


Introduction
YOLO (You Only Look Once) is an object detection algorithm that uses deep neural network models, specifically convolutional neural networks, to detect and classify objects in real-time. The algorithm was first introduced to the world in the 2016 paper, You Only Look Once: Unified, Real-Time Object Detection by Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi, which can be read here.
Since its introduction, YOLO has become one of the most popular algorithms for object detection and classification tasks, thanks to its high accuracy and speed. It has achieved state-of-the-art performance on a variety of object detection benchmarks.
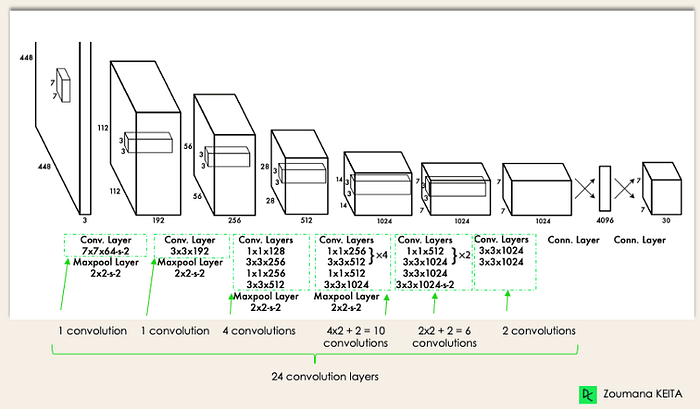
Just recently, in the first week of May 2023, the YOLO-NAS model has been introduced to the Machine Learning world, and it has unmatched precision and speed, outperforming other models like YOLOv7 and YOLOv8.
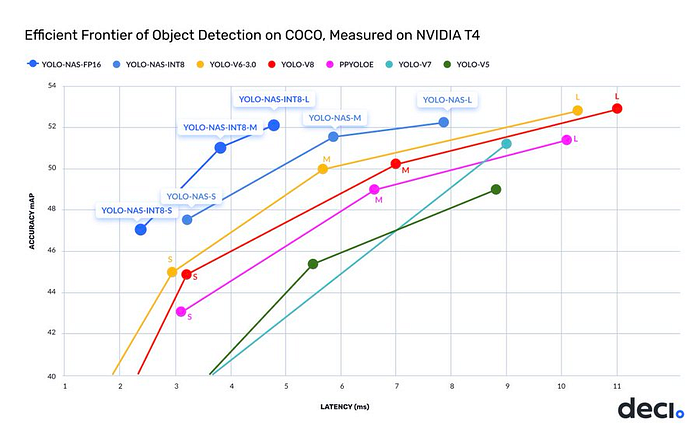
The YOLO-NAS model is pre-trained on datasets like COCO and Objects365, which makes it suitable for real-world applications. It is currently available on Deci's SuperGradients, which is a PyTorch-based library that contains nearly 40 pre-trained models for performing different computer vision tasks, such as classification, detection, segmentation, etc.
Let's get to work, then, and install the SuperGradients library to start using YOLO-NAS!
# Installing supergradients lib
!pip install super-gradients==3.1.0Importing and Loading YOLO-NAS
#importing models from supergradients' training module
from super_gradients.training import modelsThe next step is to initiate the model. YOLO-NAS is available in different models, for this notebook, we're going to use yolo_nas_l, with pretrained_weights = 'coco'.
You can get more information on the different models on this GitHub page.
# Initializing model
yolo_nas = models.get("yolo_nas_l", pretrained_weights = "coco")Model Architecture
In the code cell below, we use torchinfo's summary to obtain the YOLO-NAS architecture, which is useful to get an in-depth understanding on how the model operates.
