


In the last post Building a movie content based recommender using tf-idf I explained how to build a simple movie recommender based on the genres.
In this post, we'll be implementing a Memory-based collaborative filtering model, and go through the main differences both conceptually and in implementation between user and item-based methods.
You'll find all the code to reproduce the results in a jupyter notebook here.
Introduction
Collaborative filtering is the most common technique when it comes to recommender systems. As its name suggests, it is a technique that helps filter out items for a user in a collaborative way, that is, based on the preferences of similar users.
Say Lizzy has just watched "Arrival" and "Blade Runner 2049", and now wants to be recommended some similar movies, because she loved these.
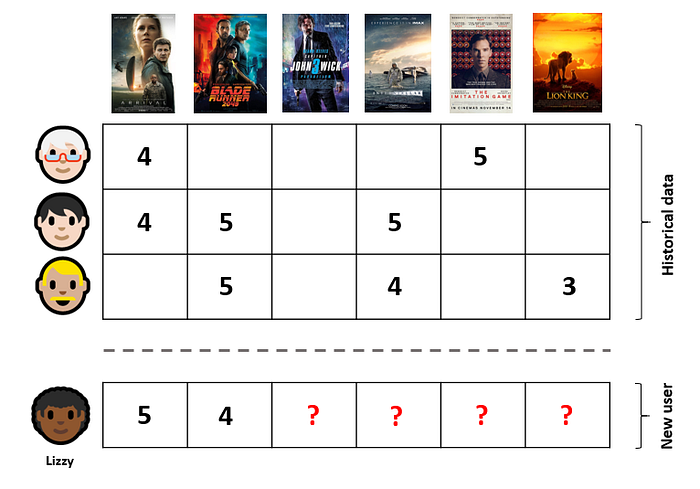
The main idea behind collaborative filtering methods, is to find users who also liked these movies and recommend unseen movies based on their preferences. In this example, the model would likely find that other users who enjoyed these movies also liked "Interstellar", which would possibly be a nice recommendation for Lizzy.
While this is the main idea, there are many approaches to this problem and choosing the more suited one will depend on multiple factors, such as the size of the dataset we're working with and its sparsity.
Types of collaborative filtering methods
As mentioned, there are many collaborative filtering (CF in short) methods, bellow are the main types we can find:
- Memory-based
Memory-based methods use user rating historical data to compute the similarity between users or items. The idea behind these methods is to define a similarity measure between users or items, and find the most similar to recommend unseen items.
- Model-based
Model-based CF uses machine learning algorithms to predict users' rating of unrated items. There are many model-based CF algorithms, the most commonly used are matrix factorization models such as to applying a SVD to reconstruct the rating matrix, latent Dirichlet allocation or Markov decision process based models.
- Hybrid
These aim to combine the memory-based and the model-based approaches. One of the main drawbacks of the above methods, is that you'll find yourself having to choose between historical user rating data and user or item attributes. Hybrid methods enable us to leverage both, and hence tend to perform better in most cases. The most widely used methods nowadays are factorization machines.
Let's delve a little more into memory based methods now, since it is the method we'll be implementing in this post.
Memory-based CF
There are 2 main types of memory-based collaborative filtering algorithms: User-Based and Item-Based. While their difference is subtle, in practice they lead to very different approaches, so it is crucial to know which is the most convenient for each case. Let's go through a quick overview of these methods:
- User-Based
Here we find users that have seen/rated similar content, and use their preferences to recommend new items:
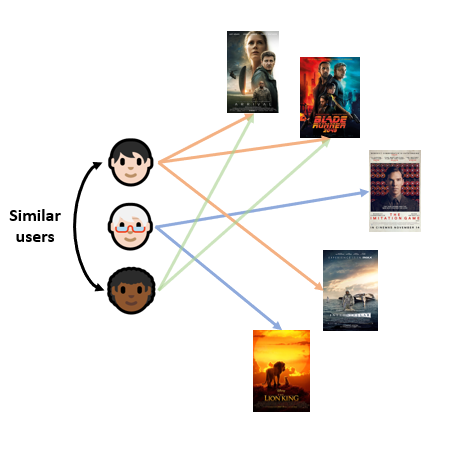
A drawback is that there tends to be many more users than items, which leads to much bigger user similarity matrices (this might be clear in the following section) leading to performance and memory issues on larger datasets, which forces to rely on parallelisation techniques or other approaches altogether.
