


Discover how to efficiently clean and transform JSON files into Lakehouse tables using Microsoft Fabric Notebooks. This article provides a detailed walkthrough, from leveraging API data to utilizing PySpark for data transformation.
Get JSON via API
We will use a Data Pipeline — Copy Activity to store a JSON file from an API into a Lakehouse. You can find the full step-by-step on this part in this story. Here we will focus on the file transformation.
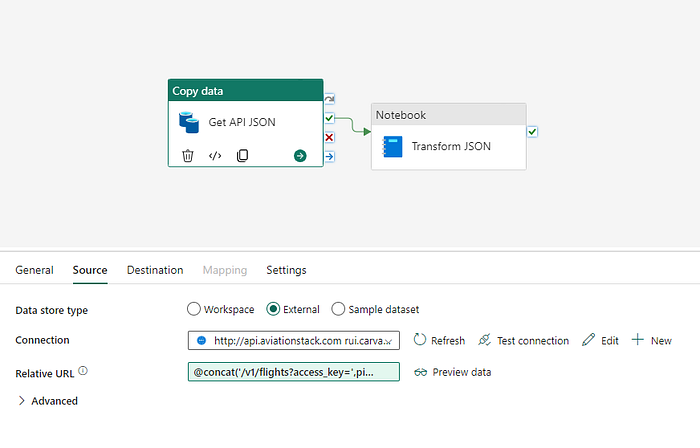
Let´s focus on the second step of this pipeline where we use a Notebook activity to call a Notebook in the workspace to transform the JSON file and save it as a table.
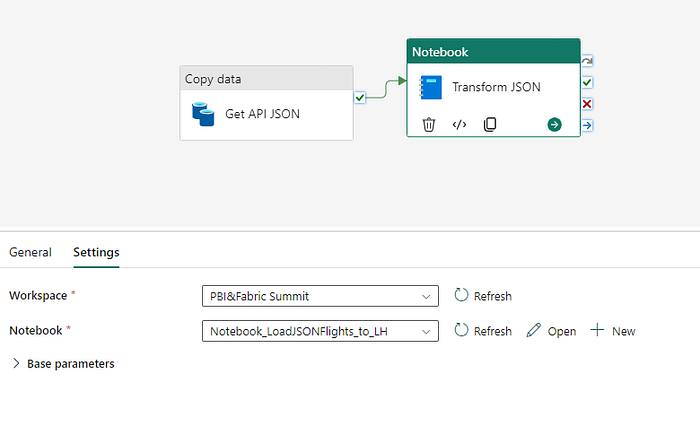
What is a Notebook?
Notebook refers to a type of interactive computing environment that allows users to combine executable code, rich text, visualizations, equations, and other media in a single document.
Notebooks allow users to write and execute code in a variety of programming languages (most commonly Python, R, and Julia) in discrete blocks or cells. This allows for step-by-step data exploration and analysis.
Fabric Notebooks
The Microsoft Fabric notebook serves as a crucial tool for crafting Apache Spark jobs and conducting machine learning experiments. While data engineers primarily utilize it for data ingestion, preparation, and transformation tasks, data scientists leverage these notebooks for a range of machine learning activities. These include designing experiments and models, tracking model performance, and managing deployment processes.
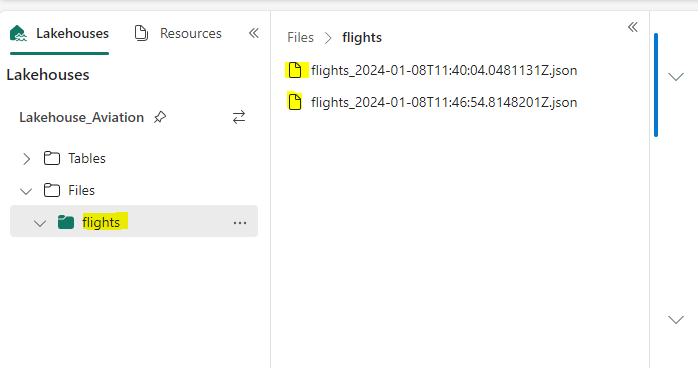
Currently, we have these JSON files in the flights folder in our Lakehouse.
