


Introduction
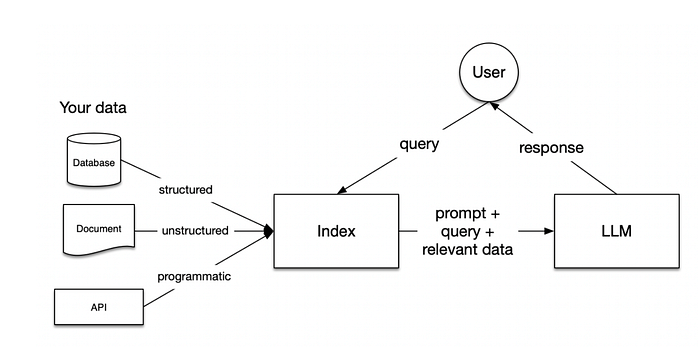
Prototyping a Retrieval-Augmented Generation (RAG) application is relatively straightforward, but the challenge lies in optimizing it for performance, robustness, and scalability across vast knowledge repositories. This guide aims to provide insights, strategies, and implementations leveraging LlamaIndex to enhance the efficiency of your RAG pipeline, catering to complex datasets and ensuring accurate query responses without hallucinations.
Definitions
RAG: Retrieval-Augmented Generation — a framework that combines retrieval of relevant information with language generation to answer queries.
LlamaIndex: A toolset offering modules and abstractions to streamline retrieval, synthesis, and optimization in RAG applications.
Advantages of Building Production-Grade RAG
1. Decoupling Retrieval and Synthesis Chunks
Motivation: Optimal chunks for retrieval might differ from those ideal for synthesis due to biases, filler information, or inadequate context.
Key Techniques:
- Embedding document summaries linked to associated chunks.
- Embedding sentences linked to context windows for precise retrieval.
Resources: Recursive Retriever + Query Engine Demo, Document Summary Index, Metadata Replacement + Node Sentence Window.
2. Structured Retrieval for Larger Document Sets
Motivation: Standard RAG stacks struggle with scaling for numerous documents, leading to imprecise retrievals.
Key Techniques:
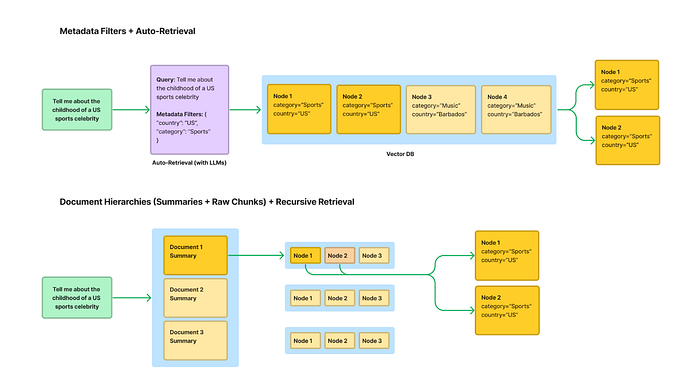
- Metadata Filters + Auto Retrieval: Tag documents with metadata, enhancing precision but limited by defined tags.
- Store Document Hierarchies: Embed summaries and map chunks per document for semantic lookups but potentially expensive.
Resources: Auto-Retrieval from a Vector Database, Comparing Methods for Structured Retrieval, Recursive Retriever + Document Agents.
3. Dynamic Chunk Retrieval Based on Task
Motivation: RAG should cater to diverse queries beyond fact-based ones, requiring varied retrieval techniques.
Key Techniques:
- Utilize LlamaIndex modules like router, data agent, query engine for joint question-answering, summarization, and structured/unstructured query combinations.
Resources: Query engine, Agents, Router, Joint QA Summary Query Engine, OpenAI Agent Query Planning.
4. Optimizing Context Embeddings
Motivation: Embeddings must capture relevant data properties, necessitating fine-tuning for specific use cases.
Key Techniques:
- Fine-tune embedding models for label-free optimization over unstructured text corpus.
Resources: Guides for Embedding Model Fine-Tuning.

Code Implementation with LlamaIndex
For implementing these strategies with LlamaIndex, detailed guides and resources are available, outlining the use of various modules, query engines, agents, and optimization techniques tailored for production-grade RAG applications.
Achieving optimal performance and scalability in RAG applications demands a nuanced approach, leveraging techniques that decouple retrieval and synthesis, enable structured retrieval, cater to diverse queries, and optimize context embeddings. Utilizing LlamaIndex tools and techniques empowers developers to create robust and high-performing RAG systems capable of handling complex knowledge bases efficiently.
As the RAG landscape evolves, ongoing exploration and adaptation of these techniques will be pivotal in maintaining and enhancing the performance of production-grade RAG systems.

Step 1: Install Libraries
%%capture
!pip install llama-index >> null
!pip install openai >> null
!pip install pypdf >> null # for reading PDF files
!pip install docx2txt > null # for reading MS doc filesStep 2: Import Libraries
import os
import openai
import logging
import sys
from pprint import pprint
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
from llama_index import (
VectorStoreIndex,
SimpleDirectoryReader,
load_index_from_storage,
StorageContext,
ServiceContext,
Document
)
from llama_index.llms import OpenAI
from llama_index.node_parser import SentenceWindowNodeParser, HierarchicalNodeParser, get_leaf_nodes
from llama_index.text_splitter import SentenceSplitter
from llama_index.embeddings import OpenAIEmbedding, HuggingFaceEmbedding
from llama_index.schema import MetadataMode
from llama_index.postprocessor import MetadataReplacementPostProcessor
#Setup OPEN API Key
openai_key = "" #<--- Your API KEY
openai.api_key = openai_keyStep 3: Fetch Data and Store into local directory
# create local directory and retrieve file from external source
!mkdir -p 'my_data'
!wget 'https://www.gutenberg.org/cache/epub/72306/pg72306.txt' -O './my_data/teahistory.txt'
!wget 'https://www.gutenberg.org/cache/epub/11367/pg11367.txt' -O './my_data/chinahistory.txt'Step 4 : Load Data and inspect the documents
documents = SimpleDirectoryReader("./my_data/").load_data()
# Inspect the documents
print("length of doc: "+ str(len(documents)))
print("----")
pprint(documents)Step 5: Node Parsing & Indexing (Base & Sentence Window Method)
# create the sentence window node parser w/ default settings
sentence_node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text"
)
base_node_parser = SentenceSplitter()
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
nodes = sentence_node_parser.get_nodes_from_documents(documents)
base_nodes = base_node_parser.get_nodes_from_documents(documents)
print("---------")
print("SENTENCE NODES")
print("---------")
print(nodes[100])
print("---------")
print("BASE NODES")
print("---------")
print(base_nodes[100])
---------
SENTENCE NODES
---------
Node ID: dc609cf2-6abe-4029-ac06-6a5c69cd7c94
Text: We have no desire to show that China's history is the most
glorious or her civilization the oldest in the world.
---------
BASE NODES
---------
Node ID: d84f172e-d135-4452-b23d-b6a2665fc33b
Text: This one fact alone demonstrates that the Hsia rejected Chinese
culture and were nationalistic Hun. Thus there were now two realms in
North China, one undergoing progressive sinification, the other
falling back to the old traditions of the Huns. 3 _Rise of the Toba
to a great Power_ The present province of Szechwan, in the west, had
belonged t...Step 6: Store in VectorIndex
ctx_sentence = ServiceContext.from_defaults(llm=llm, embed_model=OpenAIEmbedding(embed_batch_size=50), node_parser=sentence_node_parser)
ctx_base = ServiceContext.from_defaults(llm=llm, embed_model=OpenAIEmbedding(embed_batch_size=50), node_parser=base_node_parser)
sentence_index = VectorStoreIndex(nodes, service_context=ctx_sentence)
base_index = VectorStoreIndex(base_nodes, service_context=ctx_base)
# Save to Persistent Storage
sentence_index.storage_context.persist(persist_dir="./sentence_index")
base_index.storage_context.persist(persist_dir="./base_index")Step 7: Retrieve from Storage
# rebuild storage context
SC_retrieved_sentence = StorageContext.from_defaults(persist_dir="./sentence_index")
SC_retrieved_base = StorageContext.from_defaults(persist_dir="./base_index")
#load index
retrieved_sentence_index = load_index_from_storage(SC_retrieved_sentence)
retrieved_base_index = load_index_from_storage(SC_retrieved_base)Step 8: Create query engine
from llama_index.postprocessor import MetadataReplacementPostProcessor
sentence_query_engine = retrieved_sentence_index.as_query_engine(
similarity_top_k=5,
verbose=True,
# the target key defaults to `window` to match the node_parser's default
node_postprocessors=[
MetadataReplacementPostProcessor(target_metadata_key="window")
],
)
base_query_engine = retrieved_base_index.as_query_engine(
similarity_top_k=5,
verbose=True
)
Step 9: Inference
question = "Something happened in the United States 10 years after the first American ships sailed for China which could have made it more expensive to purchase tea. what happened that year? Try to break down your answer into steps."
