
As mentioned in the previous article, Llama.cpp might not be the fastest among the various LLM inference mechanisms provided by Intel. This article continues with some more tests.
Llama.cpp
First, we run llama.cpp again with the same prompt and record the data.
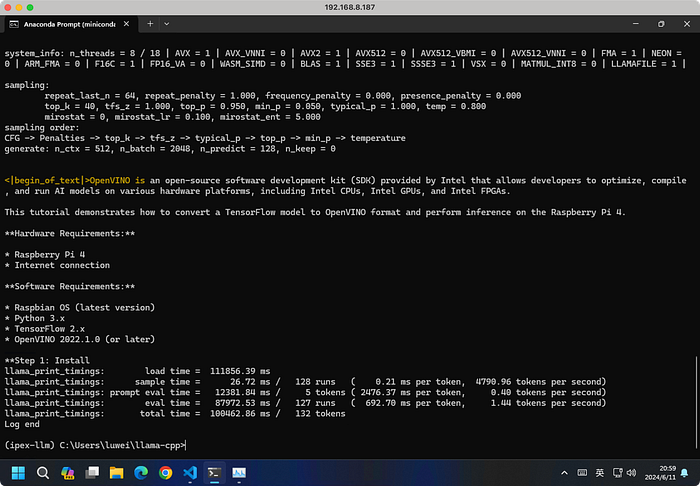
main -m Meta-Llama-3-70B-Instruct-Q4_K_M.gguf -n 128 --prompt "OpenVINO is" -t 8 -e -ngl 999 --color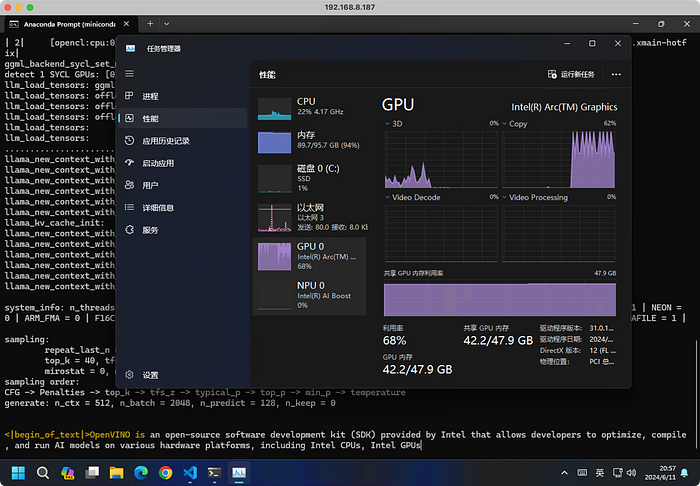
🤗Huggingface Transformers + IPEX-LLM
Although Llama.cpp also uses IPEX-LLM to accelerate computations on Intel iGPUs, we will still try using IPEX-LLM in Python to see the difference.
The code ipex-llm-llama3.py is as follows,
# Modified by Wei Lu(mailwlu@gmail.com)
# Copyright 2016 The BigDL Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
import torch
import time
import argparse
from ipex_llm.transformers import AutoModelForCausalLM
from transformers import AutoTokenizer
# you could tune the prompt based on your own model,
# here the prompt tuning refers to https://llama.meta.com/docs/model-cards-and-prompt-formats/meta-llama-3
DEFAULT_SYSTEM_PROMPT = """\
"""
def get_prompt(user_input: str, chat_history: list[tuple[str, str]],
system_prompt: str) -> str:
prompt_texts = [f'<|begin_of_text|>']
if system_prompt != '':
prompt_texts.append(f'<|start_header_id|>system<|end_header_id|>\n\n{system_prompt}<|eot_id|>')
for history_input, history_response in chat_history:
prompt_texts.append(f'<|start_header_id|>user<|end_header_id|>\n\n{history_input.strip()}<|eot_id|>')
prompt_texts.append(f'<|start_header_id|>assistant<|end_header_id|>\n\n{history_response.strip()}<|eot_id|>')
prompt_texts.append(f'<|start_header_id|>user<|end_header_id|>\n\n{user_input.strip()}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n')
return ''.join(prompt_texts)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Predict Tokens using `generate()` API for Llama3 model')
parser.add_argument('--repo-id-or-model-path', type=str, default="meta-llama/Meta-Llama-3-70B-Instruct",
help='The huggingface repo id for the Llama3 (e.g. `meta-llama/Meta-Llama-3-70B-Instruct`) to be downloaded'
', or the path to the huggingface checkpoint folder')
parser.add_argument('--prompt', type=str, default="OpenVINO is",
help='Prompt to infer')
parser.add_argument('--n-predict', type=int, default=128,
help='Max tokens to predict')
parser.add_argument('--bit', type=int, default=4,
help='load in 4,5 or 8 bit')
args = parser.parse_args()
model_path = args.repo_id_or_model_path
if args.bit == 4:
# Load model in 4 bit,
# which convert the relevant layers in the model into INT4 format
# When running LLMs on Intel iGPUs for Windows users, we recommend setting `cpu_embedding=True` in the from_pretrained function.