This is the JSON format. Here we can see data related to flights with information like flight dates, departures, and arrivals.
{
"pagination":{
"limit":100,
"offset":0,
"count":100,
"total":382609
},
"data":[
{
"flight_date":"2024-01-10",
"flight_status":"scheduled",
"departure":{
"airport":"Nhulunbuy",
"timezone":"Australia/Darwin",
"iata":"GOV",
"icao":"YPGV",
"terminal":null,
"gate":null,
"delay":null,
"scheduled":"2024-01-10T08:00:00+00:00",
"estimated":"2024-01-10T08:00:00+00:00",
"actual":"2024-01-08T08:51:00+00:00",
"estimated_runway":"2024-01-08T08:51:00+00:00",
"actual_runway":"2024-01-08T08:51:00+00:00"
},
"arrival":{
"airport":"Darwin",
"timezone":"Australia/Darwin",
"iata":"DRW",
"icao":"YPDN",
"terminal":"D",
"gate":null,
"baggage":null,
"delay":56,
"scheduled":"2024-01-08T09:54:00+00:00",
"estimated":"2024-01-08T09:54:00+00:00",
"actual":null,
"estimated_runway":null,
"actual_runway":null
},
"airline":{
"name":"empty",
"iata":null,
"icao":null
},
"flight":{
"number":null,
"iata":null,
"icao":null,
"codeshared":null
},
"aircraft":null,
"live":null
}]
}Notebook
You will need to create a new PySpark Notebook in your workspace with the following cells, linked to your Lakehouse.
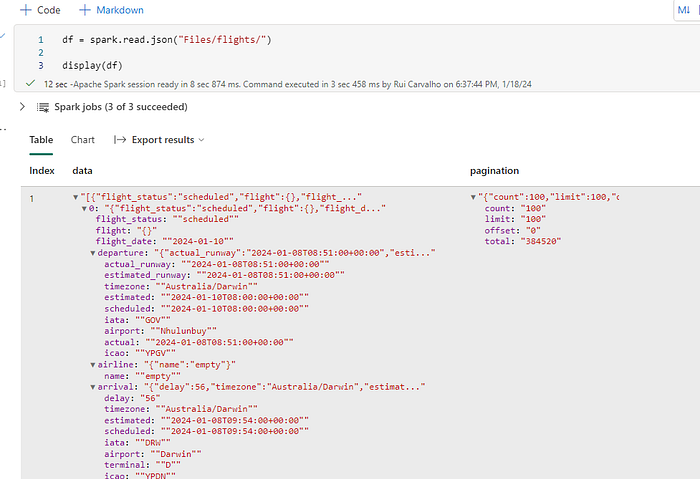
In this first cell, we are loading all the JSON files from the flights folder to a py dataframe.
# Load JSON files in folder flights to a python dataframe
df = spark.read.json("Files/flights/")The result will be an array structure with all the data that you saw above.
In this following cell, the goal is to read the JSON´s content, make some transformations to specific attributes, and then explode the array so we have the dataframe with a column format.
Call SQL functions:
The transformation work may vary depending on the JSON structure.
# Apply transformation to the dataframe
from pyspark.sql.functions import col, to_timestamp, to_date, explode
exploded_df = df.select(explode(col("data")).alias("data"))
tf_df = exploded_df.select(
to_date(col("data.flight_date"), "yyyy-MM-dd").alias("flight_date"),
col("data.flight_status").alias("flight_status"),
col("data.departure.iata").alias("departure_airport_code"),
to_timestamp(col("data.departure.scheduled")).alias("departure_scheduled_date"),
to_timestamp(col("data.arrival.scheduled")).alias("arrival_scheduled_date"),
col("data.airline.iata").alias("airline_code"),
col("data.flight.number").alias("flight_number")
)
display(tf_df)First, we will use the explode function to return a new row for each element in the given array or map, in this case, it´s called data.
