
Imagine designing a new animal. You'd start by gathering requirements: where it will live, what food's available, what predators it must evade, and even consider physics — otherwise, you might create a creature that defies nature.
If the habitat is a dense rainforest, you'd design a small, agile climber with a prehensile tail, strong grip, and sharp vision for spotting fruit. It would excel at swinging through trees and avoiding ground predators. But no matter how much you "optimize" its climbing speed or digestion efficiency, it will never outrun a gazelle on the savanna or survive the arctic cold.
Software architecture works the same way. It defines what's possible. No amount of micro-optimization will break those boundaries unless you fundamentally change the design.
Do Bad Designs Really Exist?
Yes, bad designs definitely exist. But more often, I see software that simply wasn't designed at all — built just to "make it work." It might be organized, but that doesn't mean it's well designed or built with the bigger picture in mind. Most of the time, that's fine because computers are fast, and many design flaws stay hidden — until that unplanned architecture inevitably hits its performance limit.
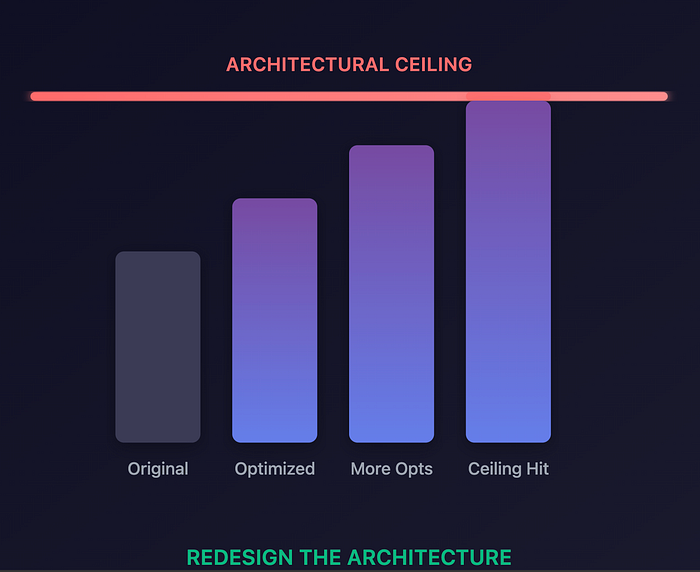
But how do these design limits show up? What does it actually look like when a system hits its architectural ceiling — and how is that different from just spotting a simple performance improvement opportunity?
Spotting The Ceiling
Looking at the profile data below, you've probably noticed that getShard stands out as a prime candidate for optimization, right? And without understanding the design, you'd be right — it could be faster. After all, as a method to distribute load to shards, it could potentially achieve near-perfect distribution in a simpler and more efficient way. But the real purpose of getShard isn't raw speed; it's to minimize contention. The true bottleneck in this design lies in managing contention, and getShard exists to keep that as low as possible.
Note — How to Spot Your Ceiling This is the call stack for
Get:Get⇒getShard⇒retrieveFromShard1.getShardcalls runtime functions we don't control, possible bottleneck. 2.retrieveFromShardis pure atomic operations, also outside our control. So which is it? The one you can't meaningfully change. I could completely changegetShardfor a different load distribution method, but I can't alterretrieveFromShardsince I chose to use atomics. If there's no direct changes and only work arounds, that's your bottleneck.
flat flat% cum% function
0.15s 0.05% 98.06% testing.(*B).RunParallel.func1
3.51s 1.26% 97.51% BenchmarkGenPool.func1
36.62s 13.12% 49.01% ShardedPool.Put
30.83s 11.04% 44.75% ShardedPool.Get
76.68s 27.47% 33.62% ShardedPool.getShard
3.92s 1.40% 17.12% atomic.Pointer.CompareAndSwap (inline)
43.86s 15.71% 15.71% atomic.CompareAndSwapPointer
17.32s 6.20% 14.96% ShardedPool.retrieveFromShard
14.93s 5.35% 5.38% cleaner
10.90s 3.90% 3.90% Fields.SetNext
10.90s 3.90% 3.90% atomic.Pointer.Store (inline)
10.89s 3.90% 3.90% atomic.StorePointer
9.34s 3.35% 3.35% runtime.procPin
7.70s 2.76% 2.76% runtime.procUnpin
6.89s 2.47% 2.48% testing.(*PB).Next (inline)
6.70s 2.40% 2.40% atomic.Int64.Add
2.35s 0.84% 0.84% atomic.Pointer.Load (inline)You may be thinking to yourself, isn't near perfect distribution alone good enough as a way to manage contention ? yes, it kinda of is, without distribution performance is at 182ns, with distribution is goes down to 10ns, so based on that alone you could probably stop right ? what kinda of maniac would be chasing more nanosecons after that.
