


Why should I care about Markov Chains?
Two things: first, it is a key foundation for several Machine Learning concepts such as Hidden Markov Models (HMM) and Reinforcement Learning. Markov Chains are also used in other disciplines such as Finance (stock price movements) or in Engineering Physics (Brownian motion). A famous example is PageRanks, the first algorithm that Google used to score page ranks, which was based on Markov Chains.
Secondly, I find the concept in itself interesting because it is a completely different approach to most Data Science concepts you will encounter. In Machine Learning, you are trying to predict future events based on past data. With Markov Chains, you only care about the present state to predict the future (I will explain why in a second).
How would you predict the weather?
If you were asked to predict the next 365 days of weather for a given city, how would you go about it?
One solution to this problem could be to assign a probability of a rainy day and a probability of a a sunny day.
If you live in London where it rains about 1/3 of the year, you could for example assign a probability P(Raining) = 1/3 and P(Sunny) = 2/3. Now, you can simply run a quick simulation in Python and get predictions.
An example of what we would generate could look like this:
There is one major caveat to this approach. In reality, we know that:
- If it rains on a given day, it is much more likely that it will rain the following day.
- If it is sunny on a given day, it is much more likely that it will be sunny the following day.
The problem is that our current model does not take that into account. Ideally, we would like to "tell" our model that if it rains on a given day, we want a higher probability of raining the next day and the opposite for being sunny. We could phrase this as: "If our model is in the state raining, we want a high probability that it will stay in that state, i.e. that it will rain again the next day and vice-versa for sunny days".
So, how do we do that? Markov Chains.
Markov chain for simulating weather
Let's see what a Markov Chain for this problem would look like:
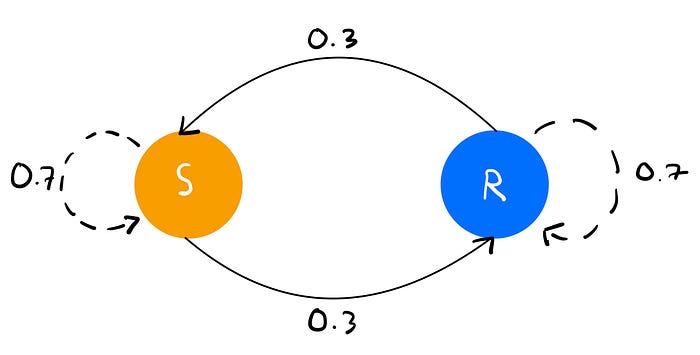
A Markov chain is made of 3 things: states (here, rainy or sunny), events (going from a sunny day to a rainy day or having a rainy day after a rainy day) and the probabilities of each event (0.3 for going from a sunny day to a rainy day or rainy day to rainy day and 0.7 for having a rainy day after a rainy day or a sunny day after a sunny day).
Now, instead of having a probability of sunny or rainy for each day, we have a probability for staying and leaving a sunny or rainy state.
More formally, we have two states, sunny and rainy, each having a probability of leaving the state and transitioning to another state and a probability of staying in the same state.
Transition matrix
For simulations, instead of using this diagram, we use what is called a transition matrix. Ours would look like this:
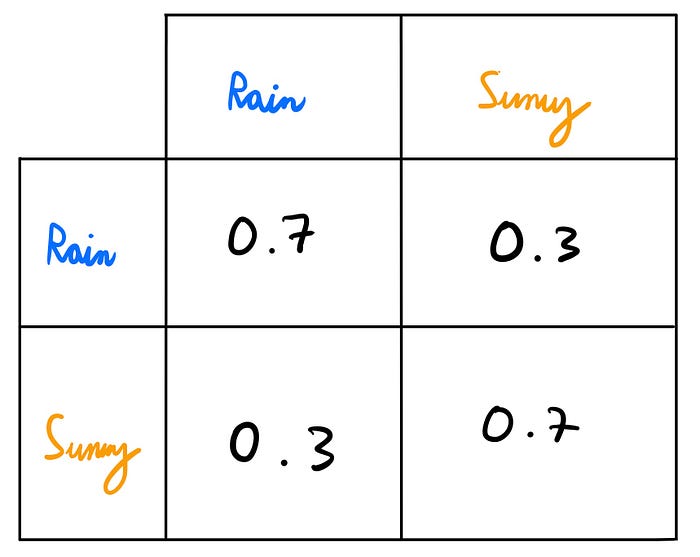
So, how do you read this matrix? Let's see how we would read the bottom left entry. You read this matrix first by row and then by column. Thus, for a given element, you would read:
Probability of transitioning from (row) to (column) is (value).
Here, for the bottom left element, we would read:
Probability of transitioning from a sunny day to a rainy one is 0.3.
Dice rolls
Now, let's tackle a more complicated example with dice rolls. Suppose you have two players A and B. A dice with six faces is rolled consecutively.
Player A bets that two consecutive rolls that sum to 10 will occur first. Player B bets that two consecutive 6s will occur first. The players keep rolling the dice until one player wins.
What is the probability that A will win?
How do we model that? … You guessed it.
Markov chain for dice rolls
Let's see how we should approach this problem.
For Player A, consecutive rolls that can sum to 10 are rolling a 5 and another 5, rolling a 4 then a 6 and rolling a 6 then a 4.
For Player B, the only option is to have two 6s in a row.
This means that getting a 1, 2 or 3 is "irrelevant" to our problem: these rolls will constitute our Initial State S. The other states 4, 5 and 6 will be the "relevant" states.
Now, let's see a first draft of our Markov Chain.
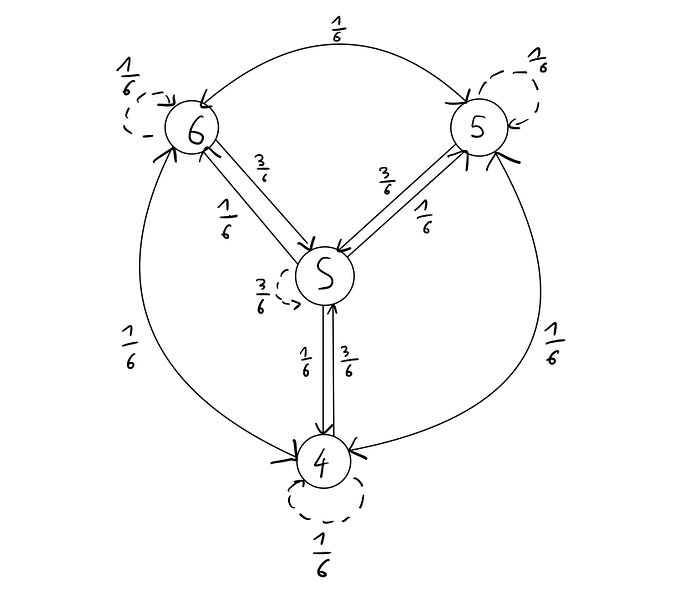
First, we have the State S (rolling a 1, 2 or 3). We have a probability of 3/6=0.5 of staying in State S (i.e. re-rolling a 1, 2 or 3). Each of the other states 4,5 and 6 have a probability 1/6 of staying in the same state or transitioning to the other two relevant states and a probability of 0.5 to transitioning to state S. All the probabilities of each state always sum to 1.
This looks good but we are missing the information about the combination of dice rolls that we are interested in. Let's add that:
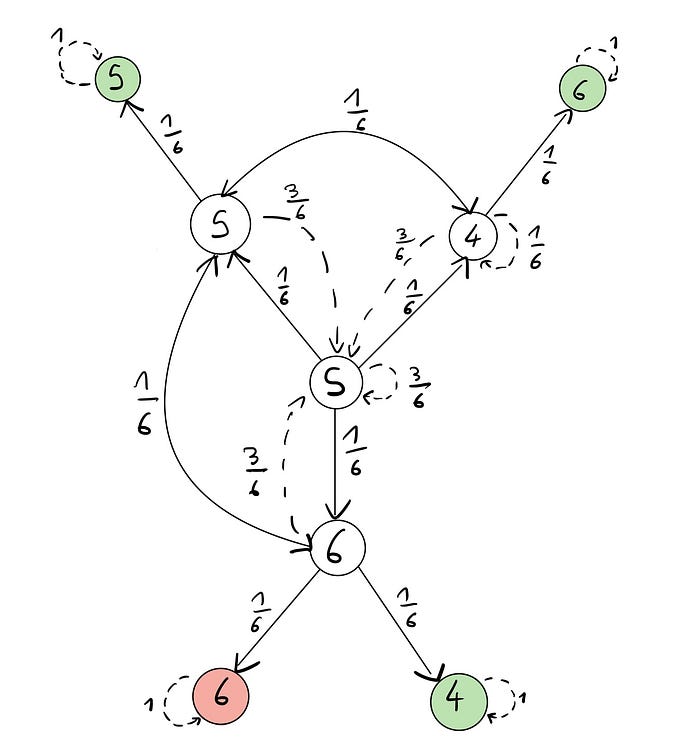
This is just like the one above but I have added the final states, which are in green (when A wins) and red (when B wins). These states have a probability of 1 of staying in the same state and are called absorbent. This is because, once you enter these states, you cannot leave them. In our case, they are absorbant because they represent when the game is over (when either A or B has won).
