

Introduction
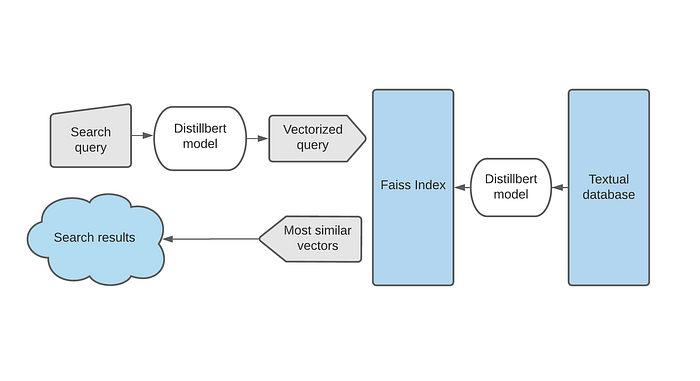
Semantic search is an information retrieval system that focuses on the meaning of the sentences rather than the conventional keyword matching. Even though there are many text embeddings that can be used for this purpose, scaling this up to build low latency APIs that can fetch data from a huge collection of data is something that is seldom discussed. In this article, I will discuss how we can implement a minimal semantic search engine using SOTA sentence embeddings (sentence transformer) and FAISS.
Sentence transformers
It is a framework or set of models that give dense vector representations of sentences or paragraphs. These models are transformer networks(BERT, RoBERTa, etc.) which are fine-tuned specifically for the task of Semantic textual similarity as the BERT doesn't perform well out of the box for these tasks. Given below is the performance of different models in the STS benchmark

We can see that the Sentence transformer models outperform the other models by a large margin.
But if you look at the leaderboard by papers with code and GLUE, you would see many models above 90. So why do we need Sentence transformers?.
Well, In those models, the semantic Textual similarity is considered as a regression task. This means whenever we need to calculate the similarity score between two sentences, we need to pass them together into the model and the model outputs the numerical score between them. While this works well for the benchmarking test, it scales badly for a real-life use case, and here are the reasons.
- When you need to search over say 10 k documents, you would need to perform 10k separate inference computations, its not possible to compute the embeddings separately and calculate just the cosine similarity. See the author's explanation.
- The maximum sequence length (The total number of words/tokens the model can take at one pass) is shared between two documents, which causes the representations to be diluted due to chunking
FAISS
Faiss is a C++ based library built by Facebook AI with a complete wrapper in python, to index vectorized data and to perform efficient searches on them. Faiss offers different indexes based on the following factors
- search time
- search quality
- memory used per index vector
- training time
- need for external data for unsupervised training
So choosing the right index will be a trade-off between these factors.
Loading the model and performing the inference on the dataset
First, let us install and load the required libraries
!pip install faiss-cpu
!pip install -U sentence-transformers
import numpy as np
import torch
import os
import pandas as pd
import faiss
import time
from sentence_transformers import SentenceTransformerLoading the dataset with a million datapoints
I used a dataset from Kaggle that contains news headlines published over a period of seventeen years.
df=pd.read_csv("abcnews-date-text.csv")
data=df.headline_text.to_list()Loading the pre-trained model and performing the inference
model = SentenceTransformer('distilbert-base-nli-mean-tokens')
encoded_data = model.encode(data)Indexing the dataset
We can choose different indexing options based on our use case by referring to the guide.
Let's define the index and add data to it
index = faiss.IndexIDMap(faiss.IndexFlatIP(768))
index.add_with_ids(encoded_data, np.array(range(0, len(data))))Serializing the index
faiss.write_index(index, 'abc_news')The serialized index can be then exported into any machine for hosting the search engine
Deserializing the index
index = faiss.read_index('abc_news')Performing the semantic similarity search
Let us first build a wrapper function for search
def search(query):
t=time.time()
query_vector = model.encode([query])
k = 5
top_k = index.search(query_vector, k)
print('totaltime: {}'.format(time.time()-t))
return [data[_id] for _id in top_k[1].tolist()[0]]performing the search
query=str(input())
results=search(query)
print('results :')
for result in results:
print('\t',result)Results on CPU
Now let's take a look at the search results and response time

1.5 seconds is all it takes to perform an intelligent meaning-based search on a dataset of million text documents with just the CPU backend.
Results on GPU
First, let's uninstall the CPU version of Faiss and reinstall the GPU version
!pip uninstall faiss-cpu
!pip install faiss-gpuThen follow the same procedure, but at the end move the index to GPU.
res = faiss.StandardGpuResources()
gpu_index = faiss.index_cpu_to_gpu(res, 0, index)Now let's place this inside the search function and perform the search with the GPU.
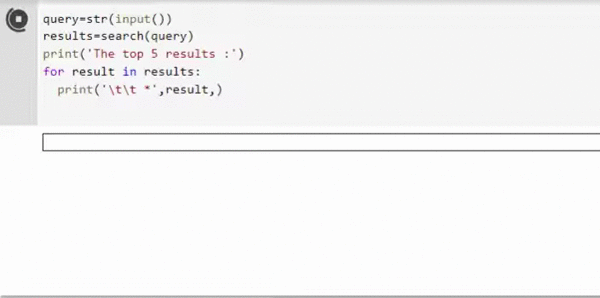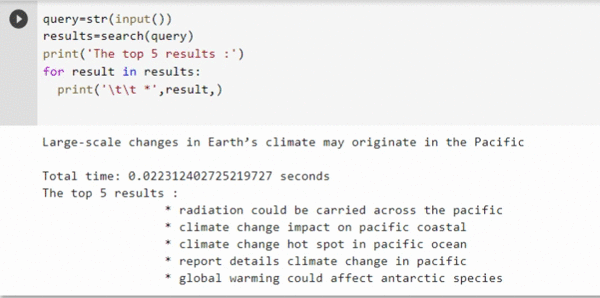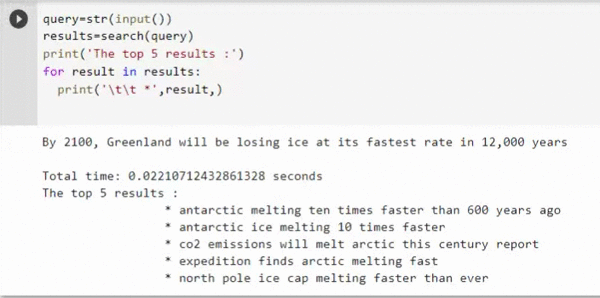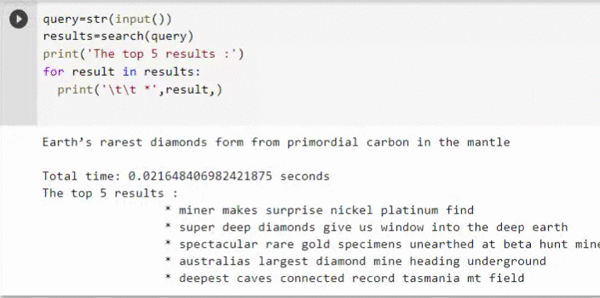
That's right, you can get the results within 0.02 sec with a GPU ( Tesla T4 is used in this experiment) which is 75 times faster than a CPU backend
Final Thoughts
This is a basic implementation and a lot needs to be still done both on the language model part and the indexing part. There are different indexing options from which the right one should be chosen based on the use case, size of the data and the compute power available. Also, the sentence embedding used here is just fine-tuned on some public datasets, fine-tuning them on the domain-specific dataset would improve the embeddings and hence the search results.
References
[1] Reimers, N. and Gurevych, I. (2019). Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv preprint arXiv:1908.10084 [cs.CL]. https://doi.org/10.48550/arXiv.1908.10084
[2]Johnson, Jeff and Douze, Matthijs and J{\'e}gou, Herv{\'e}. "Billion-scale similarity search with GPUs" arXiv preprint arXiv:1702.08734.