


You might be wondering, why would anyone execute kill 1 or kill -9 1 inside a container? This question actually came up from one of our team members.
The situation was as follows: the team member wanted to fix a bug in the container image, but due to network configuration issues, he didn't want to change the pod IP by rebuilding the pod. If you've used Kubernetes, you know there isn't a restart pod command available. Given this, it seemed like the only option was to restart the pod in place. My first thought was to use the kill pid 1 method to restart the container.
When we run kill 1 and kill -9 1 inside the container, the results are as follows:
[root@5cc69036b7b2 /]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 07:23 ? 00:00:00 /bin/bash /init.sh
root 8 1 0 07:25 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 100
root 9 0 6 07:27 pts/0 00:00:00 bash
root 22 9 0 07:27 pts/0 00:00:00 ps -ef
[root@5cc69036b7b2 /]# kill 1
[root@5cc69036b7b2 /]# kill -9 1
[root@5cc69036b7b2 /]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 07:23 ? 00:00:00 /bin/bash /init.sh
root 9 0 0 07:27 pts/0 00:00:00 bash
root 23 1 0 07:27 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 100
root 24 9 0 07:27 pts/0 00:00:00 ps -efWhen we complete the previous operations, we find that running either kill 1 (corresponding to the SIGTERM signal in Linux) or kill -9 1 (corresponding to the SIGKILL signal in Linux) does not terminate the process.
So, the question arises: why do these two signals, commonly used to terminate processes, not affect the init process inside the container?
To explain this, we need to delve into the two fundamental concepts of containers — init processes and Linux signals.
Understanding the init process
In an ideal world, each container runs a single process. However, in reality, this isn't always feasible. For instance, alongside the main process, you might need to run auxiliary processes within a container for tasks such as monitoring or log rotation. Another example is migrating applications from virtual machines (VMs) to containers, where the original applications are inherently multi-process.
When multiple processes are started within a container, the container will have a process with PID 1, often referred to as the "init process" or "process 1". This init process will be responsible for creating other child processes.
Let's break down how the init process comes into being:
- Booting the System: When a Linux system powers on and completes BIOS/boot-loader execution, the boot-loader is responsible for loading the Linux kernel. The kernel executable is typically located in the
/bootdirectory with filenames likevmlinuz*. - Kernel Initialization: After the kernel completes various system initializations, it needs to execute the first user-space program, which is the init process.
- Starting the Init Process: When the kernel starts the process with PID 1, it attempts to execute the init process from several default paths if no external parameter specifies the program path. These default paths are common Unix executable paths.
- Transition to User Space: The system starts by running kernel-space code, then calls the init process code, transitioning from kernel space to user space.
In most mainstream Linux distributions today, whether based on RedHat or Debian, /sbin/init is a symbolic link pointing to Systemd. Systemd is the most popular Linux init process currently, but there have been others like SysVinit and UpStart in the past.
Regardless of the specific init process used, its primary role is to create and manage all other processes in the Linux system. Here's a look at how this is implemented in the kernel code:
init/main.c
/*
* We try each of these until one succeeds.
*
* The Bourne shell can be used instead of init if we are
* trying to recover a really broken machine.
*/
if (execute_command) {
ret = run_init_process(execute_command);
if (!ret)
return 0;
panic("Requested init %s failed (error %d).",
execute_command, ret);
}
if (!try_to_run_init_process("/sbin/init") ||
!try_to_run_init_process("/etc/init") ||
!try_to_run_init_process("/bin/init") ||
!try_to_run_init_process("/bin/sh"))
return 0;
panic("No working init found. Try passing init= option to kernel. "
"See Linux Documentation/admin-guide/init.rst for guidance.");
$ ls -l /sbin/init
lrwxrwxrwx 1 root root 20 Feb 5 01:07 /sbin/init -> /lib/systemd/systemdIn Linux, once the concept of containers was introduced, each container can establish its own PID namespace. Within this namespace, process numbers also start from 1. Therefore, the container's init process is also referred to as the process with PID 1.
How about that, isn't the concept of the init process pretty straightforward? Here's what you need to remember about this point: the init process is the first user-space process, and it directly or indirectly creates all other processes within the namespace.
