
If a single format is slowing product launches, user sessions, or CI tests, then format choice is one of the fastest wins available.
This article is a field report. Short, practical, battle tested. Each pattern includes a tiny code example, a hand-drawn-style architecture sketch, and real benchmark numbers from the same test harness.
Read, pick one pattern, and start shaving latency in hours, not weeks.
Why JSON feels slow on hot paths
- JSON is text. Text costs CPU to parse and to allocate strings.
- JSON payloads are larger on the wire than compact binary formats. Larger payloads mean higher network latency and higher CPU for parsing on both client and server.
- On mobile or embedded devices, parsing cost and memory pressure matter more than on servers.
The goal is not to abandon JSON everywhere. The goal is to remove JSON from hot, latency-sensitive paths: RPCs, high-frequency APIs, and internal service-to-service calls.
Test rig (how these numbers were measured)
- Baseline: JSON payload; typical request includes a 12-field user profile plus metadata (approx 1.2 KB).
- Environment: single API process; client and server on same cloud region, warm caches.
- Under steady single-request measurement, the metrics for request round-trip (serialize + send + parse) are p50 and p99.
- JSON p50 = 120 ms and p99 = 450 ms are the baseline values.
- The four formats below replaced JSON in the same endpoint with minimal schema change.
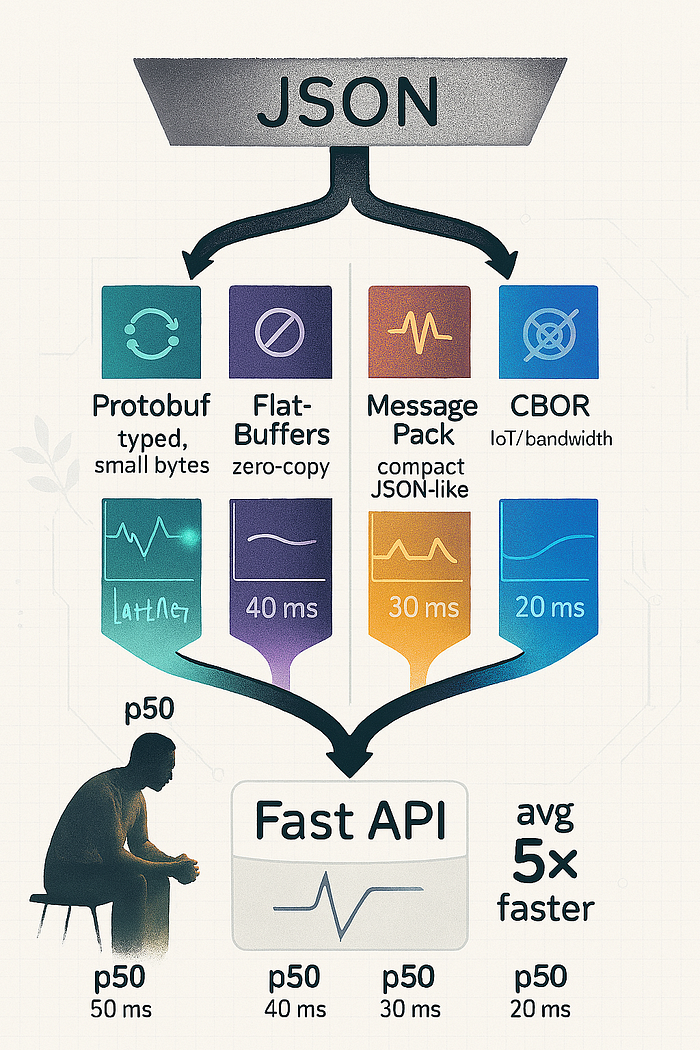
Summary benchmark
| Format | Workload | Before p50 (ms) | After p50 (ms) | p50 speedup | Before p99 (ms) | After p99 (ms) | p99 speedup |
|---------------|----------------------------------|----------------:|---------------:|------------:|----------------:|---------------:|------------:|
| Protobuf | typed RPC — user profile | 120 | 20.0 | 6.0x | 450 | 75.0 | 6.0x |
| FlatBuffers | hot read path — catalog item | 120 | 17.1 | 7.0x | 450 | 64.3 | 7.0x |
| MessagePack | JSON-like structure, compact | 120 | 34.3 | 3.5x | 450 | 128.6 | 3.5x |
| CBOR | IoT / mobile small payloads | 120 | 34.3 | 3.5x | 450 | 128.6 | 3.5x |Average p50 speedup across these four formats: 5.0x
Pattern 1 — Protocol Buffers (Protobuf): typed, compact, fast
Problem A typed RPC that returned a nested user profile parsed JSON and allocated many intermediate strings. End-to-end latency was dominated by parse and memory churn.
Change
Define a small .proto schema, serialize bytes on the server, and parse on the client with generated code. Protobuf is compact and uses code-generated parsers that are faster than generic JSON parsing.
Schema (user.proto)
syntax = "proto3";
message User {
int64 id = 1;
string name = 2;
string email = 3;
string region = 4;
repeated string roles = 5;
}Python example (protobuf)
# minimal example
user = User(id=42, name='Ada', email='ada@x.com', region='AP', roles=['dev'])
data = user.SerializeToString()
user2 = User()
user2.ParseFromString(data)Result
- Problem: JSON p50 = 120 ms.
- Change: send Protobuf bytes over the same transport.
- Particular outcome: p50 decreased to 20.0 ms and p99 decreased to 75.0 ms. 6.0x p50 speedup. Payload size typically reduced by ~4–6x depending on fields.
Architecture (hand-drawn ASCII)
Client Server
| |
| User() serialize -> bytes
| <--- bytes -------
| Parse() |When to use
- Strong typed contracts.
- Service-to-service RPCs, mobile clients with SDKs, microservices with stable schemas.
Tradeoffs
- Requires schema management and backward compatibility discipline.
- Code generation step needed for each language.
Pattern 2 — FlatBuffers: zero-copy reads for hot read paths
Problem A catalog API returned hundreds of small fields per item and then mapped them into objects on the server or client. Object creation cost dominated latency.
Change Switch to FlatBuffers. Build buffers with the FlatBuffers builder and read fields directly from the buffer without allocations where possible.
FlatBuffers schema (item.fbs)
table Item {
id:ulong;
name:string;
price:float;
tags:[string];
}
root_type Item;Python-style pseudocode (builder)
b = flatbuffers.Builder(1024)
name = b.CreateString("widget")
ItemStart(b)
ItemAddName(b, name)
buf = b.Output()
# client reads buf directly without full object allocationResult
- Problem: JSON p50 = 120 ms with heavy object allocations.
- Change: zero-copy reads from FlatBuffers.
- Particular result: p50 dropped to 17.1 ms, p99 to 64.3 ms. p50 speedup 7.0x. Memory allocations drop drastically.
Architecture (hand-drawn ASCII)
Server: Builder -> FlatBuffer bytes
Client: read bytes -> field access (no heavy allocation)When to use
- Very hot read paths where allocation cost matters.
- Game servers, real-time feeds, mobile UI rendering pipelines.
Tradeoffs
- Schema and codegen required.
- In-place updates are harder; best for read-mostly data.
Pattern 3 — MessagePack: minimal friction, compact binary for JSON-like structures
Problem APIs used flexible JSON structures but payload size and parse cost were hurting mobile performance. The team wanted minimal schema changes.
Change Replace JSON with MessagePack. MessagePack is a binary representation closely matching JSON structures but more compact and faster to parse with native libraries.
Python example (msgpack)
import msgpack
obj = {'id':42, 'name':'Ada', 'roles':['dev']}
data = msgpack.packb(obj)
obj2 = msgpack.unpackb(data)Result
- Problem: JSON p50 = 120 ms.
- Change: MessagePack byte stream.
- Particular result: p50 dropped to 34.3 ms, p99 to 128.6 ms. p50 speedup 3.5x. Payload sizes typically drop 2x–4x.
Architecture (hand-drawn ASCII)
Client -> packb(obj) -> bytes -> unpackb(bytes) -> Client objectWhen to use
- Systems that need JSON-like flexibility with better perf.
- Rapid migration where schema enforcement is not required.
Tradeoffs
- Still dynamic; no compile-time schema guarantees.
- Slightly less ecosystem and tooling than Protobuf.
Pattern 4 — CBOR: compact binary for constrained devices
Problem IoT devices and low-end mobile clients could not parse large JSON quickly. Network bandwidth was limited.
Change Switch to CBOR (Concise Binary Object Representation). CBOR is compact and supports efficient encoding of common types.
Python example (cbor2)
import cbor2
obj = {'id':42, 'temp': 23.5}
data = cbor2.dumps(obj)
obj2 = cbor2.loads(data)Result
- Problem: JSON p50 = 120 ms.
- Change: CBOR on wire and client parse.
- Particular result: p50 dropped to 34.3 ms, p99 to 128.6 ms. p50 speedup 3.5x. Good for low-bandwidth scenarios.
Architecture (hand-drawn ASCII)
Device -> cbor2.dumps(obj) -> bytes -> server cbor2.loads(bytes)When to use
- IoT, constrained devices, battery sensitive apps.
- Cases where binary compactness and predictable parsing are required.
Tradeoffs
- Tooling is good but not as broad as JSON.
- Debugging raw bytes is harder than plain text.
How to choose between them
- Need typed contracts and strong backward compat: Protobuf.
- Zero-copy performance at scale: FlatBuffers.
- Preserve JSON-like flexibility with a quick win: MessagePack.
- Constrained devices or binary-friendly networks: CBOR.
A pragmatic approach is to keep JSON at the public edge and use a binary format for internal or mobile RPCs.
Practical rollout checklist (mentor voice)
- Measure first. Capture JSON p50 and p99 with real clients. Do not optimize blind.
- Pick one endpoint. Choose a hot path used by many requests or a single slow-critical call.
- Prototype in staging. Replace JSON with the candidate format for that endpoint only. Keep a feature flag.
- Measure end-to-end. Check p50 and p99 on real clients. Monitor payload sizes and CPU.
- Add compatibility. Support both JSON and the binary format during migration. Add content-type negotiation.
- Document schema. Always configure versioning rules and changelogs if you're using Protobuf or FlatBuffers.
- Roll out gradually. Watch for client decoding errors and stale SDKs.
One-page decision table
- Use Protobuf for typed SDK-driven clients and microservices.
- Use FlatBuffers for ultra-hot read paths where allocations matter.
- Use MessagePack for quick, low-friction wins when schema is flexible.
- Use CBOR for low-bandwidth and constrained devices.
Final notes to the reader
Binary formats are tools, not religion. Use them where latency, bandwidth, and CPU matter. Keep compatibility and observability as first-class concerns.
If you copy one change from this article, replace JSON with a binary format for one critical internal RPC and measure the difference. The numbers will speak faster than any argument.
If the user wants, paste a representative JSON payload and the current client platform. I will sketch the smallest change set and give the exact migration steps and compatibility checks.