Another common problem is that we'll suffer from a cold-start: There may be no to little information on a new user's preferences, hence nothing to compare with.
- Item-Based
The idea is similar, but instead, starting from a given movie (or set of movies) we find similar movies based on other users' preferences.
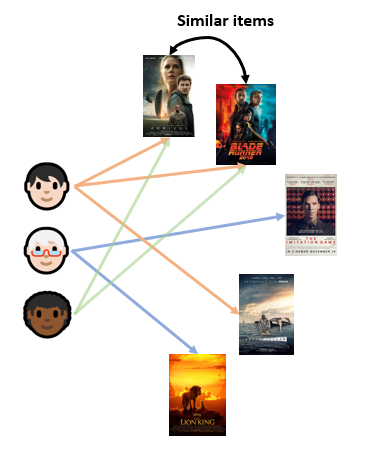
Contrarily to user-based methods, item similarity matrices tend to be smaller, which will reduce the cost of finding neighbours in our similarity matrix.
Also, since a single item is enough to recommend other similar items, this method will not suffer from the cold-start problem.
A drawback of item-based methods is that they there tends to be a lower diversity in the recommendations as opposed to user-based CF.
Implementation
The data
We'll be using the same dataset as in the previous post, the MovieLens dataset, which contains rating data sets from the MovieLens web site. It contains on 1M anonymous ratings of approximately 4000 movies made by 6000 MovieLens users, released in 2/2003.
We'll be working with three .csv files: ratings, users, and movies. Please check the previous post for more details on the dataset.
User-item matrix
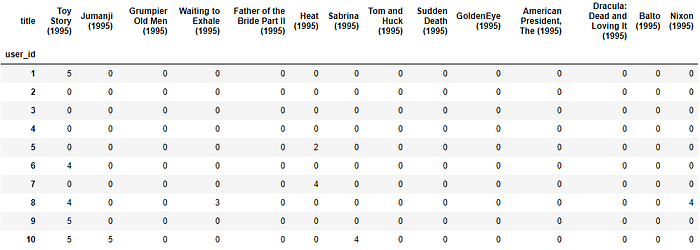
The first thing we'll need to do, is to create the user-item matrix. This is essentially a pivoted table from the rating data, where the rows will be the users, the columns will be the movies and the dataframe is filled with the rating the user has given (if it exists , 0 otherwise):
user_item_m = ratings.pivot('user_id','movie_id','rating').fillna(0)
print(f'Shape: {user_item_m.shape}')
> Shape: (29909, 5840)Which looks like (I've joined with the movies table so the titles can be seen here too):
Similarity matrix
Next, we will define a similarity matrix. Along the lines of the previous post on Content based recommenders, see the section Similarity between vectors, we want to find a proximity measure between all users (or items) in the user-item matrix. A commonly used measure is the cosine similarity.
As we also saw, this similarity measure owns its name to the fact that it equals to the cosine of the angle between the two vectors being compared, user (or item) similarity vectors of scores in this case. The lower the angle between two vectors, the higher the cosine will be, hence yielding a higher similarity factor. See the aforementioned section for more details on this.
We can use sklearn's metrics.pairwise sub-module for pairwise distance or similarity metrics, in this case we'll be using cosine_similarity .
Note that the function, has the signature:
sklearn.metrics.pairwise.cosine_similarity(X, Y=None, dense_output=True)Where Yis expected to be:
Y: ndarray or sparse array, shape: (n_samples_Y, n_features). If
None, the output will be the pairwise similarities between all samples inX.
So by only specifying X this will generate a similarity matrix from the samples in X :
from sklearn.metrics.pairwise import cosine_similarity
X_user = cosine_similarity(user_item_m)
print(X_user.shape)
(6040, 6040)
print(X_user)
array([[1. , 0.063, 0.127, 0.116, 0.075, 0.15 , 0.035, 0.102],
[0.063, 1. , 0.111, 0.145, 0.107, 0.105, 0.246, 0.161],
[0.127, 0.111, 1. , 0.127, 0.066, 0.036, 0.185, 0.086],
[0.116, 0.145, 0.127, 1. , 0.052, 0.016, 0.1 , 0.072],
[0.075, 0.107, 0.066, 0.052, 1. , 0.052, 0.106, 0.18 ],
[0.15 , 0.105, 0.036, 0.016, 0.052, 1. , 0.067, 0.085],
[0.035, 0.246, 0.185, 0.1 , 0.106, 0.067, 1. , 0.202],
[0.102, 0.161, 0.086, 0.072, 0.18 , 0.085, 0.202, 1. ],
[0.174, 0.156, 0.1 , 0.092, 0.242, 0.078, 0.125, 0.217],
[0.209, 0.162, 0.158, 0.096, 0.079, 0.124, 0.091, 0.109]])This will generate a user similarity matrix, with shape (n_users, n_users).