Understanding Linux signals
What I just told you about the init process and the concept of the PID 1 in containers leads us to the question of why we cannot kill the PID 1 process inside a container. To answer this, we need to understand the role of the kill command.
When we run the kill command, we are actually sending a signal in Linux. But what exactly is a signal? This concept dates back to the early days of Unix systems. Signals are typically numbered from 1 to 31, and these numbers are the same across all Unix systems.
In Linux, we can use the kill -l command to see a list of these signal numbers and their names. Here are the signal numbers and names:
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYSIn summary, a signal is a notification sent to a Linux process, which can come from various sources and can be of different types. For example:
- Pressing "Ctrl+C" sends a SIGINT signal to the current process, causing it to exit.
- Memory access errors can generate a SIGSEGV signal.
- Using the
killcommand sends a signal to a process, with SIGTERM (15) being the default signal for termination and SIGKILL (9) for immediate termination.
Processes can handle signals in three ways:
- Ignore: The process ignores the signal, except for SIGKILL and SIGSTOP, which cannot be ignored.
- Catch: The process can register a handler to deal with the signal. SIGKILL and SIGSTOP cannot be caught and will execute their default behavior.
- Default: The signal triggers the default behavior defined by the Linux system.
Most signals do not require the process to register a handler, and the default behavior is sufficient.
SIGTERM (15) and SIGKILL (9) are the two signals I focused on today. Now that we've discussed the concept of signals and how they're handled, let's analyze these two signals in more detail.
First, let's look at SIGTERM (15), which is the default signal sent by the Linux kill command. In the example earlier, the command kill 1 sends a signal to process 1, and when no other parameters are specified, this signal defaults to SIGTERM.
SIGTERM can be caught, meaning that a user process can register its own handler for this signal. Later, we'll see how this handler can deal with graceful shutdown of processes.
Now, let's understand SIGKILL (9), which is one of the privileged signals in Linux. What are privileged signals? As mentioned earlier, privileged signals are reserved for the kernel and superuser to terminate any process. They cannot be ignored or caught. When a process receives SIGKILL, it must terminate.
In the example command kill -9 1, the parameter "-9" specifies sending the SIGKILL signal with the signal number 9 to process 1.
Explaining the problem phenomenon
Now that you understand the concepts of the init process and Linux signals, let's revisit the original question: "Why can't I kill the init process in a container, even with the SIGKILL signal?"
As we tried at the beginning of the article, using bash as the container's init process, it was impossible to kill the 1st process. Now, let's see if a init process written in a different programming language can be killed.
Let's use a C program as the init process and try to kill the 1st process. Similar to the bash init process, regardless of whether it's a SIGTERM signal or a SIGKILL signal, you can't kill this 1st process inside the container.
#include <stdio.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
printf("Process is sleeping\n");
while (1) {
sleep(100);
}
return 0;
}
[root@5d3d42a031b1 /]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 07:48 ? 00:00:00 /c-init-nosig
root 6 0 5 07:48 pts/0 00:00:00 bash
root 19 6 0 07:48 pts/0 00:00:00 ps -ef
[root@5d3d42a031b1 /]# kill 1
[root@5d3d42a031b1 /]# kill -9 1
[root@5d3d42a031b1 /]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 07:48 ? 00:00:00 /c-init-nosig
root 6 0 0 07:48 pts/0 00:00:00 bash
root 20 6 0 07:49 pts/0 00:00:00 ps -efNow, can we conclude that "the init process in the container completely ignores the SIGTERM and SIGKILL signals"? Hold on, let's try another language.
Next, let's use a Golang program as the 1st process. We'll then execute kill -9 1 and kill 1 in the container.
This time, we find that the kill -9 1 command still cannot kill the 1st process, which means that the SIGKILL signal does not work, similar to the previous two tests.
However, when we execute kill 1, the SIGTERM signal kills the init process, and the container exits.
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("Start app\n")
time.Sleep(time.Duration(100000) * time.Millisecond)
}
[root@234a23aa597b /]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 1 08:04 ? 00:00:00 /go-init
root 10 0 9 08:04 pts/0 00:00:00 bash
root 23 10 0 08:04 pts/0 00:00:00 ps -ef
[root@234a23aa597b /]# kill -9 1
[root@234a23aa597b /]# kill 1
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMESFor the test results, are you feeling even more confused? Why do the results differ when using different programs? Next, let's see what happens in Linux after the kill command is issued. I'll systematically explain the whole process.