base_response = base_query_engine.query(
question
)
print(base_response)
#Output
1. American ships sailed for China in 1784 and brought back a significant amount of Tea.
2. In the following years, additional ships brought even more Tea to the United States.
3. The earliest official record of Tea importation into the United States was made in 1790.
4. Over time, the importation, value, and consumption of Tea in the United States increased.
5. In 1794, the rates of duty on imported Tea were significantly increased, potentially making it more expensive to purchase Tea in the United States.
6. This increase in duty could have had an impact on the cost of purchasing Tea in the United States.
sentence_response = sentence_query_engine.query(
question
)
print(sentence_response)
#Output
Step 1: The first American ships sailed for China in 1784, bringing back 880,000 pounds of Tea.
Step 2: During 1786-87, five other ships brought to the United States over 1,000,000 pounds of Tea.
Step 3: In 1794, the rates of duty levied on tea by the United States were increased by 75 percent on direct importations and 100 percent.
Step 4: Therefore, 10 years after the first American ships sailed for China, in 1794, the rates of duty on tea were increased, which could have made it more expensive to purchase tea in the United States.Step 10: Analysis
So the SentenceWindowNodeParser + MetadataReplacementNodePostProcessor combo is the clear winner here. But why?
Embeddings at a sentence level seem to capture more fine-grained details
for source_node in sentence_response.source_nodes:
print(source_node.node.metadata["original_text"])
print("--------")
# Output
The
first American ship sailed for China in 1784, two more vessels being
dispatched the following year, bringing back 880,000 pounds of Tea.
--------
But in order to stimulate
American shipping these duties were reduced to 8, 13 and 26 cents
respectively, the following year, when imported from Europe in American
vessels, and to 6, 10 and 20 cents when imported direct from China in
the same manner.
--------
--------------
In 1858 the United States Government ordered and received about 10,000
tea-plants from China in Wardian cases in which the seeds were sown just
previous to shipment, many of them germinated during the voyage, the
plants averaging 18 inches in height on their arrival in this country.
--------
The quantity of China and
Japan teas consumed in the whole United Kingdom declining to about
50,000,000 pounds in 1890, although the prices for them were exceedingly
low during that period.
--------
Up to 1856 China tea was the only tea used in the United States, but
during that year a small quantity of Japan teas, consisting of about 50
half-chests, was first received in this country.
--------Step 11: Compare results
import asyncio
import nest_asyncio
nest_asyncio.apply()
from llama_index.evaluation import (
CorrectnessEvaluator,
SemanticSimilarityEvaluator,
RelevancyEvaluator,
FaithfulnessEvaluator,
PairwiseComparisonEvaluator,
)
from collections import defaultdict
import pandas as pd
# NOTE: can uncomment other evaluators
evaluator_c = CorrectnessEvaluator(service_context=eval_service_context)
evaluator_s = SemanticSimilarityEvaluator(service_context=eval_service_context)
evaluator_r = RelevancyEvaluator(service_context=eval_service_context)
evaluator_f = FaithfulnessEvaluator(service_context=eval_service_context)
from llama_index.evaluation.eval_utils import get_responses, get_results_df
from llama_index.evaluation import BatchEvalRunner
max_samples = 30
eval_qs = eval_dataset.questions
ref_response_strs = [r for (_, r) in eval_dataset.qr_pairs]
# resetup base query engine and sentence window query engine
# base query engine
base_query_engine = base_index.as_query_engine(similarity_top_k=2)
# sentence window query engine
query_engine = sentence_index.as_query_engine(
similarity_top_k=2,
# the target key defaults to `window` to match the node_parser's default
node_postprocessors=[
MetadataReplacementPostProcessor(target_metadata_key="window")
],
)
import numpy as np
base_pred_responses = get_responses(
eval_qs[:max_samples], base_query_engine, show_progress=True
)
pred_responses = get_responses(
eval_qs[:max_samples], query_engine, show_progress=True
)
pred_response_strs = [str(p) for p in pred_responses]
base_pred_response_strs = [str(p) for p in base_pred_responses]
evaluator_dict = {
"correctness": evaluator_c,