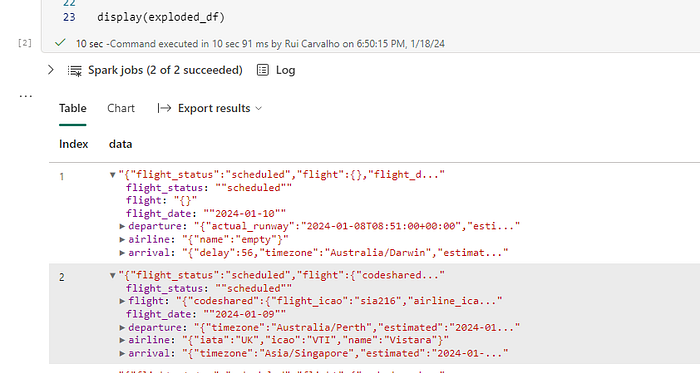
Then let´s select the data in our data frame explode_df as columns using the pyspark sql functions. Some transformations are:
- to_date(col("data.flight_date"), "yyyy-MM-dd").alias("flight_date") — convert flight_date to date with format yyyy-MM-dd.
- to_timestamp(col("data.departure.scheduled")).alias("departure_scheduled_date") — convert column schedule, which is a date, to a timestamp format.
To all the columns that we have selected, we gave them an alias. As we display our tf_df dataframe, now we have a columnar format.
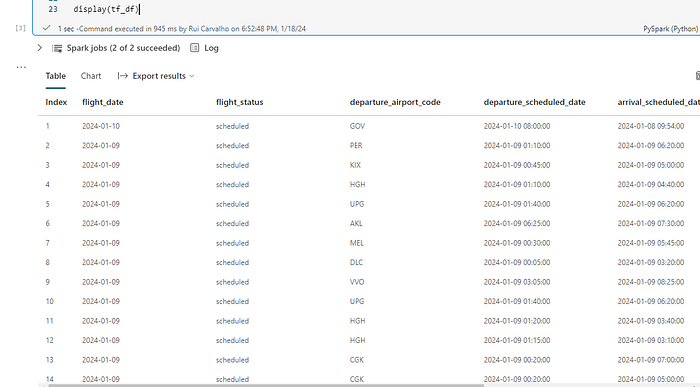
For our last step, we want to save this result as a delta table in the Lakehouse.
Very simple 👇
# Load as a table to the lakehouse
tf_df.write.format("delta").mode("overwrite").save("Tables/fctFlights")Here´s the final result:
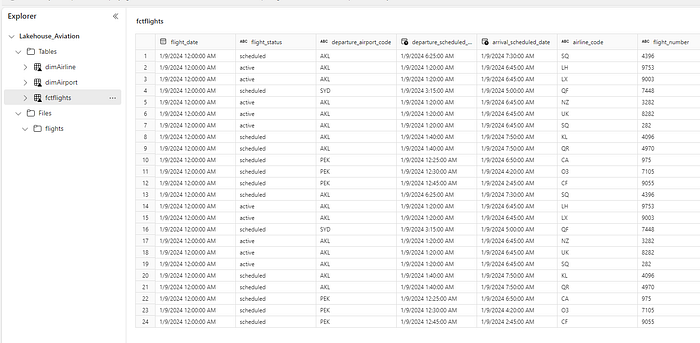
We can set this in our pipeline, and each time a new JSON file is stored in the Lakehouse we run this notebook.
What's more? For just $5 a month, become a Medium Member and enjoy the liberty of limitless access to every masterpiece on Medium. By subscribing via my page, you not only contribute to my work but also play a crucial role in enhancing the quality of my work. Your support means the world! 😊