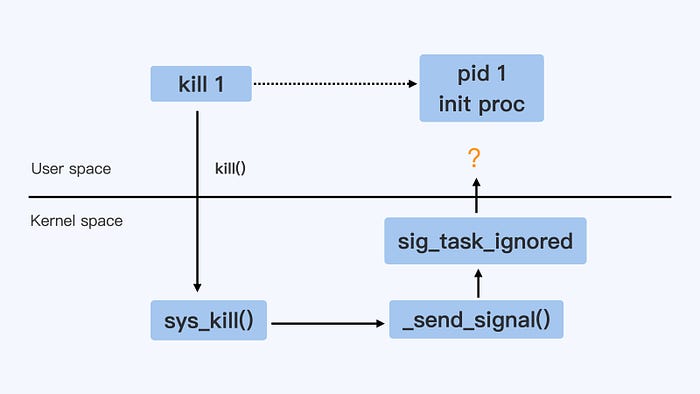
When we run the kill 1 command, we want to send the SIGTERM signal to the process with ID 1, as shown by the dashed arrow in the diagram below.
In the Linux implementation, the kill command invokes the kill() system call (a system call is an interface for the kernel's functions) and enters the kernel function sys_kill(), as indicated by the solid arrow in the diagram.
When the kernel decides to send the signal to the process with ID 1, it calls the sig_task_ignored() function to make a decision. Why is this decision important?
It determines under what circumstances the kernel will ignore the sent signal. If the signal is ignored, the init process cannot receive the instruction.
Therefore, to understand why the init process receives or does not receive a signal, we need to look at the implementation of the sig_task_ignored() kernel function.
In the sig_task_ignored() function, there are three if{} statements. The first and third if{} statements are not relevant to our problem, and the code has comments, so we won't discuss them.
Let's focus on the second if{} statement. I'll analyze whether the three sub-conditions inside this if{} statement can be satisfied when executing kill 1 or kill -9 1 in a container.
Here is the code snippet. It indicates that if all three sub-conditions are satisfied, the signal will not be sent to the process.
// kernel/signal.c
static bool sig_task_ignored(struct task_struct *t, int sig, bool force)
{
void __user *handler;
handler = sig_handler(t, sig);
/* SIGKILL and SIGSTOP may not be sent to the global init */
if (unlikely(is_global_init(t) && sig_kernel_only(sig)))
return true;
if (unlikely(t->signal->flags & SIGNAL_UNKILLABLE) &&
handler == SIG_DFL && !(force && sig_kernel_only(sig)))
return true;
/* Only allow kernel generated signals to this kthread */
if (unlikely((t->flags & PF_KTHREAD) &&
(handler == SIG_KTHREAD_KERNEL) && !force))
return true;
return sig_handler_ignored(handler, sig);
}Next, let's analyze these three sub-conditions one by one. Let's start with !(force && sig_kernel_only(sig)).
The first part of the condition, force, is always 0 for signals sent within the same namespace. Therefore, this part of the condition is always satisfied.
Now, let's consider the second part, handler == SIG_DFL.
What is SIG_DFL? For each signal, if a user process does not register its own handler, there is a default system handler called SIG_DFL.
For SIGKILL, as we mentioned earlier, it is a privileged signal that cannot be caught, so its handler is always SIG_DFL. Therefore, this second condition is always satisfied for SIGKILL.
For SIGTERM, it can be caught. This means that if the user does not register a handler, this condition is also satisfied for SIGTERM.
Lastly, let's look at the third condition, t->signal->flags & SIGNAL_UNKILLABLE. This condition checks if the process is SIGNAL_UNKILLABLE.
Where is the SIGNAL_UNKILLABLE flag set? You can refer to the code snippet below. When the init process is established in each namespace, the SIGNAL_UNKILLABLE flag is set. This means that any process with PID 1 will have this flag set, so this condition is also satisfied.
kernel/fork.c
if (is_child_reaper(pid)) {
ns_of_pid(pid)->child_reaper = p;
p->signal->flags |= SIGNAL_UNKILLABLE;
}
/*
* is_child_reaper returns true if the pid is the init process
* of the current namespace. As this one could be checked before
* pid_ns->child_reaper is assigned in copy_process, we check
* with the pid number.
