


A Step-by-Step Guide to Identifying and Exploiting Misconfigured AWS Buckets
Introduction
Amazon S3 (Simple Storage Service) is one of the most widely used cloud storage solutions, but misconfigurations can lead to serious security vulnerabilities. In this guide we'll explore how to audit S3 environments, uncover exposed buckets, analyze permissions and mitigate security risks. Using AWS tools and open-source scanners you'll learn to identify vulnerabilities before they become threats.
What is S3 Bucket Reconnaissance?
S3 bucket reconnaissance refers to the process of identifying and investigating publicly accessible or misconfigured AWS S3 buckets that may expose sensitive data. Developer or Security professional can use these techniques to help organizations to secure their cloud storage.
Table of Contents
1. Understanding AWS S3 Buckets
2. Manual Methods for Identifying S3 Buckets
3. Google Dorking for AWS S3 Buckets
4. Automating Google Dorking with DorkEye
5. Using S3Misconfig tool for Fast Bucket Enumeration
6. Finding S3 Buckets with HTTPX and Nuclei
7. Extracting S3 URLs from JavaScript Files
8. Using java2s3 tool to finding s3 urls in js files
9. Brute-Forcing S3 Bucket Names with LazyS3
10. Using Cewl + S3Scanner to find open buckets
11. Extracting S3 Buckets from GitHub Repositories
12. Websites for Public S3 Bucket Discovery
13. Finding Hidden S3 URLs with Extensions
14. AWS S3 Bucket Listing & File Management:
15. Exploiting Misconfigured Buckets
16. Securing S3 Buckets for companiesManual Methods for Identifying S3 Buckets
Using Browser URL Inspection:
One of the simplest ways to check if a website is hosted on AWS is by entering the following in the browser URL bar:
%c0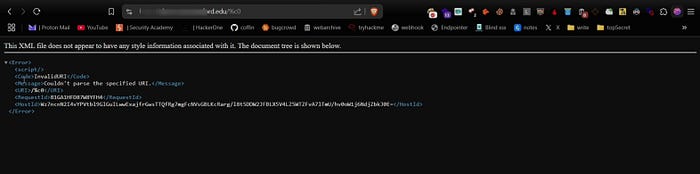
If you encounter an XML error the website is likely hosted on Amazon AWS. To verify further use browser extensions like Wappalyzer to check for AWS-related technologies.
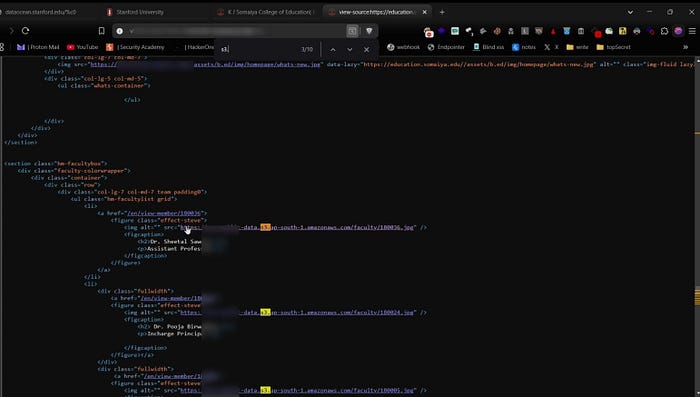
Checking the Source Code
Inspect the website source code and search for "s3" to find any hidden S3 bucket URLs. if you found any just open and check if there bucket listing is enabled.
Google Dorking for AWS S3 Buckets
Google dorking helps uncover exposed S3 buckets. you can use the following dork to find open s3 buckets:
site:s3.amazonaws.com "target.com"
site:*.s3.amazonaws.com "target.com"
site:s3-external-1.amazonaws.com "target.com"
site:s3.dualstack.us-east-1.amazonaws.com "target.com"
site:amazonaws.com inurl:s3.amazonaws.com
site:s3.amazonaws.com intitle:"index of"
site:s3.amazonaws.com inurl:".s3.amazonaws.com/"
site:s3.amazonaws.com intitle:"index of" "bucket"
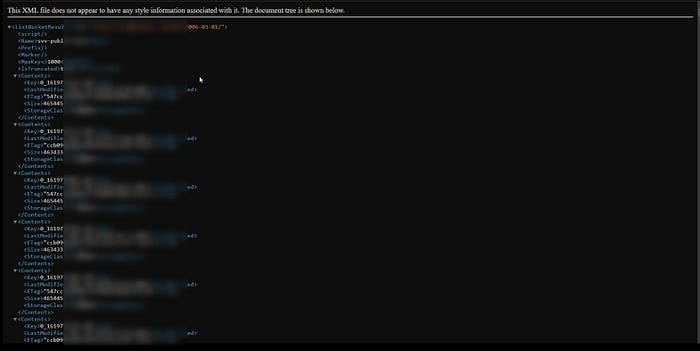
(site:*.s3.amazonaws.com OR site:*.s3-external-1.amazonaws.com OR site:*.s3.dualstack.us-east-1.amazonaws.com OR site:*.s3.ap-south-1.amazonaws.com) "target.com"If bucket listing is enabled you'll be able to view the entire directory and its files. If you see an "Access Denied" message it means the bucket is private.
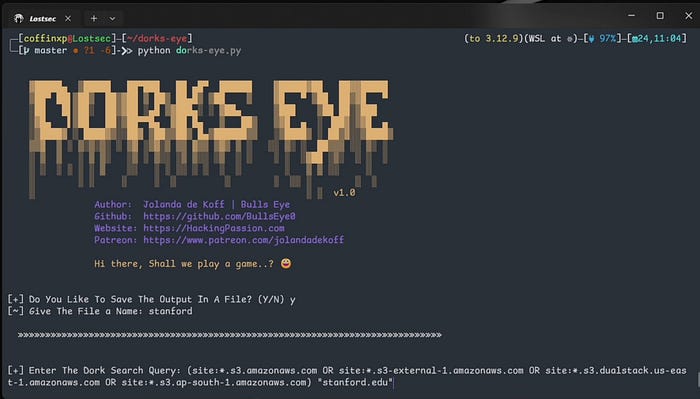
Automating Google Dorking with DorkEye
DorkEye automates Google dorking making reconnaissance faster by quickly extracting multiple AWS URLs for analysis.
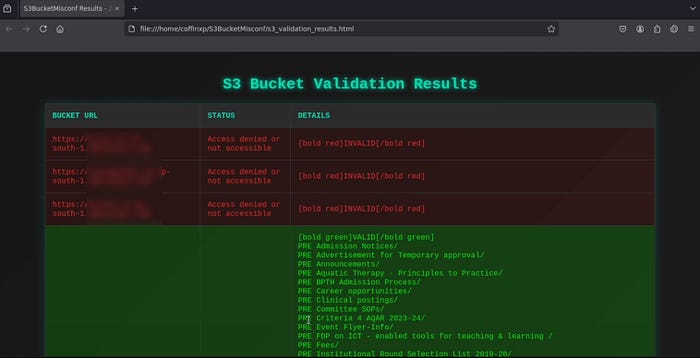
Using S3Misconfig for Fast Bucket Enumeration
S3Misconfig scans a list of URLs for open S3 buckets with listing enabled and saves the results in a user friendly HTML format for easy review.
Finding S3 Buckets with HTTPX and Nuclei
You can use the HTTPX command along with the Nuclei tool to quickly identify all S3 buckets across subdomains saving you significant time in recon.
using subfinder+HTTPX
subfinder -d target.com -all -silent | httpx-toolkit -sc -title -td | grep "Amazon S3"
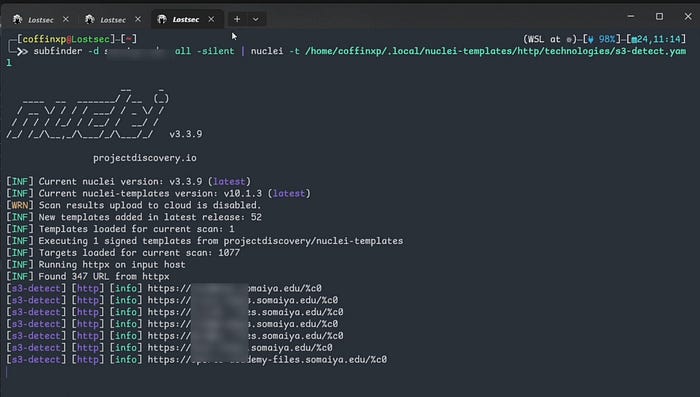
Nuclei template:
subfinder -d target.com -all -silent | nuclei -t /home/coffinxp/.local/nuclei-templates/http/technologies/s3-detect.yaml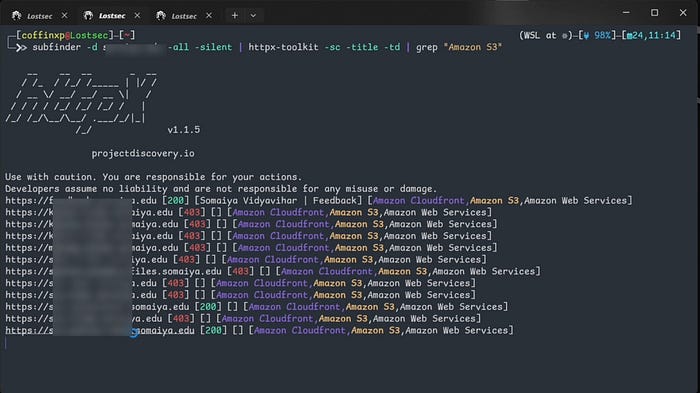
Extracting S3 URLs from JavaScript Files
Next we'll use the Katana tool to download JavaScript files from target subdomains and extract S3 URLs using the following grep command:
katana -u https://site.com/ -d 5 -jc | grep '\.js$' | tee alljs.txt
cat alljs.txt | xargs -I {} curl -s {} | grep -oE 'http[s]?://[^"]*\.s3\.amazonaws\.com[^" ]*' | sort -uUsing java2s3 tool to find s3 urls in js files
Alternatively you can use this powerful approach to extract all S3 URLs from JavaScript files of subdomains. First combine Subfinder and HTTPX to generate the final list of subdomains then run the java2s3 tool for extraction.
subfinder -d target.com -all -silent | httpx-toolkit -o file.txt
cat file.txt | grep -oP '(?<=https?:\/\/).*'
python java2s3.py input.txt target.com output.txt
cat output3.txt | grep -E "S3 Buckets: \['[^]]+"
cat output.txt | grep -oP 'https?://[a-zA-Z0-9.-]*s3(\.dualstack)?\.ap-[a-z0-9-]+\.amazonaws\.com/[^\s"<>]+' | sort -u