One thing to notice is that you can transition from 5 to 6 or from 5 to 4 and vice versa but you cannot transition from 6 to 4 and vice versa. This is because, if you have rolled a 6 and then roll a 4, you do not go back to the states in the middle: you reach one of the absorbant states and the game is over. That is why there is no arrows between these two.
That looks good but we still have not answered our initial question: what is the probability that player A wins? For that, we need to run some simulations using the transition matrix of this Markov Chain.

I have created 4 states in addition to rolling a 1, 2, 3, 4, 5 or 6: rolling a 4 then a 6 (46), rolling two 5s in a row (55), rolling a 6 then a 4 (64) and rolling two 6s in a row (66).
Player A wins if we reach the states 46, 55 and 64 while Player B wins if we reach the state 66.
Simulations
Let's see how we can run simulations with this transition matrix using Python. You can find the code on my GitHub.
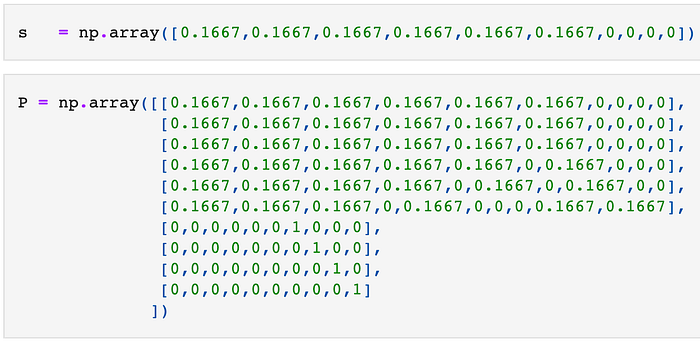
First, we define s, a vector that represents the probability of reaching one of the states at the beginning. It is ordered in the same way as the transition matrix — the first value s[0] corresponds to rolling a 1, the second value s[1] corresponds to rolling a 2 and the last value correspond to 66, rolling two 6s in a row.
The first 6 values have a probability of 1/6≈0.1667 because when rolling the dice the first time, we can roll either a 1, 2, 3, 4, 5 or a 6. The states 46, 55, 64 and 66 all have a probability of 0 as we cannot reach those states after the first roll.
Then, we define P, the transition matrix we had above as a NumPy array.
A quick step before running simulations is to check that all the rows of P sum to 1 (a good way to check if you understand transition matrices is to ask yourself why we are checking that).

In our case, all our rows sum to 1 (a little bit above for the first 6 elements as we are using an approximation of 1/6).
Now, let's run our simulations. For that, we simply multiply P by itself and then multiply it by our initial state vector s. You can see this as starting from the initial state s and then multiplying it by P a large number of times to simulate a large number of dice rolls.
We get the following results:
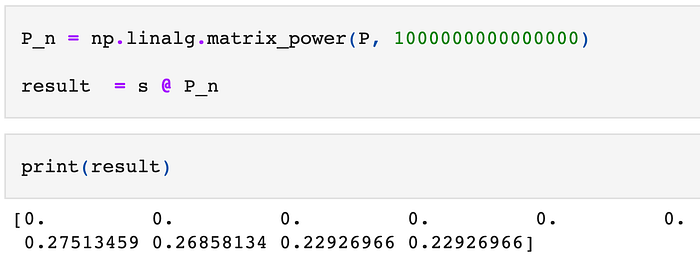
We see that after rolling the dice a large number of times, we are sure to never stay in the first 6 states as they have a probability of 0. This makes sense as it means that either A or B will win at some point and the game will stop.
The first three numbers that are not 0s in the vector correspond to probabilities for states 46, 55 and 64 (Player A wins). If we sum those probabilities, we get the probability that Player A will win the game.
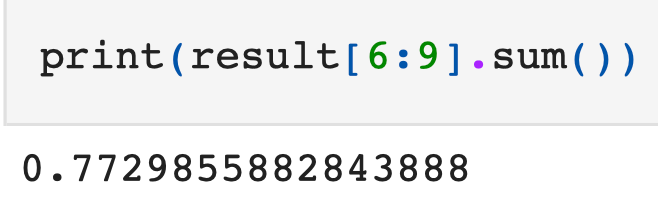
Now, we have our answer: player A has a probability of 0.77 of winning the game while B has probability 1–0.77 = 0.23 of winning.
Going further
I hope you liked this first introduction to Markov Chains.
I would recommend trying a different problem with dice rolls and redoing all the steps above (with different outcomes for example summing to 7 or with 3 players etc) to make sure you fully understand this concept. You can also try to run simulations with NumPy by reusing my code.
I hope you enjoyed this tutorial! Let me know what you thought of it.
Feel free to connect on LinkedIn and GitHub to talk more about Data Science and Machine Learning and to follow me on Medium! You can also support me by becoming a Medium member using this link.