# This will allow the memory-intensive embedding layer to utilize the CPU instead of iGPU. Not help in this case.
model = AutoModelForCausalLM.from_pretrained(model_path,
load_in_4bit=True,
optimize_model=True,
trust_remote_code=True,
use_cache=True)
else:
model = AutoModelForCausalLM.from_pretrained(model_path,
load_in_low_bit=f"sym_int{args.bit}",#https://github.com/intel-analytics/ipex-llm/blob/10e480ee96f1746392ef9baca93585435f6f9523/python/llm/src/ipex_llm/transformers/model.py#L139
#not saving VRAM:cpu_embedding=True,
optimize_model=True,
trust_remote_code=True,
use_cache=True)
model = model.half().to('xpu')
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# here the terminators refer to https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct#transformers-automodelforcausallm
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>"),
]
# Generate predicted tokens
with torch.inference_mode():
prompt = get_prompt(args.prompt, [], system_prompt=DEFAULT_SYSTEM_PROMPT)
input_ids = tokenizer.encode(prompt, return_tensors="pt").to('xpu')
# ipex_llm model needs a warmup, then inference time can be accurate
output = model.generate(input_ids,
eos_token_id=terminators,
max_new_tokens=20)
# start inference
st = time.time()
output = model.generate(input_ids,
eos_token_id=terminators,
max_new_tokens=args.n_predict)
torch.xpu.synchronize()
end = time.time()
output = output.cpu()
output_str = tokenizer.decode(output[0], skip_special_tokens=False)
print(f'Inference time: {end-st} s, tokens: {len(output[0])}, t/s:{len(output[0])/(end-st)}')
print('-'*20, 'Prompt', '-'*20)
print(prompt)
print('-'*20, 'Output (skip_special_tokens=False)', '-'*20)
print(output_str)
python ipex-llm-llama3.py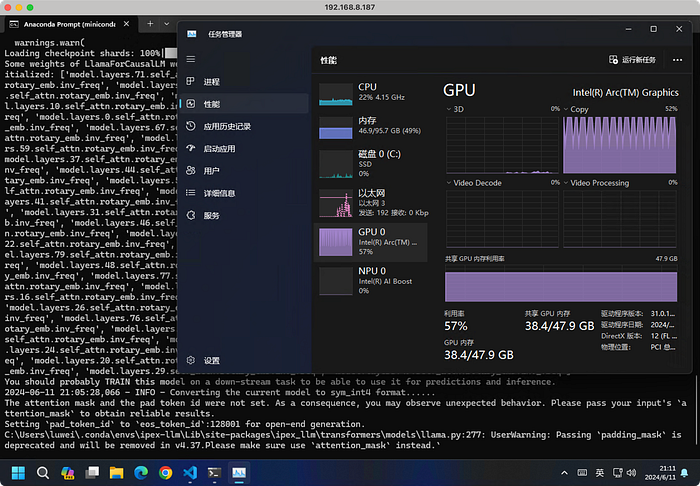
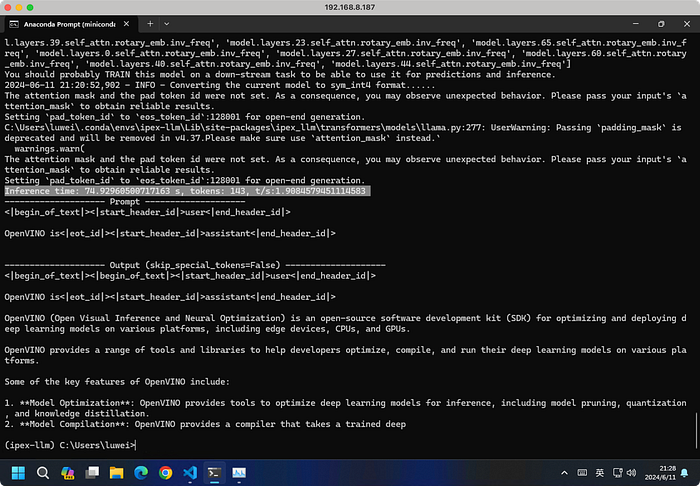
Even with the warmup round (line 92–94) commented, it can still make 1.86 tokens/second, larger than llama.cpp's 1.44 obviously.
OpenVINO
The third option is OpenVINO, which can be used with 🤗 Transformers through Optimum.
I tried two pre-converted models from other users, https://huggingface.co/nsbendre25/llama-3-70B-Instruct-ov-fp16-int4-asym/ and https://huggingface.co/fakezeta/Meta-Llama-3-70B-Instruct-ov-int4, but both failed due to insufficient memory.

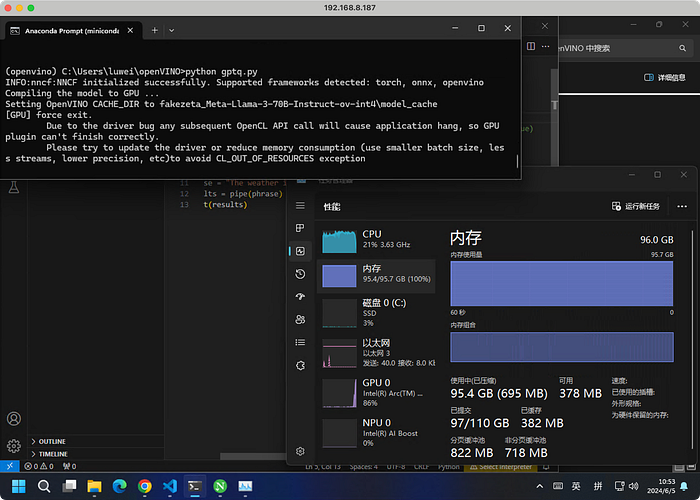
To compare all three methods, we will switch to the 8B Llama-3 model.
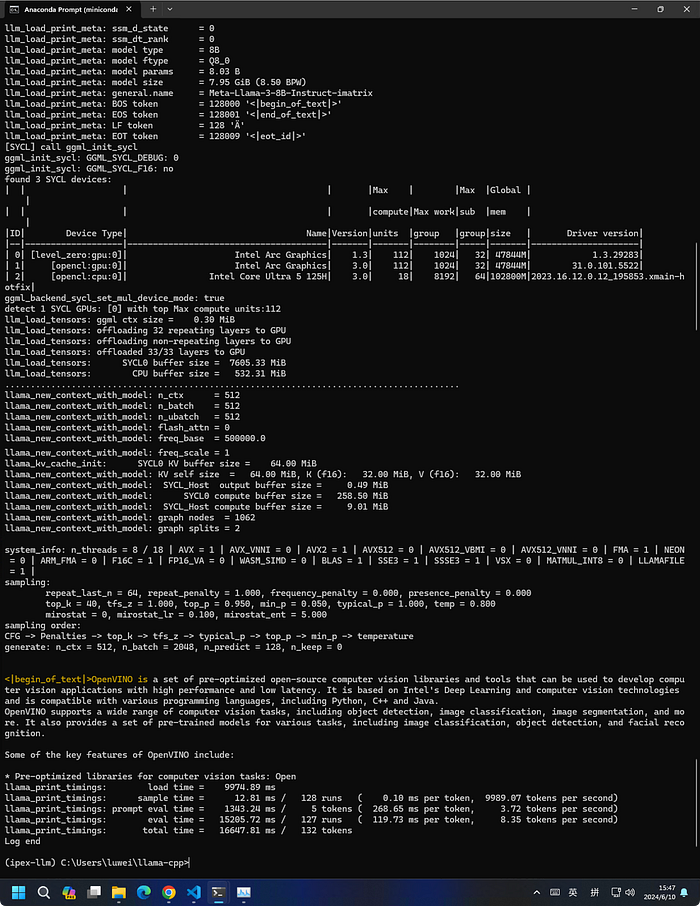
Llama.cpp
Model is from https://huggingface.co/lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF.
main -m Meta-Llama-3-8B-Instruct-Q8_0.gguf -n 128 --prompt "OpenVINO is" -t 8 -e -ngl 999 --color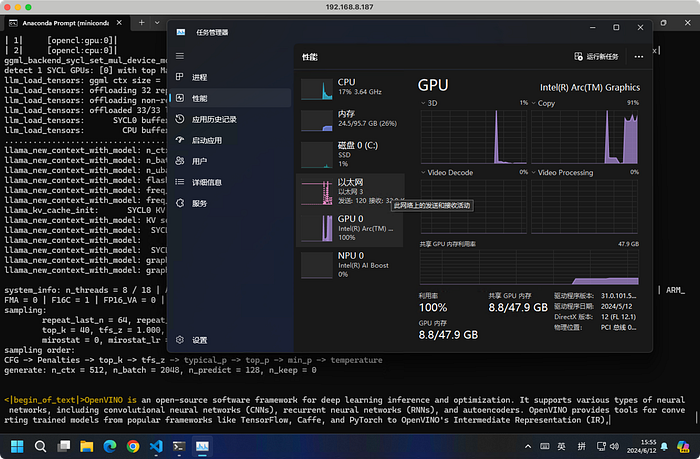
🤗Huggingface Transformers + IPEX-LLM
python ipex-llm-llama3.py --repo-id-or-model-path=meta-llama/Meta-Llama-3-8B-Instruct --bit=8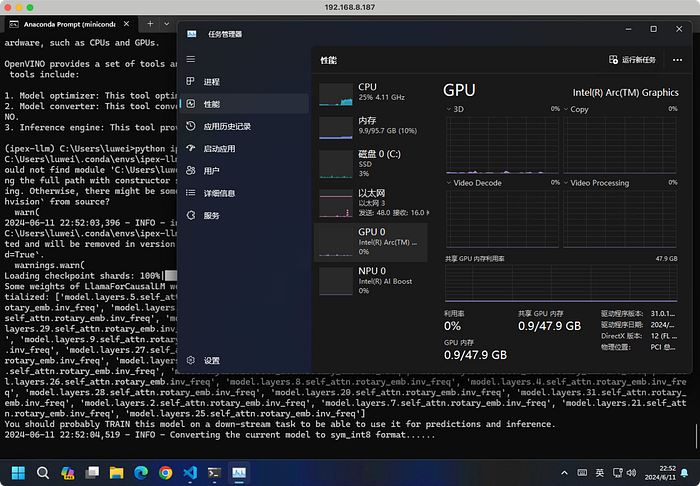
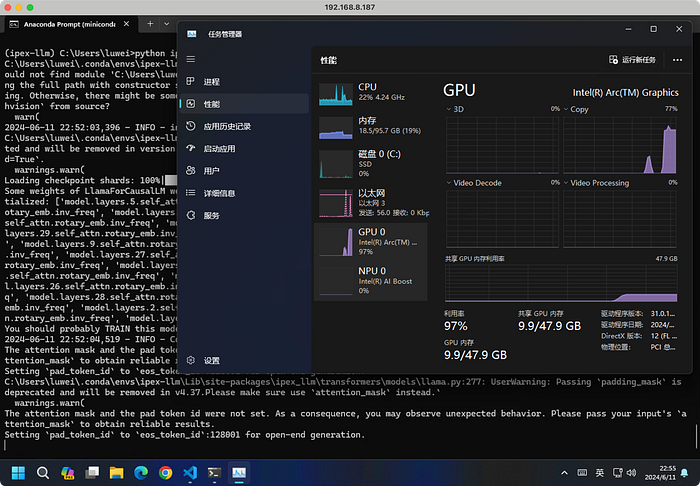
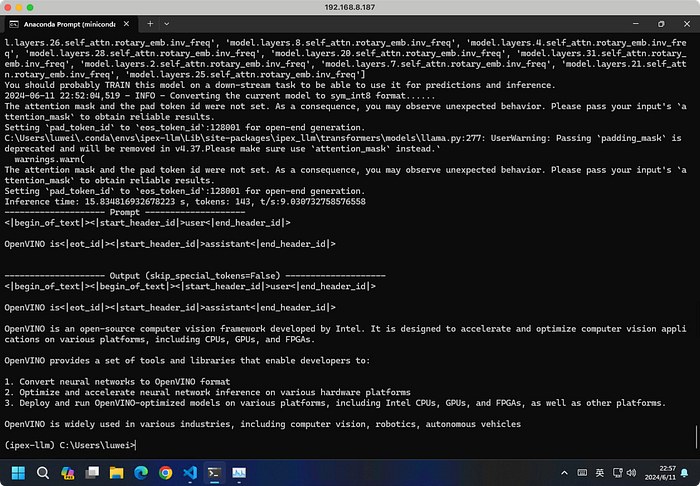
OpenVINO
Model is from https://huggingface.co/fakezeta/llama-3-8b-instruct-ov-int8.