And since X is expected to be:
X: ndarray or sparse array, shape: (n_samples_X, n_features)
By transposing the user-item matrix, our samples will now be the columns of the user-item matrix, i.e. the movies. So if our original user-item matrix is of shape (n,m) , by finding the cosine similarities on the transposed matrix we'll end up with a (m,m) matrix:
X_item = cosine_similarity(user_item_m.T)
X_item.shape
(3706, 3706)Which will represent the item similarity matrix.
The algorithm
Having created the similarity matrices, we can now define some logic to find similar users. In the case of a user-based recommendation we want to find users similar to a new user to who we want to recommend movies, and since we already have the similarity scores, we only have to search for the highest values in a given user row, and from there select the top k. Once we have the k closest users, we can find the highest rated movies that the user has not seen yet.
Of course in this case it is simpler, since we already have computed the similarity matrix between all users. In a real scenario, we'd have to update the similarity matrix with the new user, and then find the most similar users.
The algorithm for used-based CF can be summarised as:
- Compute the similarity between the new user with all other users (if not already done)
- Compute the mean rating of all movies of the k most similar users
- Recommend the top n rated movies by other users unseen by the user
Bellow is a function to implement a user-based CF recommender explained step by step:
As mentioned earlier, the difference in implementation between user and item-based CF systems is quite small. For this reason it might be a good idea to wrap both methods in a class, which once instantiated we'll then use to recommend movies or items to a given user:
Before testing the recommender on some examples, it might be useful to define a function to see which are the preferences of a user to see if the recommendations make sense or not . Here I'm sorting the ratings given to the movies seen by a user and taking the first 10:
Testing the recommender
Testing a recommender is actually tougher than it may seem. In the movielens dataset, a lot of the users will have seen a bit of everything, in the sense that they will probably have given a high rating to movies from multiple genres, not just their favourite.
A useful way to test the model, is to find some specific examples of users with specific tastes, for instance, with a clear preference for one or two genres. What I have done is to find users which have already seen a couple of movies, but from very few genres, meaning that they clearly have a preference for them. The recommender is hence expected to suggest movies from the same genre.
- Let's start with some user-based recommendations:
Let's try with a user which seems to have a preference for Drama:
rec = CfRec(user_item_m, X_user, movies)
because_user_liked(user_item_m, movies, ratings, 69)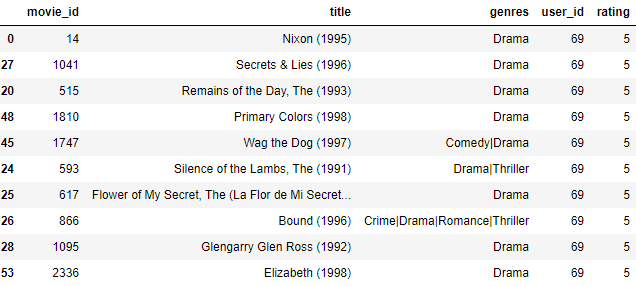
We can see that the movies that have been most highly rated by this user, are Drama movies. Let's see what the recommender suggests:
rec.recommend_user_based(69)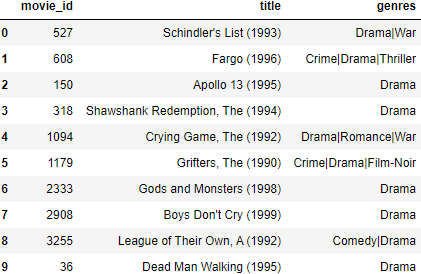
The recommendations seem good! Hard to tell whether the user would completely agree with the specific movies, but the genre preferences of the user are clearly reflected in the recommendations.