# Yolo NAS architecture
!pip install torchinfo
from torchinfo import summary
summary(model = yolo_nas,
input_size = (16,3,640,640),
col_names = ['input_size',
'output_size',
'num_params',
'trainable'],
col_width = 20,
row_settings = ['var_names'])
=================================================================================================================================================
Layer (type (var_name)) Input Shape Output Shape Param # Trainable
=================================================================================================================================================
YoloNAS_L (YoloNAS_L) [16, 3, 640, 640] [16, 8400, 4] -- True
├─NStageBackbone (backbone) [16, 3, 640, 640] [16, 96, 160, 160] -- True
│ └─YoloNASStem (stem) [16, 3, 640, 640] [16, 48, 320, 320] -- True
│ │ └─QARepVGGBlock (conv) [16, 3, 640, 640] [16, 48, 320, 320] 3,024 True
│ └─YoloNASStage (stage1) [16, 48, 320, 320] [16, 96, 160, 160] -- True
│ │ └─QARepVGGBlock (downsample) [16, 48, 320, 320] [16, 96, 160, 160] 88,128 True
│ │ └─YoloNASCSPLayer (blocks) [16, 96, 160, 160] [16, 96, 160, 160] 758,594 True
│ └─YoloNASStage (stage2) [16, 96, 160, 160] [16, 192, 80, 80] -- True
│ │ └─QARepVGGBlock (downsample) [16, 96, 160, 160] [16, 192, 80, 80] 351,360 True
│ │ └─YoloNASCSPLayer (blocks) [16, 192, 80, 80] [16, 192, 80, 80] 2,045,315 True
│ └─YoloNASStage (stage3) [16, 192, 80, 80] [16, 384, 40, 40] -- True
│ │ └─QARepVGGBlock (downsample) [16, 192, 80, 80] [16, 384, 40, 40] 1,403,136 True
│ │ └─YoloNASCSPLayer (blocks) [16, 384, 40, 40] [16, 384, 40, 40] 13,353,733 True
│ └─YoloNASStage (stage4) [16, 384, 40, 40] [16, 768, 20, 20] -- True
│ │ └─QARepVGGBlock (downsample) [16, 384, 40, 40] [16, 768, 20, 20] 5,607,936 True
│ │ └─YoloNASCSPLayer (blocks) [16, 768, 20, 20] [16, 768, 20, 20] 22,298,114 True
│ └─SPP (context_module) [16, 768, 20, 20] [16, 768, 20, 20] -- True
│ │ └─Conv (cv1) [16, 768, 20, 20] [16, 384, 20, 20] 295,680 True
│ │ └─ModuleList (m) -- -- -- --
│ │ └─Conv (cv2) [16, 1536, 20, 20] [16, 768, 20, 20] 1,181,184 True
├─YoloNASPANNeckWithC2 (neck) [16, 96, 160, 160] [16, 96, 80, 80] -- True
│ └─YoloNASUpStage (neck1) [16, 768, 20, 20] [16, 192, 20, 20] -- True
│ │ └─Conv (reduce_skip1) [16, 384, 40, 40] [16, 192, 40, 40] 74,112 True
│ │ └─Conv (reduce_skip2) [16, 192, 80, 80] [16, 192, 80, 80] 37,248 True
│ │ └─Conv (downsample) [16, 192, 80, 80] [16, 192, 40, 40] 332,160 True
│ │ └─Conv (conv) [16, 768, 20, 20] [16, 192, 20, 20] 147,840 True
│ │ └─ConvTranspose2d (upsample) [16, 192, 20, 20] [16, 192, 40, 40] 147,648 True
│ │ └─Conv (reduce_after_concat) [16, 576, 40, 40] [16, 192, 40, 40] 110,976 True
│ │ └─YoloNASCSPLayer (blocks) [16, 192, 40, 40] [16, 192, 40, 40] 2,595,716 True
│ └─YoloNASUpStage (neck2) [16, 192, 40, 40] [16, 96, 40, 40] -- True
│ │ └─Conv (reduce_skip1) [16, 192, 80, 80] [16, 96, 80, 80] 18,624 True
│ │ └─Conv (reduce_skip2) [16, 96, 160, 160] [16, 96, 160, 160] 9,408 True
│ │ └─Conv (downsample) [16, 96, 160, 160] [16, 96, 80, 80] 83,136 True
│ │ └─Conv (conv) [16, 192, 40, 40] [16, 96, 40, 40] 18,624 True
│ │ └─ConvTranspose2d (upsample) [16, 96, 40, 40] [16, 96, 80, 80] 36,960 True
│ │ └─Conv (reduce_after_concat) [16, 288, 80, 80] [16, 96, 80, 80] 27,840 True
│ │ └─YoloNASCSPLayer (blocks) [16, 96, 80, 80] [16, 96, 80, 80] 2,546,372 True
