
If you're into machine learning, you might have heard about Extra Trees. But what exactly is it, and how does it work? In this blog, we'll take a dive into the world of Extra Trees, uncovering its inner workings and the math behind it. Plus, we'll wrap up with a hands-on Python code example to bring it all together.
Understanding Extra Trees:
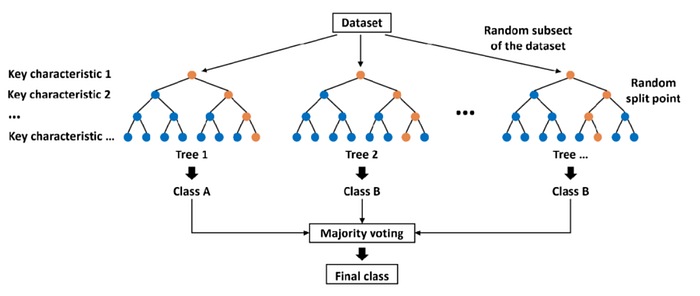
Extra Trees, or Extremely Randomized Trees, is a type of ensemble learning method used for classification and regression tasks. It's like a group of decision trees working together to make predictions.
How Extra Trees Works:
- Randomness Rules:
- Extra Trees adds extra randomness compared to regular decision trees or Random Forests.
- Instead of carefully selecting the best split for each node, Extra Trees randomly chooses splits without much thought. It's like throwing darts blindfolded, but with a purpose!
2. Building the Team:
- Multiple decision trees are built during training, each with its own random set of features and thresholds.
- Each tree in the team gets a say in the final prediction.
3. Voting Time:
- When it's prediction time, each tree casts its vote.
- For classification tasks, the most popular class among the trees wins. For regression tasks, it's like taking the average of all predictions.
Why Extra Trees Rocks:
- Less Fuss, Less Overfitting: All this randomness helps Extra Trees avoid getting too hung up on noisy data or trying too hard to fit the training data perfectly.
- Speedy Gonzales: Extra Trees can be faster to train compared to some other methods, making it a handy tool when you're crunched for time.
- Not a Stickler for Details: Extra Trees doesn't get too picky about hyperparameters, which can be a relief when you're just starting out with machine learning.
Python Code Example:
Enough talk, let's see some action! Here's a simple Python code snippet to get you started with Extra Trees:
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load the Iris dataset
iris = load_iris()
X, y = iris.data, iris.target
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create an Extra Trees classifier
clf = ExtraTreesClassifier(n_estimators=100, random_state=42)
# Train the classifier
clf.fit(X_train, y_train)
# Make predictions on the test set
y_pred = clf.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)In this example, we're using the famous Iris dataset to train an Extra Trees classifier and evaluate its accuracy on a test set. It's a simple yet powerful demonstration of Extra Trees in action!
Conclusion:
Extra Trees may sound fancy, but at its core, it's just a bunch of decision trees having a party and making predictions together. With its extra dose of randomness, Extra Trees can be a valuable addition to your machine learning toolkit, offering speed, simplicity, and solid performance. So why not give it a try in your next project?
Reference: