
💭 I've been lecturing, speaking and chatting a lot about MLOps and its latest generative AI iterations (for the sake of expediency I'll just label all of these 'LLMOps' for now, even when the discipline is concerned with vision, audio and so on). What is clear is that people are thoroughly enjoying hearing about the cool demo's, the increasingly competitive model benchmarks, the plethora of software packages and libraries and the general 'wow' factor at the pace of innovation that is happening in the field.
But what is also clear is that although a lot of this is fun, many professionals actually desperately want to know how to build and implement a capability in their teams or organisations that can succesfully drive value from this new wave of innovation. In my opinion, we can often get caught up in the latest tools or models, as they are fun to play with and grab our attention with high profile announcements all over social media! LLMOps is all about building out this capability in a robust, scalable way, just like many organisations have done for machine learning with MLOps over the past few years.
Despite all the latest and greatest results, the reality is that fundamental principles are always the most important things to get right. In this post, I'll start picking apart on aspect of these principles. Here I'm going to focus on architecture and design principles that will stand you in good stead. I discuss many of these in my book, there with a focus on more traditional machine learning methods, but also with a new section on LLMOps.
Let's get stuck in!
Foundational Principles
🏗 When it comes to architecture for your MLOps platform, you may be annoyed (gasp, shock, horror) to hear that actually you should follow many of the same principles as in classic software engineering. As I will discuss later in this article, this also holds true for LLMOps.
Let's list some important design principles you should be aware of. There are many, many more likely floating out in literature but these are just some that I think are particularly powerful (see Chapter 5 of my book for more details):
- Separation of Concerns: build your components so that they do one thing and do it well! If you are running heavy data transformations in your orchestration tool, or you are trying to do load balancing in your ML pipeline, you might have broken this principle*.
- Principle of Least Surprise: IMO this one is not too strictly defined (if you have a good definition please share!) but I think of it as saying that when you show your architecture to a reasonably competent person with domain/architecture knowledge you should minimise the amount of 'surprising' choices. How many times will someone say 'oh' as you take them through your architecture? 'Oh, I see you've decided to use SageMaker model registry as an application database' or 'I see you've used an LLM to generate some pretty standard queries for pulling the last day's data' (extreme examples but you get the picture).
- Principle of Least Effort: Humans will take the path of least resistance, so don't make things more complex than they need to be, or people will find shortcuts. Also, developers will work with patterns that work, and will only rail against it when it's clear there is a better way. I interpret this really as saying that it's important to make things as simple as we can, and also be willing to make them simpler again based on feedback.
You can then get into some of the real classics of software engineering, the SOLID principles, which were written to be applied to Object Oriented Programming (OOP), but they are actually really versatile concepts that you can often apply to your entire architecture!
They are:
(S) Single Responsibility: As for separation of concerns, things that have one job to do are easier to maintain and more reliable!
(O) Open/Closed: Make your components 'open for extension but closed for modification'. What this means is that if our design has 3 ML pipelines already, then it should be the case that to add more capabilities into the solution I can just add another 1,2,3 …n pipelines. This shows the design is open for extension. If I had mandated in the design where all of my ML functionality lives in one pipeline, then I'd have to go in and modify that single pipeline to run new models and add functionality to this service. This is not very closed to modification. Note: I think this has shades of grey, you'll need to modify designs in some places, but it can be a good guide. It also definitely applies to your objects as it was originally intended for OOP – make your classes open for extension but closed for modification.
(L) Liskov Substitution: Originally this was focussed on writing code where objects/classes could be replaced by their subtypes/subclasses and still maintain the same app behaviour. Now I think we can generalise this to say that the functionality and interfaces are the important part, so swapping component A for component B should lead to no negative consequences in fundamental application behaviour if they have the same interfaces and core functionality.
(I) Interface Segregation: The idea here is that components should not have to dependend on interfaces/components they won't use. So, for example, if I have a simple design like that shown in Figure 1, having the Application Database at the end talk to the ETL pipeline or the ML pipeline talk to the upstream Datalake are bad ideas!
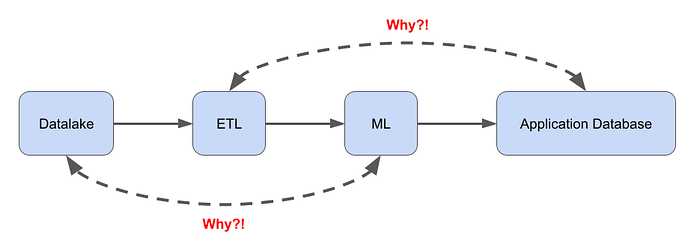
Make your interfaces specific and don't define and build large, messy, generic interfaces that interact with un-necessary components. A nice clean, well specified, REST API (as an example) is your friend.
(D) Dependency Inversion: Again, when applied to OOP, this was aimed at decoupling components or objects by having them depend on abstractions rather than directly on each other. The inversion refers to the fact that you are changing the direction of dependencies from higher level components depending on lower level to the other way around. This works really well when thinking about something like packages, where we can have a dependency from a higher level package to a lower ("import X") but instead both packages actually reference a semi-independent abstraction.
If you bear these principles in mind you will often be in a very good stead as you go on your MLOps and LLMOps journeys.
Let's now look at some resources that can help you take your architecture and design journey up a level.
AWS Architecture Lens(es) and the Well Architected Framework
A great way to get an acquainted with lots of ML architectures is to look at what the cloud providers suggest you do on their platforms. AWS in particular have done an excellent job of curating tons of very explanatory resources. In particular I like their Architecture Lens and Well Architected set of resources, which gives you lots of off-the-shelf insight. For example, if we look at their Machine Learning Lens, we get useful content on the ML project lifecycle, see Figure 2, or detailed worked diagrams for specific parts of this lifecycle, like the monitoring lifecycle diagram shown in Figure 3.