Chasing Nanoseconds
By understanding your design and its ceiling, you can make optimizations that truly improve the overall system. When you're close to that ceiling, optimizing individual functions without considering the design often just pulls you away from your design's maximum potential.
Real World Example
Of the three functions below, getShardByStackAddr is the fastest, yet the system still plateaus at ~10ns per call. At that point, making getShard even faster doesn't help — but slowing it down in favor of a more robust load distribution can actually cut latency from 10ns to 3ns.
Profiling reveals that getShard using runtimeProcPin() takes longer overall (188.83s total, with 55.38s spent inside the function — about 37% of runtime), while the stack address hashing version (getShardByStackAddr) is much cheaper (238.81s total, but only 13.55s inside the function — about 5.7%).
So, how could a slower function actually improve system performance?
func (p *ShardedPool[T, P]) getShardByProcPin() (*Shard[T, P], int) {
// Pin the current goroutine to its underlying OS thread and get the
// processor ID assigned to the thread (runtimeProcPin returns a unique
// ID representing the current logical processor).
id := runtimeProcPin()
// Unpin the goroutine immediately so the scheduler can move it again.
// In practice, most of the time the goroutine remains pinned to the same
// logical processor until it finishes executing, which helps with locality.
runtimeProcUnpin()
// Use the processor ID modulo number of shards to pick the shard.
// This evenly distributes shards across logical processors, while
// benefiting from a lot of cache locality.
return p.Shards[id%numShards], id
}
func (p *ShardedPool[T, P]) getShardByStackAddr() (*Shard[T, P], int) {
// Create a local dummy variable on the stack to get its address.
var dummy byte
// Convert the address of the dummy variable to an integer.
// Since stack addresses are somewhat unique per goroutine,
// this acts as a pseudo-unique identifier for the current goroutine.
addr := uintptr(unsafe.Pointer(&dummy))
// Shift right to ignore the lower bits of the address, which are mostly
// padding with low entropy, and then mask with (numShards - 1) to get
// a shard index within bounds.
id := int(addr >> 12) & (numShards - 1)
// Return the shard corresponding to this computed id.
return p.Shards[id], id
}
func (p *ShardedPool[T, P]) getShardByPinnedStack() (*Shard[T, P], int) {
// Lock the current goroutine to its OS thread so its stack
// address stays consistent throughout this function.
runtime.LockOSThread()
defer runtime.UnlockOSThread()
// Create a local dummy variable on the stack to get its address.
var dummy byte
// Convert the dummy's address to an integer.
addr := uintptr(unsafe.Pointer(&dummy))
// Similar to getShardByStackAddr, use shifted and masked address bits
// to select a shard index, relying on consistent stack placement
// due to OS thread pinning.
id := int(addr >> 12) & (numShards - 1)
// Return the selected shard.
return p.Shards[id], id
}If you look closely at getShardByProcPin, it achieves two key goals in one step: it evenly distributes load across shards and ensures each logical processor consistently maps to the same shard—or the same set of shards if there are more shards than processors. This takes advantage of cache locality at both Go's runtime level and the CPU level, cutting latency from ~10ns to ~3ns.
By comparison, getShardByStackAddr is faster per call but only handles load distribution, while getShardByPinnedStack aims to mimic getShardByProcPin but runs about three times slower.
The takeaway: once you know where the true bottleneck lies, you can pull control back into your own code and design around it to ease its cost.
Hitting the Ceiling
Once latency is down to ~3ns, further gains require understanding every design choice and its limits. The question "How can we optimize this function?" must evolve into:
- If this function is maxed out, where does the load shift next?
- If every function in the critical path is optimized, which part of the system becomes the bottleneck?
If that bottleneck lives in places we can't directly change — e.g., the Go runtime or synchronization primitives like channels — then micro-optimizations won't help. At that point, we either pull control back into our own code or revisit the architecture to push the ceiling higher.
Rule of Thumb: When you catch yourself thinking "There's nothing I can do here," you've likely found the true bottleneck. This isn't the end — it's a cue to shine a light on it and find creative ways around it.
Conclusion
1. If performance is your goal, the system's design will determine most of it. Micro-optimizations mainly help to refine and squeeze out extra efficiency, but the real gains come from solid architectural choices.
2. Once you understand your design and its performance ceiling, make sure to document it clearly. It's easy for another developer to profile the same code, see opportunities for "simplification," and unintentionally make things worse by ignoring the original design rationale.
3. Architectural decisions always involve trade-offs, and the key factor guiding which trade-offs you make is your system's requirements, make sure you collect those.
4. Find a way to measure how close you are to your design's limits — once you know that, it becomes much easier to identify and implement further improvements, or to recognize when no meaningful improvement is possible.
Check more of my work on: