
To sustain my work, I've enabled the Medium paywall. If you're already a Medium member, I deeply appreciate your support! But if you prefer to read for FREE, my newsletter is open to you: vutr.substack.com. Either way, you're helping me continue writing!
Intro
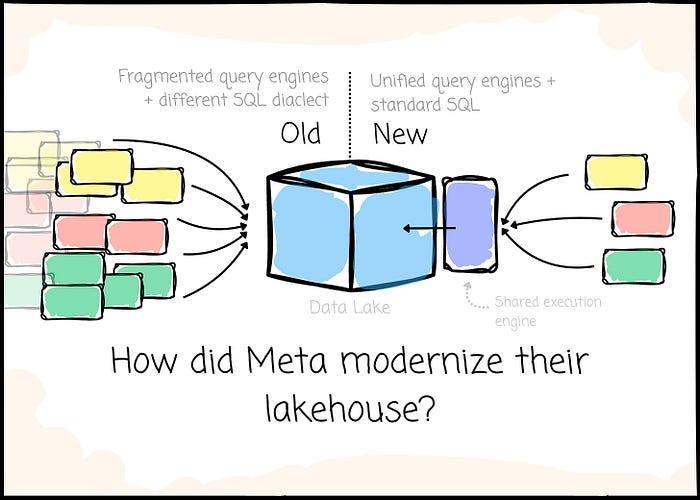
In this article, we will explore how Meta, one of the world's biggest tech companies, re-architected its data lakehouse. The texts you'll read will not cover detailed components of the Meta lakehouse. Instead, we will see how Meta's initial approach caused them troubles and their effort to fix them at the organizational scale.
For this article, I referred to material from the Meta paper released in 2023 called Shared Foundations: Modernizing Meta's Data Lakehouse.
The initial approach and its problems
Meta started their data journey about +20 years ago.
They started implementing the paradigm of bringing the query engines to the data stored in object storage with Hive in 2010. It was eleven years before Databricks released the paper introducing the lakehouse architecture.
Since then, Meta's warehouse system has grown from tens to hundreds of petabytes, and in 2023, it reached multiple exabytes. With Hive, the Meta high-level warehouse solution can be described as below:
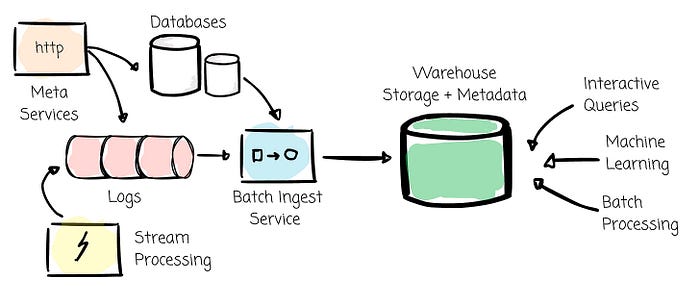
- They managed data, metadata, and computing independently.
- They stored data in HDFS, which let them scale the storage layer independently from the computing layer. In recent years, Meta has replaced HDFS with an in-house file system called Tectonic, which helped them achieve operational efficiency.
- They stored metadata in the MySQL database. With Hive, users can store partition information in the Hive Metastore.
- They store data in a columnar format. They first created the RC file and later enhanced it to create ORC. They also developed an ORC variant called DWRF to support nested data and encryption better.
- Internal users can bring their favorite compute engine to join the party. From Spark, Presto to Meta deployment of Giraph — an iterative graph processing system.
However, this architecture caused Meta some problems:
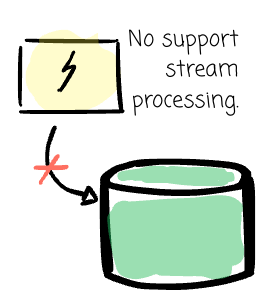
- This architecture did not support stream processing. This made Meta build various streaming systems over time, and of course, they were not so well integrated with Hive.
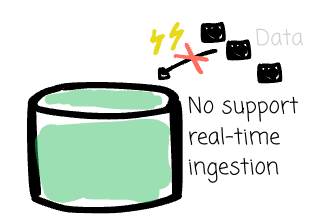
- The architecture did not support real-time data ingestion to Hive. They ended up using Scuba for this purpose, although it was initially built for log analytics.
- There were a lot of programming languages. Most of the data stack in Meta was written in Java, but most of the other systems in Meta use C++. Java is also not primarily supported at Meta.

- Hive was too slow for interactive queries. Meta had to create new engines to address this problem. They wrote some in Java and some in C++. Even though some engines were written in the same language, they did not share any components, resulting in solution fragmentation.
- At first, Meta stored data in HDFS storage nodes, mostly using HDD for local disks. For interactive queries, fetching data from HDD over the network is slow. Meta had to develop many interactive query engines that had compute and storage tightly coupled to improve query latency. This caused the solution fragmentation and data deuplication to become more serious.
- The fragmentation did not stop there. At Meta, there were at least six SQL dialects, three implementations of Metastore client and ORC codecs, about twelve different engines targeting similar workloads, and many copies of the same data in various locations and formats.
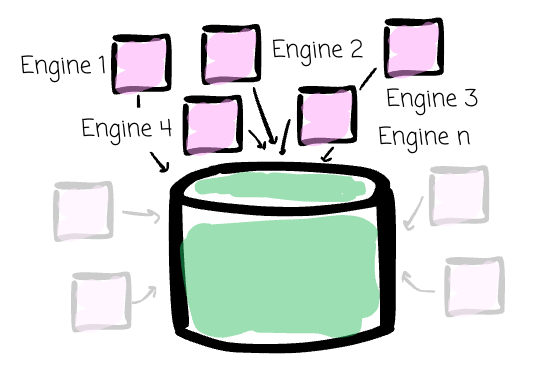
Meta lacked the standardization and reusable components. The engineers got more operational burden. The users had to interact with different SQL dialects and suffer inconsistent semantics.
They couldn't put the most effort into innovation.
The new paradigm shift
So, how did Meta solve those problems?
They started an effort on an organizational scale, which Meta called the Shared Foundations. The purpose is to re-architect the data lakehouse.
The Shared Foundations program involves hundreds of engineers throughout Meta. The program has the following principles:
- Using fewer systems: Many systems that serve the same use cases with overlapping functionality should be merged into one system. For example, Meta aimed to have a single query engine for each area: batch, streaming, interactive, and machine learning.
- Reusable components: Meta can still provide different compute engines if use cases and requirements are distinct. They focused on reusing as many components as possible for these cases. For example, interactive and batch engines can share the storage encodings or data formats.
- Consistent APIs can lower the learning curve for users and make the integration of components more straightforward. Thus paving the way for modularization and reusability.
With these principles, Meta aimed to achieve:
- Engineering efficiency: Their engineers can work on a smaller number of systems. These principles also reduced duplication and prevented them from re-inventing the wheel.
- Faster innovation: Having fewer systems means less operational burden. This allows Meta to focus on new features and other improvements.
- Better user experience: End users can expect consistent syntax, features, and semantics across systems, lowering the barrier to using these systems and increasing productivity.
Meta implemented the Shared Foundations in areas such as storage, metadata, execution, language, and engine.
Compute Engine
As mentioned, internal teams built different query engines to adapt to different workloads and performance requirements.
Presto, Raptor, Cubrick and Scuba for interactive queries.
Presto and Spark for batch execution.
Puma, Stylus, XStream, and MRT for stream processing.
Let's dive into each area.
For the interactive engines, the ideal one would have the best features from Presto, Raptor, Cubrick, and Scuba. This engine should provide:
- Full SQL support, complex queries, and data models.
- The ability to process data directly on the lakehouse.
- Low latency performance is achieved by managing data in memory or SSD.
- Supporting for real-time data.
In the end, Meta built the convergence engine based on Presto because it provides most of the requirements above. Meta compensated the performance gap between Presto and other interactive systems through local caching.
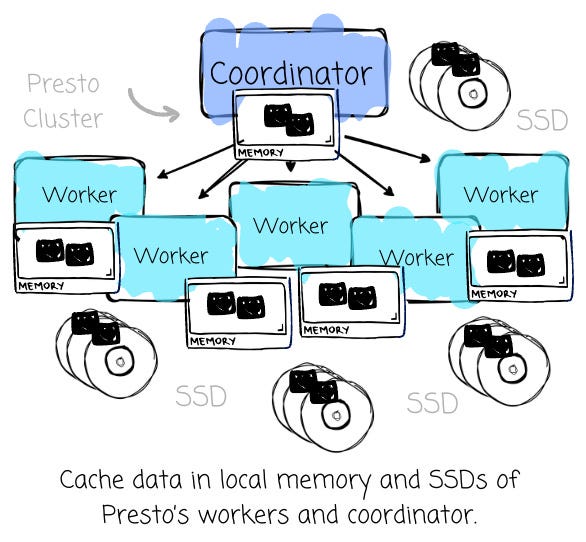
They developed the smart hierarchical caching mechanism, which stored the most frequently used data and metadata in the local memory and SSDs of Presto's workers and coordinator.
This mechanism helps improve the order of magnitude of the latency of most of Meta's common interactive query patterns. This speedup even exceeded the performance of existing systems, which use less hardware.
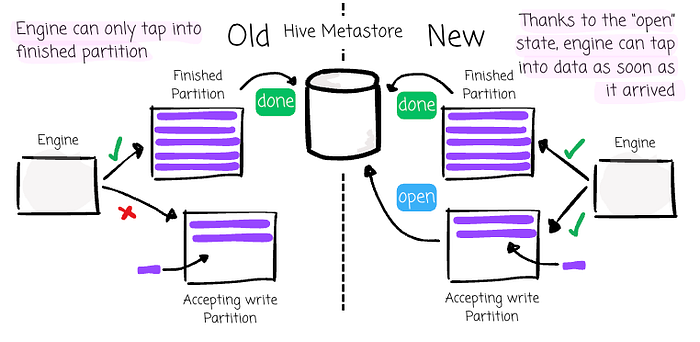
Although Presto can query directly near real-time data on Hive, the engine can only tap into real-time data partitions once all the partition's data is available. A Hive partition typically has hourly or daily partitions, limiting the near-real-time capability.
To address this, Meta introduced the open partition state in the Hive Metastore as the systems could register the partitions as soon as the data arrived. Presto can now access data immediately after it lands in the storage layer.
Meta took two years to migrate all workloads from other interactive systems to Presto. When migrating queries to a Presto, Meta had to address the syntactic incompatibilities and implement the functions mapping between old systems and Presto, which is flexible to allow Meta to map all queries to supported Presto queries.
Because systems like Raptor, Cubrick, and Scuba load data from the lakehouse, the data migration was not a challenge, as users can use Presto to load the data from the lakehouse. At the end of the migration, Meta completely deprecated Raptor and Cubrick, saving several hundred thousand lines of code and several thousand machines.
For the batch engines, Meta also decided to migrate most of the batch pipelines to Presto.
Meta created the Hive engine for all batch processing in late 2000 and later replaced it with SparkSQL. When migrating to Presto, Meta faced a problem in which Presto's architecture at that time was insufficiently resilient to machine failures compared to Spark when executing long-running pipelines.

They solve this problem by combining the scalability of the Spark engine with the cleaner standards-compliant SQL called PrestoSQL, which resulted in Presto on Spark. The solution achieved this by refactoring the Presto front-end (parser, analyzer, optimizer, planner) and backend (evaluation and I/O) libraries and embedding these in the Spark driver and worker.

With interactive queries already ran on Presto, Presto on Spark offers 100% compatibility with PrestoSQL; users can switch from interactive queries to batch pipelines without needing to rewrite the queries.
At Meta, Presto on Spark is currently in production and running thousands of pipelines daily.
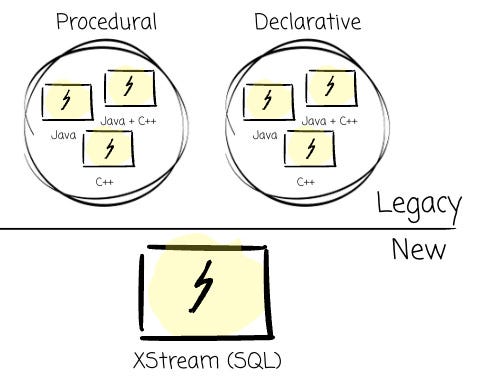
There were also fragmented solutions in the streaming engines. The two main reasons were:
- Programming language divergence (C++ vs. Java vs. PHP).
- The abstraction level divergence (low-level procedural vs. high-level declarative API)
The legacy stacks had Puma (Java, declarative), Stylus (C++, low level), and others with different combinations of abstraction levels (declarative, procedural) and implementation languages (C++, Java, PHP).
To deal with this, Meta built XStream, the next generation of stream processing platform. Meta promoted SQL as the primary way to interact with XStream by integrating with the CoreSQL. They also made it more efficient with a Velox-based execution engine.
We will expore CoreSQL and Velox later.
XStream today supports various use cases from SQL queries and machine learning workloads to function as a service.
SQL Dialect
Meta had more than six variants of SQL being used internally. If users wanted to use different systems, there was a high chance that they had to learn a different SQL dialect. Meta decided to narrow it down to two dialects: MySQL and PrestoSQL. The first is for OLTP workloads, and the latter for OLAP workloads.
However, Meta found it challenging to achieve compatibility across the different engines. They looked around and found that the way Google achieved the same purpose with ZetaSQL could help them; they needed two components:
- The SQL parser and analyzer for parsing and analyzing queries plus creating and validating query plans. Meta already had a Java implementation (Presto) and a Python implementation (used by developer tools). They rewrote the Python implementation in C++ for better performance and better integration with the C++ engines. They are working to bind Java implementation to the C++ library.
- A library of query functions and operators. Meta initially reused the Java implementation from Presto and tried to replace it with the Velox engine to maximize the performance. We will explore Velox in the Execution Engine section.
Meta called this solution CoreSQL. It acts as the standard dialect across engines, from Presto to XStream.
Storage
Meta used ORC as the columnar format for the lakehouse. Later, they developed DWRF, the ORC variant to support better deeper nested data and finer grained encryption. Meta has fragmented codec implementation for this format: one Java implementation of Spark, one Java implementation for Presto, and one C++ implementation for ML applications.
Because of its higher performance, Meta chose the Presto codec as the base one and added necessary features to it. Then, they migrated all codecs used in Spark and other systems to the new one. In addition, Meta refactored the DWIO library into Velox, added some features, and open-sourced the library as part of Velox.
Execution Engine
Like all the areas above, the lakehouse's evolution created fragmentation in the execution engines. More than twelve specialized engines that shared little to nothing with each other were written in different languages and developed by different teams.
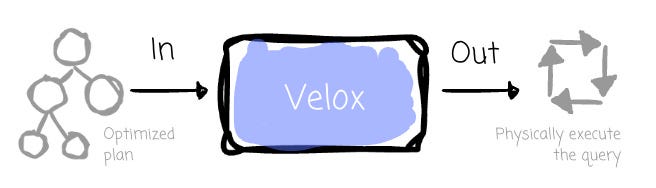
To address this challenge, Meta created Velox, a C++ database acceleration library (think Databricks's Photon in the case of Spark). Velox aimed to unify execution engines across different compute engines.
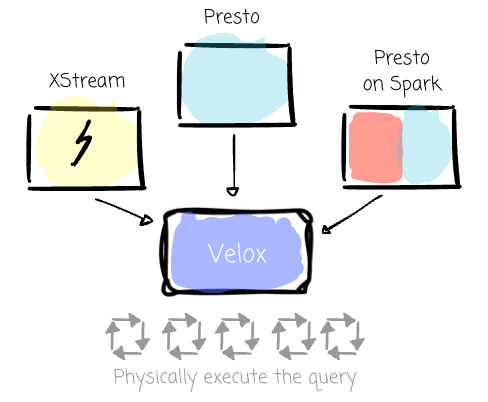
Typically, Velox receives the fully optimized query plans and performs the computation using the resources in the local machine.
As Meta claimed, Velox democratizes the optimizations that are only found in individual engines, which reduces duplication, offers reusability, and improves consistency.
At the time of the paper's release, Meta integrated Velox into many systems. Meta also provided the implementation of the CoreSQL dialect for Velox.
Outro
Thank you for reading this far
In this article, we explored the limitations of Meta's legacy approach for their lakehouse, how they addressed them with the Shared Foundations, and how they implemented it in different areas from the compute engine, SQL dialect, and storage format to the execution engine.
Now, it's time to say goodbye. See you in the next articles.
Reference
[1] Biswapesh Chattopadhyay, Pedro Pedreira, Sameer Agarwal, Yutian "James" Sun, Suketu Vakharia, Peng Li, Weiran Liu, Sundaram Narayanan, Shared Foundations: Modernizing Meta's Data Lakehouse (2023)