*/
static inline bool is_child_reaper(struct pid *pid)
{
return pid->numbers[pid->level].nr == 1;
}It can be seen that the key point is actually handler == SIG_DFL. The Linux kernel ignores signals with only a default handler for the init process in each namespace. If we register a signal handler ourselves (registering a signal handler in an application is called "Catch the Signal"), then the signal handler is no longer SIG_DFL. Even the init process can exit after receiving SIGTERM if it has a custom signal handler.
However, since SIGKILL is a special case and is not allowed to have a registered user handler (another signal that does not allow registered user handlers is SIGSTOP), it only has the SIG_DFL handler. Therefore, the init process can never be killed by SIGKILL but can be killed by SIGTERM.
Now, how can we verify this? We can do the following two things to validate this:
Firstly, you can check the SigCgt Bitmap in the status of the PID 1 process.
In a Golang program, many signals have registered their own handlers, including SIGTERM(15), which is bit 15.
In a C program, by default, no signal handler is registered. In a bash program, two handlers are registered, bit 2 and bit 17, which are SIGINT and SIGCHLD, but not SIGTERM.
Therefore, in C programs and bash programs, the handler for SIGTERM is SIG_DFL (default behavior), so they cannot be killed by SIGTERM.
You can check the process status in the /proc system:
### golang init
# cat /proc/1/status | grep -i SigCgt
SigCgt: fffffffe7fc1feff
### C init
# cat /proc/1/status | grep -i SigCgt
SigCgt: 0000000000000000
### bash init
# cat /proc/1/status | grep -i SigCgt
SigCgt: 0000000000010002Secondly, register a SIGTERM handler for the C program to catch SIGTERM.
We call the signal() system call to register the SIGTERM handler and exit actively in the handler. Then, see the result of kill 1 in the container.
This time, you will see that bit 15 (SIGTERM) is set in the SigCgt bitmap of the process status. Also, running kill 1 will kill the init process of this C program in the container.
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
void sig_handler(int signo)
{
if (signo == SIGTERM) {
printf("received SIGTERM\n");
exit(0);
}
}
int main(int argc, char *argv[])
{
signal(SIGTERM, sig_handler);
printf("Process is sleeping\n");
while (1) {
sleep(100);
}
return 0;
}
[root@043f4f717cb5 /]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 09:05 ? 00:00:00 /c-init-sig
root 6 0 18 09:06 pts/0 00:00:00 bash
root 19 6 0 09:06 pts/0 00:00:00 ps -ef
[root@043f4f717cb5 /]# cat /proc/1/status | grep SigCgt
SigCgt: 0000000000004000
[root@043f4f717cb5 /]# kill 1
# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMESAlright, at this point, we can confirm two things:
kill -9 1does not work in the container; the kernel blocks the init process from responding to the SIGKILL privileged signal.kill 1has two possibilities: if the init process does not register a SIGTERM handler, it does not respond to the SIGTERM signal; if a handler is registered, it can respond to the SIGTERM signal.
Conclusion
In this article, we mainly discussed the init process. To address the real problem of "why can't I kill the init process in a container?", we need to understand two basic concepts.
The first concept is the Linux init process, which is the first user-space process. It directly or indirectly creates other processes in the namespace.
The second concept is Linux signals. Linux has 31 basic signals, and processes have three options for handling most signals: ignore, catch, and default behavior. Two privileged signals, SIGKILL and SIGSTOP, cannot be ignored or caught.
Just knowing the basic concepts is not enough; we also need to solve the problem. I tried using bash, C, and Golang programs as the container's init process and found that their responses to kill 1 were different.
Because the final signal handling is done in the Linux kernel, we need to analyze the Linux kernel code.
Two key points about signal handling by the init process in the container, which I want you to remember from this article, are:
- In a container, the init process never responds to the SIGKILL and SIGSTOP privileged signals.
- For other signals, if the user registers a handler, the init process can respond.