Let's try with a fan of Horror movies now:
because_user_liked(user_item_m, movies, ratings, 2155)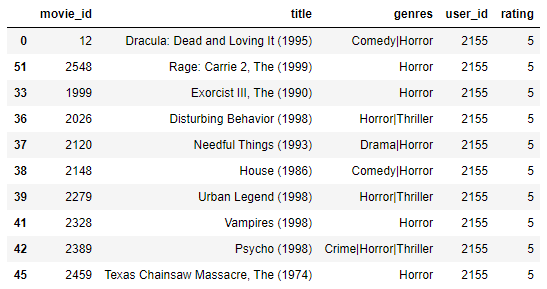
rec.recommend_user_based(2155)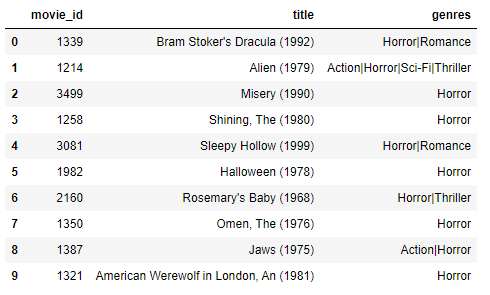
"The Shining", "Alien"… sounds like this user is missing out on these horror classics!
- Let's try now with some item-based recommendations
The first thing we'll have to do is create another instance of the class, but using the item similarity matrix this time as a similarity matrix:
rec = CfRec(user_item_m, X_item, movies)Here, as earlier discussed, the logic is to recommend movies based on some other movie. Let's see what the recommender suggests for a user who likes the sci-fi classic Dune:
rec.recommend_item_based(2021)
>> Because you liked Dune (1984), we'd recommend you to watch: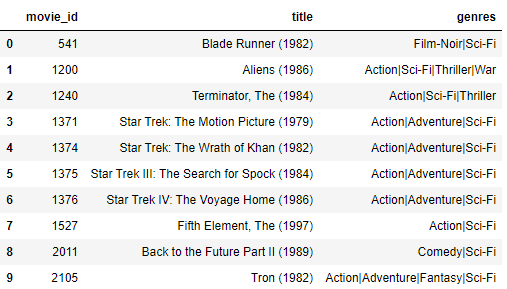
We can see that all recommended movies are from the same genre, and seem like good suggestions.
If we liked Se7en, a Crime and Thriller movie, we'd be recommended to watch:
rec.recommend_item_based(47)
>> Because you liked (Se7en) (1995), we'd recommend you to watch: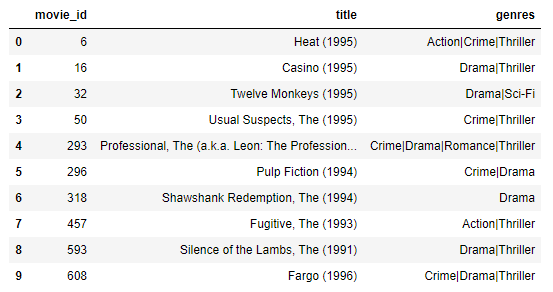
And finally, for a classic animation movie, Bambi:
rec.recommend_item_based(2018)
>> Because you liked Bambi (1942), we'd recommend you to watch: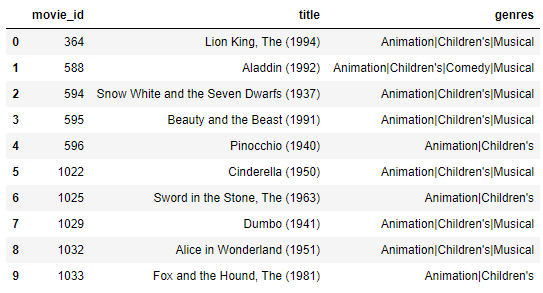
So in both cases, the implemented collaborative filtering models seem to provide good recommendations.
There are many improvements that could be done. For instance, we could account for the fact that users can behave very differently when it comes to rating movies. Some users might rate very highly all movies, whereas other might be much more critical. This could be done by subtracting the average score from each user, we'd then have normalised score per user.
I hope how ever, that this example has been illustrative in terms of how collaborative filtering methods work. I'd encourage you to take it as a starting point and perhaps tweak it a little or add some improvements.
Thanks a lot for taking the time to read this post and I hope you enjoyed it :)