


Through this article, you will learn how to improve the performance of MySQL databases through compiler optimization without modifying any lines of code.
This type of compiler optimization is known as Profile Guided Optimization (PGO).
According to the author's tests, performance can typically be improved by 30% to 50%.
However, before performing compiler optimization, it is important to ensure that routine database tuning has been completed; otherwise, the optimization provided by PGO may be meaningless.
One of the common compiler optimizations done before PGO is branch prediction optimization. By informing the compiler about the branch the code is more likely to take, program efficiency can be improved. For example, in the MySQL source code, we can see code like this:
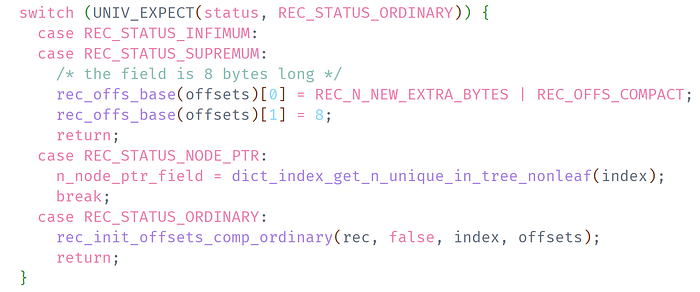
The above code snippet is used to determine that the variable `status` is most likely to have the value `REC_STATUS_ORDINARY`. Therefore, during the compilation phase, the compiler optimizes the code snippet to allow the CPU to execute it in advance, thereby improving efficiency. The macro `UNIV_EXPECT` is a wrapper for the branch prediction function `__builtin_expect` provided by GCC.

In addition to the `__builtin_expect` function, GCC also provides the branch prefetch function `__builtin_prefetch` for data prefetching. Once the prediction is correct, the performance of the program can be effectively improved. However, branch prediction optimization has several problems:
- It requires modifying the source code, and only experienced programmers can write reliable code.
- The written branch predictions may differ from the actual business operation, leading to the loss of performance improvement potential and even catastrophic consequences.
To address these two issues, Profile Guided Optimization (PGO) can be used as a more general compiler optimization technique to improve the efficiency of program execution.
In simple terms, PGO generates a profile based on the actual runtime behavior of the program. During the next compilation, this profile is used to generate code that better reflects the real runtime behavior and is more efficient.
PGO optimization involves two compilation passes and three stages:
- Sampling compilation: The first compilation pass inserts instructions into the code to collect data for the next stage.
- Training: The program is executed to collect data and generate a profile file.
- Optimization: The second compilation pass uses the profile file generated from the actual program execution to optimize the code.
PGO optimization is not only effective for database programs but also a general optimization technique applicable to any program. Common programming languages like C++ and Rust also support PGO optimization.
Using PGO optimization in C++ code is relatively simple and straightforward. The `-fprofile-generate` flag is used for sampling compilation, and the `-fprofile-use` flag is used for optimization compilation. For example:
# Sampling compilation
g++ -o test test.cpp -fprofile-generate=/tmp/pgo
# Training
./test
# Optimization
g++ -o test test.cpp -fprofile-use=/tmp/pgoDue to MySQL being written in C++, it's evidently possible to utilize PGO optimization.
Starting from MySQL version 8.0.19, MySQL's cmake file supports PGO optimization.
Interested readers can review the source code: fprofile.cmake.
Therefore, to perform sampling compilation on MySQL, you can add the parameter FPROFILE_GENERATE:
cmake .. -DFPROFILE_GENERATE=ONNext, run the sampled compilation binary program mysqld and execute the sysbench program to test the read-only performance of queries:
[ 16s ] thds: 16 tps: 63718.66 qps: 63718.66 (r/w/o: 63718.66/0.00/0.00) lat (ms,95%): 0.39 err/s: 0.00 reconn/s: 0.00
[ 17s ] thds: 16 tps: 65274.25 qps: 65274.25 (r/w/o: 65274.25/0.00/0.00) lat (ms,95%): 0.34 err/s: 0.00 reconn/s: 0.00
[ 18s ] thds: 16 tps: 65445.32 qps: 65445.32 (r/w/o: 65445.32/0.00/0.00) lat (ms,95%): 0.31 err/s: 0.00 reconn/s: 0.00
[ 19s ] thds: 16 tps: 65178.78 qps: 65178.78 (r/w/o: 65178.78/0.00/0.00) lat (ms,95%): 0.32 err/s: 0.00 reconn/s: 0.00At this point, you will notice that the QPS (Queries Per Second) of MySQL is only around 65,000.
This performance seems quite poor for a 16-core cloud host. However, it's okay because at this stage, various states of the MySQL database runtime are being collected.
So, if you observe the xxx-profile-data folder where the binary file is located, you will find many profile files ending with gcda.
$ ls build_release-profile-data
#data#Projects#mysql-server#build_release#CMakeFiles#lz4_lib.dir#extra#lz4#lz4-1.9.4#lib#lz4.c.gcda
#data#Projects#mysql-server#build_release#CMakeFiles#lz4_lib.dir#extra#lz4#lz4-1.9.4#lib#lz4frame.c.gcda
#data#Projects#mysql-server#build_release#CMakeFiles#lz4_lib.dir#extra#lz4#lz4-1.9.4#lib#lz4hc.c.gcda
#data#Projects#mysql-server#build_release#CMakeFiles#lz4_lib.dir#extra#lz4#lz4-1.9.4#lib#xxhash.c.gcda
......Next, stop the mysqld program, and recompile MySQL using the following command:
cmake .. -DFPROFILE_USE=ONBy specifying FPROFILE_USE=ON, MySQL will automatically perform compiler optimizations based on the various profile files in the xxx-profile-data folder during the recompilation process.
The resulting mysqld program will be an optimized version tailored to the sysbench test mentioned above.
Therefore, after the optimization compilation, restart the optimized mysqld program and perform the same sysbench performance test again.
[ 20s ] thds: 16 tps: 367278.48 qps: 367278.48 (r/w/o: 367278.48/0.00/0.00) lat (ms,95%): 0.08 err/s: 0.00 reconn/s: 0.00
[ 21s ] thds: 16 tps: 352094.84 qps: 352094.84 (r/w/o: 352094.84/0.00/0.00) lat (ms,95%): 0.08 err/s: 0.00 reconn/s: 0.00
[ 22s ] thds: 16 tps: 356563.23 qps: 356563.23 (r/w/o: 356563.23/0.00/0.00) lat (ms,95%): 0.08 err/s: 0.00 reconn/s: 0.00
[ 23s ] thds: 16 tps: 356433.08 qps: 356433.08 (r/w/o: 356433.08/0.00/0.00) lat (ms,95%): 0.08 err/s: 0.00 reconn/s: 0.00At this point, the performance result of sysbench is 35.5W, showing a significant improvement compared to before.
However, if PGO optimization is not used, the performance of the original MySQL database is as follows:
[ 20s ] thds: 16 tps: 255977.76 qps: 255977.76 (r/w/o: 255977.76/0.00/0.00) lat (ms,95%): 0.07 err/s: 0.00 reconn/s: 0.00
[ 21s ] thds: 16 tps: 256667.17 qps: 256667.17 (r/w/o: 256667.17/0.00/0.00) lat (ms,95%): 0.07 err/s: 0.00 reconn/s: 0.00
[ 22s ] thds: 16 tps: 246995.82 qps: 246995.82 (r/w/o: 246995.82/0.00/0.00) lat (ms,95%): 0.08 err/s: 0.00 reconn/s: 0.00
[ 23s ] thds: 16 tps: 237734.88 qps: 237734.88 (r/w/o: 237734.88/0.00/0.00) lat (ms,95%): 0.12 err/s: 0.00 reconn/s: 0.00As you can see, the original MySQL only has about 25W QPS.
In simple terms, with PGO optimization, the performance is improved by over 40%.
Conclusion
The effect of PGO optimization is quite impressive, but like everything else, it has its pros and cons.
The biggest issue with PGO optimization is its fixed scenario. In other words, PGO is a scenario feedback-based optimization. If your scenario includes both TP queries and AP queries, and various business operations are running on them, with a diverse set of scenarios, then the optimization effect may not be particularly good. However, if you can clearly construct the logic of your business, including the distribution of reads and writes, and the size of transactions, then PGO optimization will be very prominent. As we saw earlier, this could result in a performance improvement of 30% to 50%.
In today's microservices architecture, it is becoming increasingly possible to clearly outline the core business logic, especially concerning database access. Therefore, the author highly recommends using PGO, the most fundamental compiler optimization, as a means to squeeze out the last drop of performance from databases.
Lastly, don't forget that PGO can benefit not only databases but also other programs. So, why not give it a try?