│ └─YoloNASDownStage (neck3) [16, 96, 80, 80] [16, 192, 40, 40] -- True
│ │ └─Conv (conv) [16, 96, 80, 80] [16, 96, 40, 40] 83,136 True
│ │ └─YoloNASCSPLayer (blocks) [16, 192, 40, 40] [16, 192, 40, 40] 1,280,900 True
│ └─YoloNASDownStage (neck4) [16, 192, 40, 40] [16, 384, 20, 20] -- True
│ │ └─Conv (conv) [16, 192, 40, 40] [16, 192, 20, 20] 332,160 True
│ │ └─YoloNASCSPLayer (blocks) [16, 384, 20, 20] [16, 384, 20, 20] 5,117,700 True
├─NDFLHeads (heads) [16, 96, 80, 80] [16, 8400, 4] -- True
│ └─YoloNASDFLHead (head1) [16, 96, 80, 80] [16, 68, 80, 80] -- True
│ │ └─ConvBNReLU (stem) [16, 96, 80, 80] [16, 128, 80, 80] 12,544 True
│ │ └─Sequential (cls_convs) [16, 128, 80, 80] [16, 128, 80, 80] 147,712 True
│ │ └─Conv2d (cls_pred) [16, 128, 80, 80] [16, 80, 80, 80] 10,320 True
│ │ └─Sequential (reg_convs) [16, 128, 80, 80] [16, 128, 80, 80] 147,712 True
│ │ └─Conv2d (reg_pred) [16, 128, 80, 80] [16, 68, 80, 80] 8,772 True
│ └─YoloNASDFLHead (head2) [16, 192, 40, 40] [16, 68, 40, 40] -- True
│ │ └─ConvBNReLU (stem) [16, 192, 40, 40] [16, 256, 40, 40] 49,664 True
│ │ └─Sequential (cls_convs) [16, 256, 40, 40] [16, 256, 40, 40] 590,336 True
│ │ └─Conv2d (cls_pred) [16, 256, 40, 40] [16, 80, 40, 40] 20,560 True
│ │ └─Sequential (reg_convs) [16, 256, 40, 40] [16, 256, 40, 40] 590,336 True
│ │ └─Conv2d (reg_pred) [16, 256, 40, 40] [16, 68, 40, 40] 17,476 True
│ └─YoloNASDFLHead (head3) [16, 384, 20, 20] [16, 68, 20, 20] -- True
│ │ └─ConvBNReLU (stem) [16, 384, 20, 20] [16, 512, 20, 20] 197,632 True
│ │ └─Sequential (cls_convs) [16, 512, 20, 20] [16, 512, 20, 20] 2,360,320 True
│ │ └─Conv2d (cls_pred) [16, 512, 20, 20] [16, 80, 20, 20] 41,040 True
│ │ └─Sequential (reg_convs) [16, 512, 20, 20] [16, 512, 20, 20] 2,360,320 True
│ │ └─Conv2d (reg_pred) [16, 512, 20, 20] [16, 68, 20, 20] 34,884 True
=================================================================================================================================================
Total params: 66,976,392
Trainable params: 66,976,392
Non-trainable params: 0
Total mult-adds (T): 1.04
=================================================================================================================================================
Input size (MB): 78.64
Forward/backward pass size (MB): 27238.60
Params size (MB): 178.12
Estimated Total Size (MB): 27495.37
=================================================================================================================================================Object Detection on Images
We can now test the model's abilities in detecting objects on different images.
In the code below, we initiate a variable called image, which receives a URL containing an image. Then, we can use the predict and show methods to display the image with the model's predictions on it.
image = "https://i.pinimg.com/736x/b4/29/48/b42948ef9202399f13d6e6b3b8330b20.jpg"
yolo_nas.predict(image).show()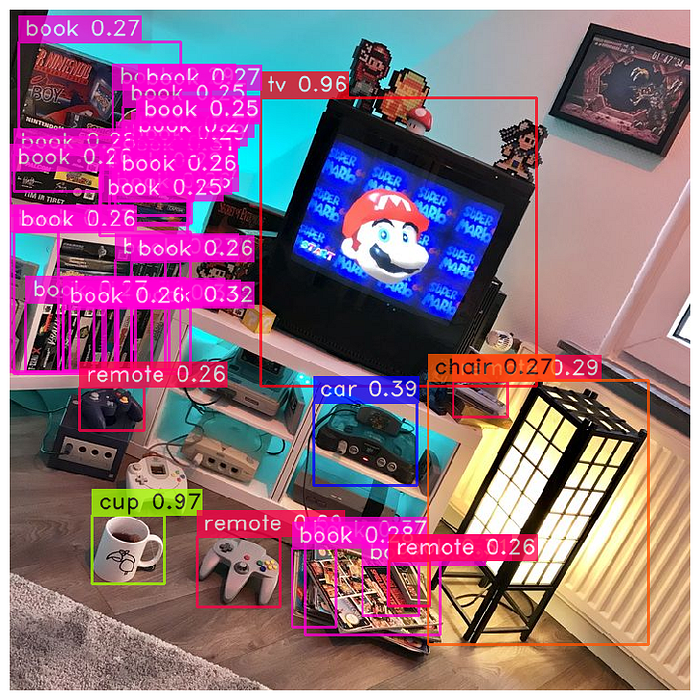
On the image above, we can see the detections made for each object and the confidence scores the model has in its own predictions. For instance, we can see that the model has a 97% confidence score that the white object on the floor is a cup. However, there are many objects in this image, and we can see that the model mistakes the Nintendo 64 game console for a car.