cat output3.txt | grep -oP '([a-zA-Z0-9.-]+\.s3(\.dualstack)?\.[a-z0-9-]+\.amazonaws\.com)' | sort -u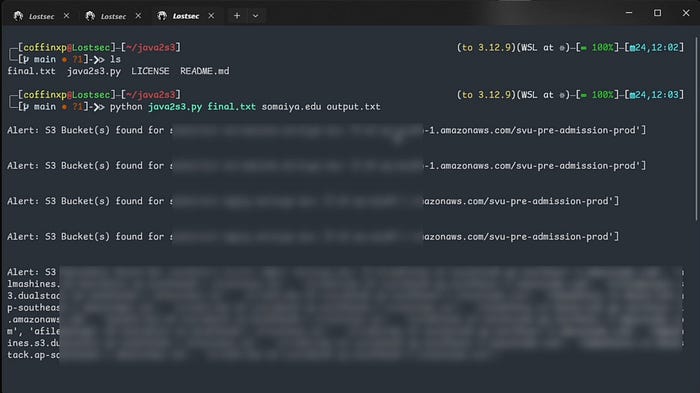
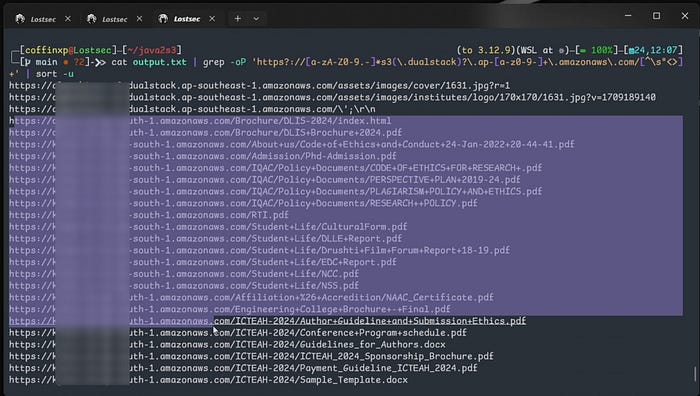
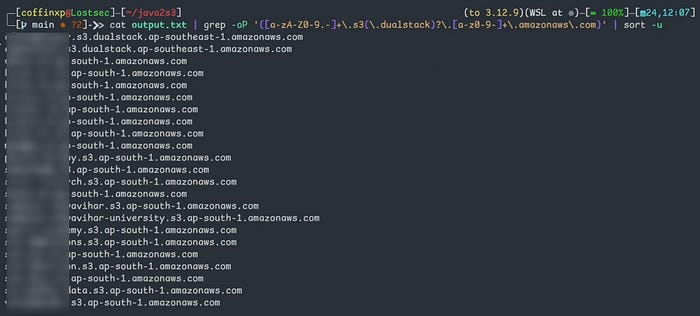
after this you can use use the S3Misconfig tool to identify publicly accessible S3 buckets with listing enabled by sending all these s3 urls to the tool
Brute-Forcing S3 Bucket with LazyS3
You can also use this LazyS3 tool — it's basically a brute force tool for AWS S3 buckets using different permutations. you can run the following command by specifying the target domain
ruby lazys3.rb <COMPANY> 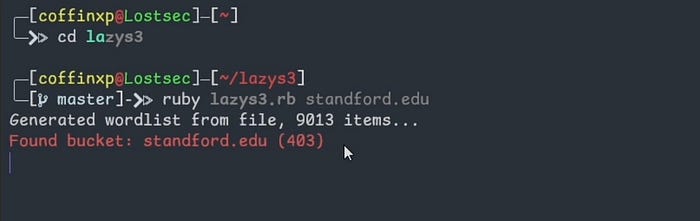
Using Cewl + S3Scanner to find open buckets
Next use the Cewl tool to generate a custom wordlist from the target domain. Then run S3Scanner with the list to identify valid and invalid S3 buckets. Finally use a grep command to filter valid buckets based on permissions and size and inspect their contents using the AWS CLI.
cewl https://site.com/ -d 3 -w file.txt
s3scanner -bucket-file file.txt -enumerate -threads 10 | grep -aE 'AllUsers: \[.*(READ|WRITE|FULL).*]'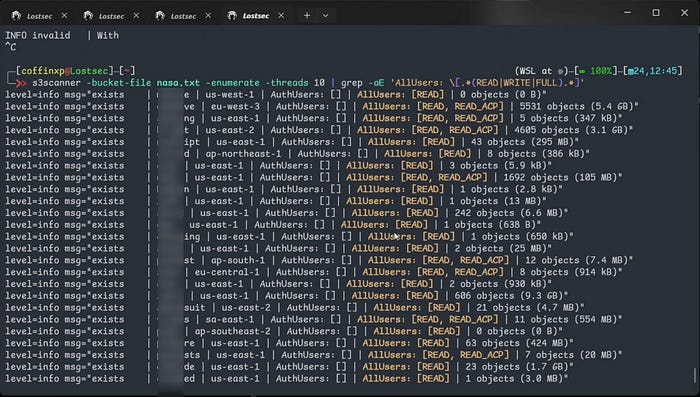
Extracting S3 Buckets from GitHub Repositories
Use GitHub dorks to find AmazonAWS results in public repositories. Check S3 URLs for bucket listings and verify access with AWS CLI. If you discover sensitive data report it to bug bounty programs.