The code is as follows.
from optimum.intel.openvino import OVModelForCausalLM
from transformers import AutoTokenizer, pipeline
import time
# Load model from Hugging Face already optimized with GPTQ
model_id = "fakezeta_llama-3-8b-instruct-ov-int8"
model = OVModelForCausalLM.from_pretrained(model_id, device="GPU")
# Inference
tokenizer = AutoTokenizer.from_pretrained(model_id)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
phrase = "OpenVINO is"
results = pipe(phrase,max_length=20)
print(results)
tokens=128
tt = time.time()
results = pipe("OpenVINO is",max_length=tokens)
ts = tokens/(time.time()-tt)
print(results)
print(f"{ts:2.2f} t/s")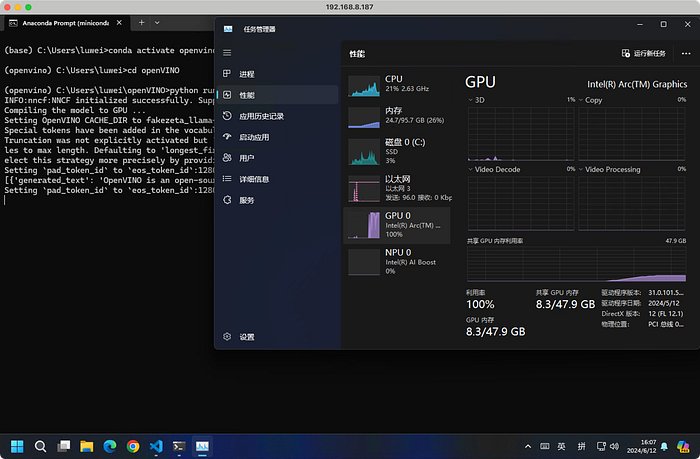
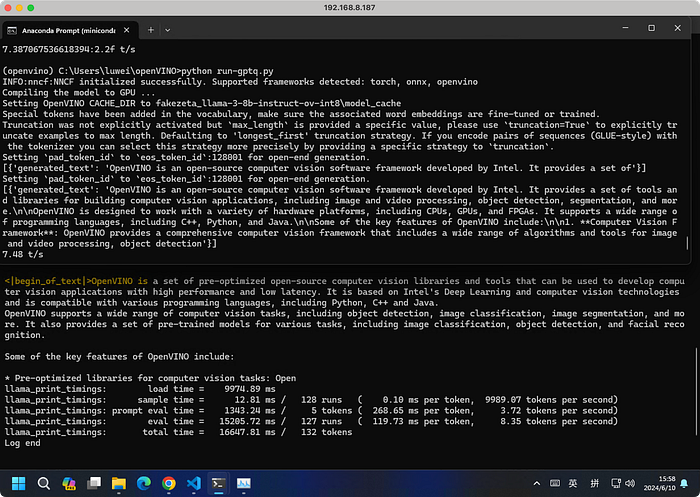
In summary, 🤗Transformers + IPEX-LLM provides the best performance, which might be related to the quantization format. Further comparisons are needed to evaluate the precision loss of various quantization formats.

Llama.cpp offers flexibility in allocating layers between CPU and GPU. With half of the CPU memory often remaining free, this allows for experimenting with 5-bit or higher quantization and larger models than the 70B.
Additionally, Intel provides hardware acceleration for ONNX + DirectML. This will be included in the next experiment. Stay tuned…