"faithfulness": evaluator_f,
"relevancy": evaluator_r,
"semantic_similarity": evaluator_s,
}
batch_runner = BatchEvalRunner(evaluator_dict, workers=2, show_progress=True)
eval_results = await batch_runner.aevaluate_responses(
queries=eval_qs[:max_samples],
responses=pred_responses[:max_samples],
reference=ref_response_strs[:max_samples],
)
base_eval_results = await batch_runner.aevaluate_responses(
queries=eval_qs[:max_samples],
responses=base_pred_responses[:max_samples],
reference=ref_response_strs[:max_samples],
)
results_df = get_results_df(
[eval_results, base_eval_results],
["Sentence Window Retriever", "Base Retriever"],
["correctness", "relevancy", "faithfulness", "semantic_similarity"],
)
display(results_df)
Conclusion
In conclusion, optimizing retrieval-augmented generation (RAG) applications for production-grade performance necessitates a strategic blend of techniques and tools. The journey to enhancing these systems involves:
- Decoupling Retrieval and Synthesis Chunks: Recognizing the distinction between optimal retrieval and synthesis chunks, leveraging techniques like embedding document summaries or sentences for precise retrieval.
- Structured Retrieval for Scale: Implementing structured tagging or document hierarchies to address challenges with scaling for larger document sets, ensuring more precise retrievals.
- Dynamic Chunk Retrieval Based on Tasks: Adapting retrieval techniques to accommodate diverse query types, going beyond fact-based inquiries and incorporating modules for joint question-answering and structured/unstructured query combinations.
- Optimizing Context Embeddings: Fine-tuning embeddings to accurately reflect the nuances of specific data sets, refining the model for better retrieval.
LlamaIndex, with its suite of modules and resources, offers a robust toolkit to implement and optimize RAG applications. By leveraging these tools and techniques, developers can craft performant systems capable of effectively handling complex knowledge bases.
The identified winning approach, combining the SentenceWindowNodeParser with the MetadataReplacementNodePostProcessor, stands out due to its ability to capture fine-grained details and facilitate comparisons between retrieved chunks from different indexes.
As the RAG landscape evolves, ongoing exploration and adaptation of these strategies will be pivotal, ensuring the continued advancement and efficiency of production-grade RAG systems. The pursuit of refining retrieval and synthesis processes remains crucial for achieving optimal performance in real-world applications.
Resource:
Stay connected and support my work through various platforms:
- GitHub: For all my open-source projects and Notebooks, you can visit my GitHub profile at https://github.com/andysingal. If you find my content valuable, don't hesitate to leave a star.
- Patreon: If you'd like to provide additional support, you can consider becoming a patron on my Patreon page at https://www.patreon.com/AndyShanu.
- Medium: You can read my latest articles and insights on Medium at https://medium.com/@andysingal.
- The Kaggle: Check out my Kaggle profile for data science and machine learning projects at https://www.kaggle.com/alphasingal.
- Hugging Face: For natural language processing and AI-related projects, you can explore my Huggingface profile at https://huggingface.co/Andyrasika.
- YouTube: To watch my video content, visit my YouTube channel at https://www.youtube.com/@andy111007.
- LinkedIn: To stay updated on my latest projects and posts, you can follow me on LinkedIn. Here is the link to my profile: https://www.linkedin.com/in/ankushsingal/."
- Paypal: Enjoyed my article? Buy me a coffee! https://paypal.me/alphasingal?country.x=US&locale.x=en_US
- Gumroad: rasikasingal.gumroad.com/l/awmrc
Requests and questions: If you have a project in mind that you'd like me to work on or if you have any questions about the concepts I've explained, don't hesitate to let me know. I'm always looking for new ideas for future Notebooks and I love helping to resolve any doubts you might have.
Remember, each "Like", "Share", and "Star" greatly contributes to my work and motivates me to continue producing more quality content. Thank you for your support!
If you enjoyed this story, feel free to subscribe to Medium, and you will get notifications when my new articles will be published, as well as full access to thousands of stories from other authors.