Append-only: New records are always appended at the end of the log. This ensures efficient writes and straightforward replication across nodes.
- Sequential Access: Logs are designed for sequential access, making reads and writes efficient, especially for use cases that naturally fit a time-ordered sequence.
Functionality
- Replication: The log is replicated across several nodes to ensure data availability even in the face of hardware failures or network partitions.
- Consistency: It helps in achieving consistency across distributed systems through consensus algorithms (like Raft or Paxos) that ensure all copies of the log agree on the sequence of records.
- Fault Tolerance: By distributing the log across multiple nodes, the system can handle failures without losing data. Failed nodes can catch up with the rest of the system by replaying the log entries they missed during downtime.
Use Cases
- Messaging and Stream Processing: Platforms like Apache Kafka use a distributed commit log to provide a durable messaging system that supports high-throughput, fault-tolerant stream processing.
- Database Replication: Distributed databases use commit logs to replicate data across nodes, ensuring all nodes have an up-to-date copy of the database.
- Event Sourcing: Systems designed around event sourcing use commit logs to store state changes as a sequence of events, allowing them to rebuild state by replaying the log.
Advantages
- Scalability: Easily scales out by adding more nodes, as the log can be partitioned across the cluster.
- Durability: Ensures data is not lost, even in case of system failures.
- Performance: Optimized for high-throughput and low-latency write operations.
Challenges
- Complexity in Management: Managing a distributed system, especially handling network partitions and node failures, can be complex.
- Data Consistency: Ensuring strict data consistency across distributed nodes can introduce overhead and complexity.
How Kafka Uses Distributed Commit Log
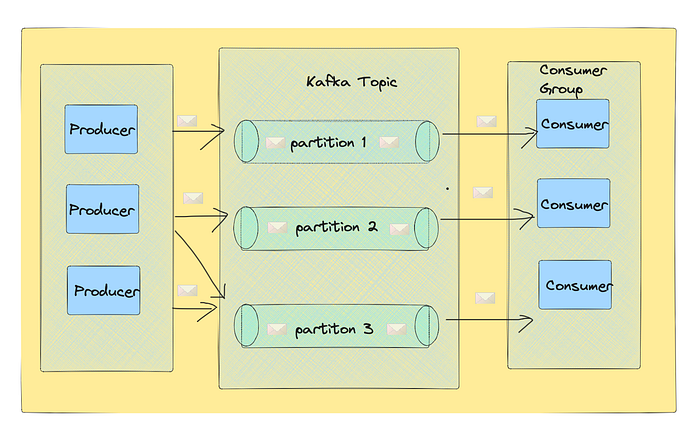
- Partitioning: Kafka topics are divided into partitions. Each partition is an ordered, immutable sequence of messages continually appended to — a commit log. Partitions allow Kafka to scale horizontally, distributing the load across multiple servers.
- Replication: Each partition is replicated across a configurable number of servers for fault tolerance. Kafka ensures that all replicas of a partition contain the same data, making the commit log durable against node failures.
- Producers and Consumers: Producers write data to topics. Kafka stores these records in the order they are received, within partitions. Consumers read messages from topics and can process data in real-time. The commit log nature allows consumers to replay messages from a specific point in time, facilitating event sourcing patterns and data recovery.
- High Throughput and Performance: By leveraging the sequential disk I/O patterns for writes and reads (thanks to the append-only log), Kafka achieves high throughput and performance, even with very large volumes of data.
- Fault Tolerance and Durability: The distributed nature of Kafka's commit log, combined with data replication, ensures that messages are not lost and can be accessed even if some brokers in the cluster fail.
Summary:
- Entries in the commit log are immutable once written.
- New records are always appended at the end of the log.
- Logs are designed for sequential access, making reads and writes efficient
- The log is replicated across several nodes
- By distributing the log across multiple nodes, the system can handle failures without losing data
- Optimized for high-throughput and low-latency write operations.
Thanks for reading my content and thanks a for being such a lovely reader.
Please consider supporting me if you want me to continue creating such content.
