


There has been an increasing demand to make open-source language models more accessible to end-users for local inference and fine-tuning. However, this requires the models to significantly reduce their computational resource demands, allowing their usage on more affordable hardware.
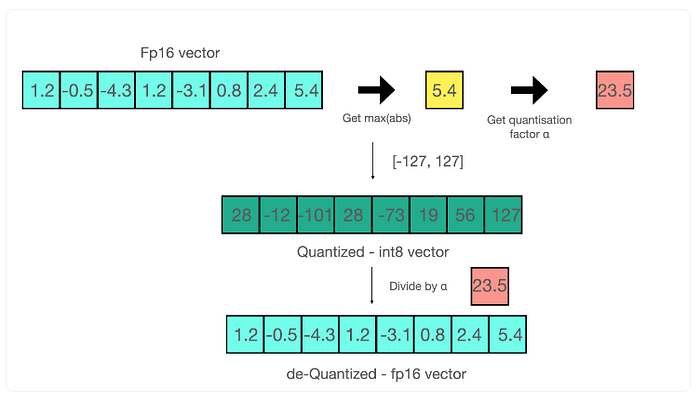
A particularly effective method is called quantization. Practically, quantization is the technique that lowers the bit-width used for representing the weights of a model which effectively decreases its overall size and eases RAM transfer.
The traditional approach of quantization includes selecting a specific quantization grid and normalizer for different parts of the model and then mapping the model weights onto this grid. This mapping algorithm might go through simple rounding or more complex allocations. However, this inevitably creates a trade-off between size and accuracy especially for heavy compression, which can be easily reflected through perplexity — a metric indicating the predictive capability of the model.
AQLM
Against this backdrop, a team from Austria recently released a new state-of-the-art method for 2–3bit width LLM quantization, AQLM (Additive Quantization of Language Models), in a paper that differs fundamentally from some previous methods which normally require complicated formats to manage quantitative outliers.
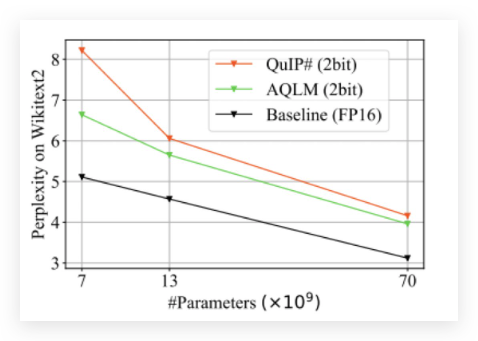
To evaluate a quantization method, two factors are normally concerned, perplexity (intelligence) and speed. From the comparison result of QuIP#-2bit, AQLM-2bit, and original FP16 for three scales of Llama-2 models, it's surprising to see the AQLM-2bit is always performing better than QuIP#-2bit, and the AQLM-2bit for 70b model scores 4 in perplexity on Wikitext2 which is much better than original 13b model. For me, when the perplexity score is under 4, the model inference is qualified for use in practical applications.
The speed performance running on the Nvidia 3090 is also in the range of acceptance compared to the original one.

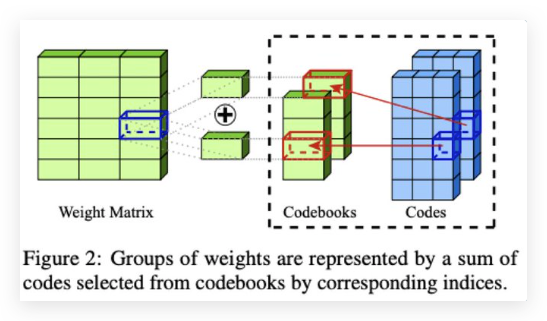
The detailed algorithm of AQLM is explained in their paper. Basically, the team advances the usage of Additive Quantization (AQ), a specific type of MCQ, Multi-Codebook Quantization, for compressing LLM weights — a technique classically employed in information retrieval systems for efficient database compression and search. This approach is achieved by learned AQ performed in an input-adaptive fashion and joint optimization of codebooks across blocks of layers.
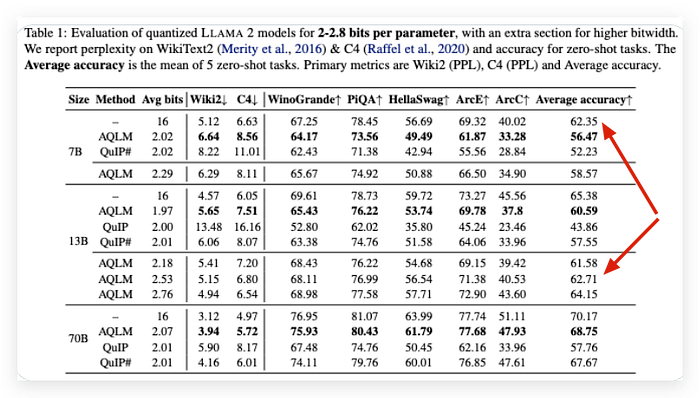
The validation result looks very interesting that not only does the 2.07-bit of Llama-2–70B model score <4 WikiText2 benchmark but also the 2.5-bit of Llama-2–13B model is a little more accurate than the original 7B with a much smaller size running on a budget GPU.
You can find in the paper for details of:
- AQLM algorithm, including layer calibration of input/output activations and intra-layer quantization parameter optimization.
- Validation of AQLM's effectiveness
Now, let's go through the code to see how much cost we can save using AQLM models.
Code Walkthrough
In this demo, we will use AQLM transformers to run inference on a compressed version of the Mixtral-8x7b model in 2bit on the free tier of Google Colab with only ~13GB T4 GPU.

Mixtral-8x7b is a sparse mixture-of-experts model provided by Mistral AI and proved its performance by outperforming Llama-2–70B on generation quality entirely with 6x faster speed, and particularly matches or outperforms GPT-3.5 on most benchmarks. With 32k tokens' context, this open-source model is pretty much usable for practical generative applications.
Mixtral has 47B total parameters but with its innovative architecture, it processes each token with 13B parameters equivalently which supports much of its inference speed. However, even a Mistral-7B needs a GPU with 24GB VRAM for inference, so it will require almost 64GB for a well-facilitated Mixtral-8x7b model and that costs as much as around 4.5$/h.
Now, by using the 2-bit AQLM version, we can run this model for totally free on the Colab notebook.
Install the dependencies
First, you should install the aqlm library with [gpu] specification to involve CUDA related packages. Also, you'd have to install theaccelerate library and an aqlm branch of transformers directly from GitHub for latest AQLM update.
!pip install aqlm[gpu]==1.0.1
!pip install git+https://github.com/huggingface/accelerate.git@main
!pip install git+https://github.com/BlackSamorez/transformers.git@aqlmLoad the model
There is no difference in using HuggingFace's transformers methods to load a model to local memory. To find AQLM compressed models, please visit BlackSamorez's page on HuggingFace.
In this demo, we use the model BlackSamorez/Mixtral-8x7b-AQLM-2Bit-1x16-hf-test-dispatch and use the original Mixtral's tokenizer Mixtral-8x7B-v0.1.
from transformers import AutoTokenizer, AutoModelForCausalLM
quantized_model = AutoModelForCausalLM.from_pretrained(
"BlackSamorez/Mixtral-8x7b-AQLM-2Bit-1x16-hf-test-dispatch",
torch_dtype="auto", device_map="auto", low_cpu_mem_usage=True,trust_remote_code=True,
)
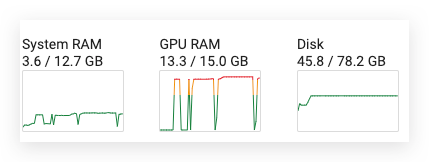
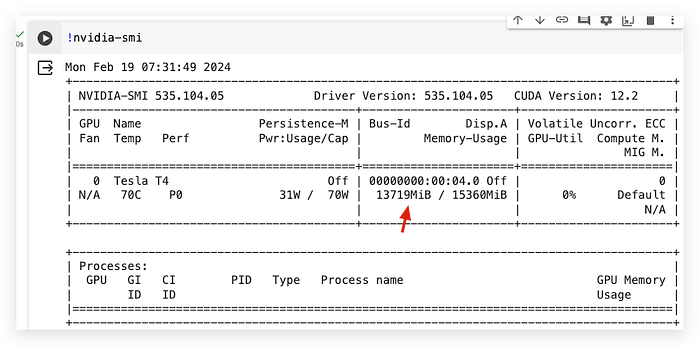
tokenizer = AutoTokenizer.from_pretrained("Mixtral-8x7B-v0.1")After loading is complete, you will find the RAM usage is only 13.3GB which is smaller than the limit of free-tier Colab account.
Testing prompt
For a quick test, we can simply call the generate() method of this model to create a text completion task.
%%time
output = quantized_model.generate(tokenizer("The relationship between humans and AI ", return_tensors="pt")["input_ids"].cuda(), min_new_tokens=128, max_new_tokens=128)
print(tokenizer.decode(output[0]))The result looks decent and fast which took 31.7s to respond.
<s> The relationship between humans and AI The relationship between humans and AI is a complex one. On the one hand, AI has the potential to improve our lives in many ways. It can help us to make better decisions, to solve problems more efficiently, and to understand the world around us better. On the other hand, AI can also be used to manipulate and control us. It can be used to manipulate our emotions, to control our thoughts, and to manipulate our behavior. The relationship between humans and AI is a complex one. On the one hand, AI has the potential to improve our lives in many ways. It can help us to make better decisions, CPU times: user 25.6 s, sys: 114 ms, total: 25.8 s Wall time: 31.7 s
Instruction Prompt
The Mixtral-8x7B-v0.1 is the base model that has not been fine-tuned for instruction or chat, but it is still possible to refine the prompt to ask the model to respond with a decent answer.
First, we structure the prompt with SYSTEM, USER, and ASSISTANT sections.
import json
import textwrap
system_prompt = "A chat between a curious user and a blog writing assistant. "
def get_prompt(human_prompt):
prompt_template=f"{system_prompt}\n\nUSER: {human_prompt} \nASSISTANT: "
return prompt_templateThen, we define a parse_text() function to only print the assistant's response by filtering the output.
def remove_human_text(text):
return text.split('USER:', 1)[0]
def parse_text(data):
for item in data:
text = item['generated_text']
assistant_text_index = text.find('ASSISTANT:')
if assistant_text_index != -1:
assistant_text = text[assistant_text_index+len('ASSISTANT:'):].strip()
assistant_text = remove_human_text(assistant_text)
wrapped_text = textwrap.fill(assistant_text, width=100)
print("#####", wrapped_text)
# return assistant_textMoving forward, build the pipeline for text generation.
from transformers import pipeline
pipe = pipeline(
"text-generation",
model=quantized_model,
tokenizer=tokenizer,
max_length=1200,
temperature=0.7,
top_p=0.95,
do_sample=True,
)Call the pipe() method to ask the model to generate the blog post we require.
%%time
prompt = 'Write a short and engaging blog post of traveling in Bohol Island. '
raw_output = pipe(get_prompt(prompt))
parse_text(raw_output)The blog post was generated in ~3min which is a little longer than I expected but the content is fairly acceptable considering this is not a fine-tuned version of an instruction model. A more instruction-capable model with AQLM-2bit quantization was released recently (BlackSamorez/Mixtral-8x7B-Instruct-v0.1-AQLM-2Bit-1x16-hf).

The overall GPU memory usage is still under 14GB so far.
Next, I tried a simple code instruction.
%%time
prompt = '''Write a short python code to calculate factorial.
'''
raw_output = pipe(get_prompt(prompt))
parse_text(raw_output)The model generates an explanation with a code snippet that can be executed correctly.

In conclusion, it is always worth observing advancements in quantization, as cost reductions in open-source models play a pivotal role in fostering sustainable AI business development.
Thanks for reading. If you think it's helpful, please Clap 👏 for this article. Your encouragement and comments mean a lot to me, mentally and financially. 🍔
Before you go:
✍️ If you have any questions or business requests, please leave me responses or find me on X and Discord where you can have my active support on development and deployment.
☕️ If you would like to have exclusive resources and technical services, checking the membership or services on my Ko-fi will be a good choice.