org:target "amazonaws"
org:target "bucket_name"
org:target "aws_access_key"
org:target "aws_access_key_id"
org:target "aws_key"
org:target "aws_secret"
org:target "aws_secret_key"
org:target "S3_BUCKET"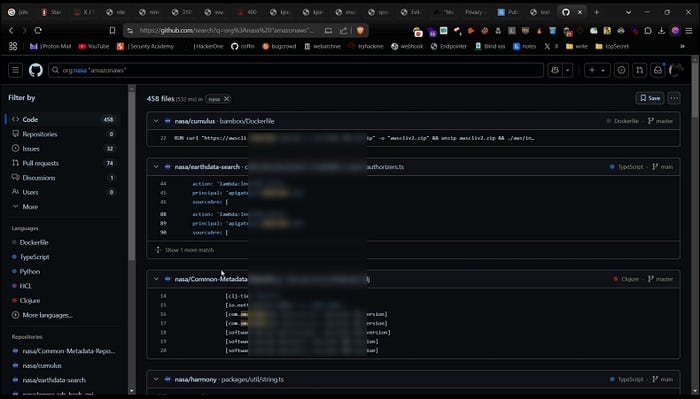
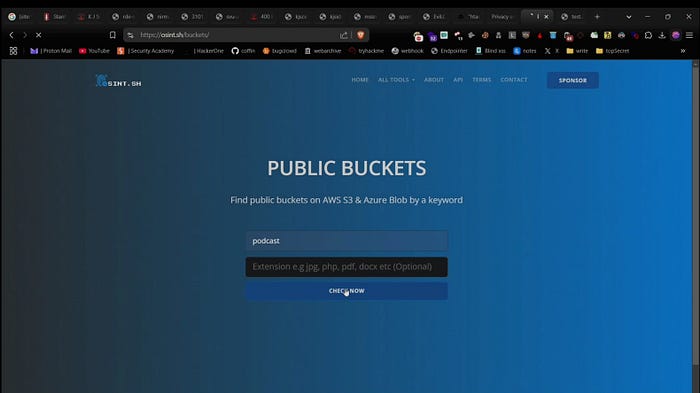
Websites for Public S3 Bucket Discovery
Use these websites to search for files in public AWS buckets by keyword. Download and inspect the contents and if you find any sensitive files report them responsibly:
grayhatwarfare:
osint.sh
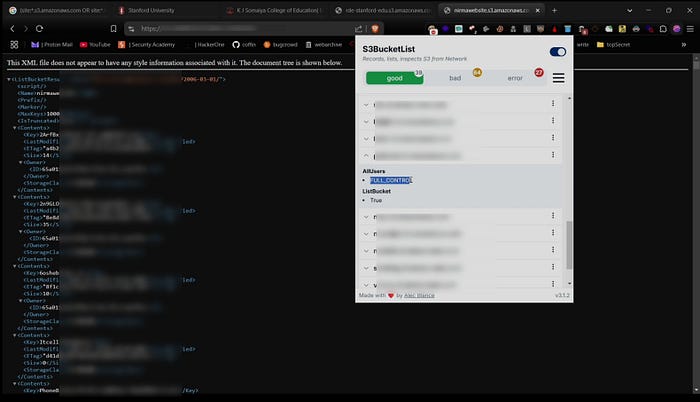
Finding Hidden S3 URLs with Extensions
The S3BucketList Chrome extension scans web pages for exposed S3 URLs helping researchers quickly identify misconfigured buckets without manually inspecting the source code
AWS S3 Bucket Listing & File Management
Easily manage AWS S3 buckets with these AWS CLI commands. These commands help security researchers, penetration testers and cloud administrators list, copy, delete and download files for efficient storage management and security assessments.
Reading Files:
aws s3 ls s3://[bucketname] --no-sign-requestCopying Files:
aws s3 cp file.txt s3://[bucketname] --no-sign-requestDeleting Files:
aws s3 rm s3://[bucketname]/file.txt --no-sign-requestDownloading All Files:
aws s3 cp s3://[bucketname]/ ./ --recursive --no-sign-request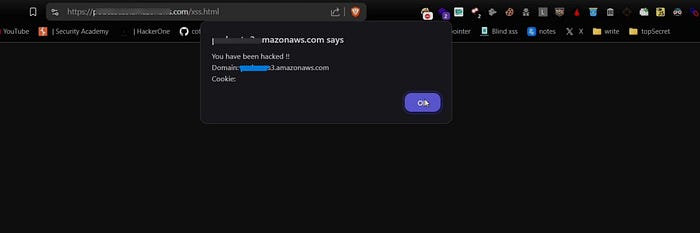
Buckets with "Full Control" permission allow file uploads and deletions which could lead to security risks. Always follow responsible disclosure policies when reporting vulnerabilities.
Securing S3 Buckets
Organizations should follow best practices to prevent unauthorized access:
- Enable bucket policies and restrict access.
- Disable public ACLs unless necessary.
- Monitor logs using AWS CloudTrail.
- Implement encryption for sensitive data.
You can also watch this video where I showed the complete practicle of this method:
loading soon..
Conclusion
S3 bucket reconnaissance is essential for ethical hackers and security professionals. Identifying and securing misconfigured buckets helps organizations strengthen their cloud security and prevent data leaks
The content provided in this article is for educational and informational purposes only. Always ensure you have proper authorization before conducting security assessments. Use this information responsibly