We can improve our results by using the conf argument, which serves as a threshold for detections. We can, for instance, change this value to conf = 0.50, so the model only displays detections on which the confidence score is above 50%. Let's try it out.
image = "https://i.pinimg.com/736x/b4/29/48/b42948ef9202399f13d6e6b3b8330b20.jpg"
yolo_nas.predict(image, conf = 0.50).show()
Now the model only displays objects with at least a 50% confidence score in its detections, which are the cup, the TV, and the remote.
We can test more images.

Object Detection on Videos
We can also use the YOLO-NAS model to perform real-time object detection on videos!
On the codes below, I use the YouTubeVideo module from the IPython library to select and save any YouTube video I'd like.
from IPython.display import YouTubeVideo # Importing YouTubeVideo from IPython's display module
video_id = "VtK2ZMlcCQU" # Selecting video ID
video = YouTubeVideo(video_id) # Loading video
display(video) # Displaying videoNow that we have selected a video, we are going to use the youtube-dl library to download the video from YouTube in a .mp4 format.
After this is done, we save the video to the input_video_path variable, which will serve as input for our model to perform detections.
# Downloading video
video_url = f'https://www.youtube.com/watch?v={video_id}'
!pip install -U "git+https://github.com/ytdl-org/youtube-dl.git"
!python -m youtube_dl -f 'bestvideo[ext=mp4]+bestaudio[ext=m4a]/mp4' "$video_url"
print('Video downloaded')
# Selecting input and output paths
input_video_path = f"/kaggle/working/Golf Rehab 'Short Game' Commercial-VtK2ZMlcCQU.mp4"
output_video_path = "detections.mp4"Now we import PyTorch and enable the GPU.
import torch
device = 'cuda' if torch.cuda.is_available() else "cpu"We then use the to( ) method to run the YOLO-NAS model on GPU, and we use the predict( ) method to perform predictions on the video stored in the input_video_path variable. The save( ) method is used to save the video with the detections on it to the path specified by output_video_path.
yolo_nas.to(device).predict(input_video_path).save(output_video_path) # Running predictions on video
Video downloaded
Predicting Video: 100%|██████████| 900/900 [33:15<00:00, 2.22s/it]After all that is done, we use IPython again to display a .gif file containing the video downloaded above in a .gif format, so it is visible on this Kaggle notebook.
from IPython.display import Image
with open('/kaggle/input/detection-gif/detections.gif','rb') as f:
display(Image(data=f.read(), format='png'))You can see the results below:
Conclusion
We performed an initial object detection task on both images and video using the newly released YOLO-NAS model.
It's important, however, to highlight the fact that you can fine-tune this model using a custom dataset, which improves its performance on certain objects. For more information on how to fine-tune the YOLO-NAS model, please, feel free to take a look at the notebook Intro to SuperGradients + YOLONAS Starter Notebook, available on Google Colab.
Thank you so much for reading,
Luís Fernando Torres
Reference
Kaggle Notebook — 👨💻Object Detection: YOLO-NAS Model 🔍
Do you identify as Latinx and are working in artificial intelligence or know someone who is Latinx and is working in artificial intelligence?
- Get listed on our directory and become a member of our member's forum: https://forum.latinxinai.org/
- Become a writer for the LatinX in AI Publication by emailing us at [email protected]
- Learn more on our website: http://www.latinxinai.org/
Don't forget to hit the 👏 below to help support our community — it means a lot!
Thank you :)