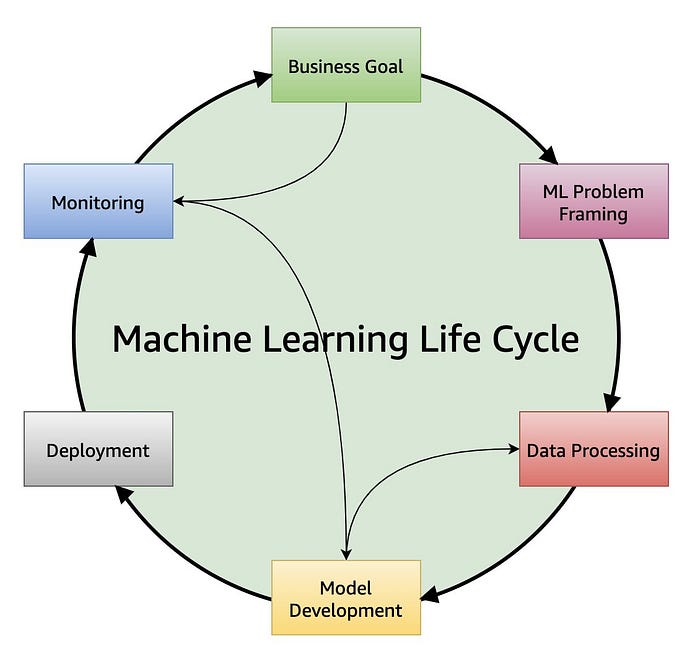
Figure 3 in particular is an example of how the ML Lens resources often provide a layered view on top of the core technologies that shows the processes. And I always feel that the processes you need to build are what really make up your solution!

Resources like this are an excellent starting point and give you alot of material to work with as you embark on building out your own solutions. It's definitely worth a look!
As a complement to this, AWS also have their Well Architected Framework, which builds on the 'Lenses' mentioned above with a series of labs you can work through and a tool for evaluating and generating useful architectural content based on your required workloads.
These resources are often quite complementary, so take a look at both. In particular I like the fact that the Well Architected framework emphasises the application of "best practices" and helps you along that journey.
These materials are very useful reading, but the real way to learn good design and architecture in my opinion is to get building. So use these in your projects but once you really get into the weeds you'll get a feeling for how far the theory is from reality and where you may have to adapt these principles and designs for the context you operate in. This is all part of the work and is what will catapult your team or organisation from interested amateur to professional Ops outfit in no time!
Note: I'm still not quite sure how these two resources are meant to differentiate themselves, but they are both useful! I think the Lenses sit under the Well Architected Framework and are specific project exemplars …
Architecture and Design Principles for LLMOps
When it comes to LLMOps (and operations for generative AI of other flavours), there are some things that are slightly different and many things that remain the same. The principles and resources above are still extremely useful and still apply in my opinion. As we move to LLMOps I would say that the differences are more in which areas we focus on and how we work to develop good practice in a domain that is so rapidly evolving.
To the point about the rapid evolution of this area, it is going to be important for platform teams, architects and use case or line of business teams to work together to constantly share knowledge and ensure rapid feedback about what designs work, what doesn't and what needs to change. Figure 5 shows a diagram that tries to emphasis some of these points.
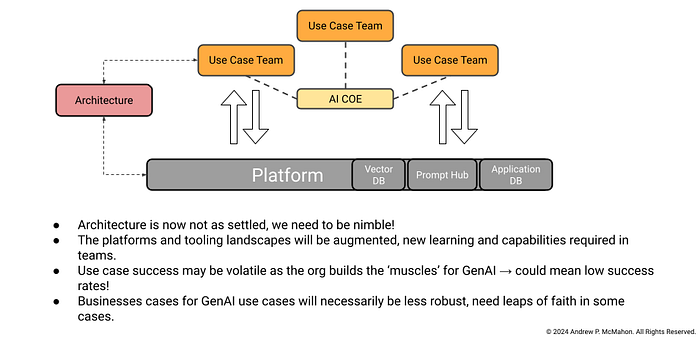
Some things that I am seeing come through (there are more I will try and cover in other posts):
- The stack is definitely changing, but many core components remain, some of these elements are new and some are just adaptations of what we've been doing before. See Figure 6.
- RAG is the basis of many applications, and I don't think it is going anywhere. There is some speculation about large context windows, such as the 1.5 million context window of Google's Gemini, killing off RAG. This is definitely a minority view and most people now seem to agree that actually long context windows are not for storing everything! They can work with far larger pieces of text, but that is not a replacement for permanent, read-accessible storage of your required corpus.
- Guardrails don't just protect, they can help standardise. From looking into a project like Nemo-Guardrails, the .yml and colang configurations for the rails actually provide a lot of nice structure to your application's LLM interactions. I think we'll see more and more of this. So guardrails can stop the LLM going out of tolerance for behavioural norms, but also help create a more predictable solution.
- Monitoring and evaluation will still be able to leverage a lot of the core processes we've built up (build a monitoring pipeline, get ground truth or not if your metric can work without it, calculate the metric(s), surface the results as alerts of telemetry) BUT the details of the datasets we use to evaluate against and the metrics we calculate still seems to require alot of ingenuity and thought. So take the time to think 'how will I monitor and evaluate my LLM system for the use case I have?'
- The understanding of security questions like how do deal with prompt injection is developing rapidly, but the operational implementation of safeguards, guardrails, content moderation and other techniques is still being proved out for many organisations and use cases. Again, take the time to experiment, experiment, experiment and complement all of this work with good red teaming. (For more information on LLMSecOps, try and catch one of Abi Aryan's presentations).
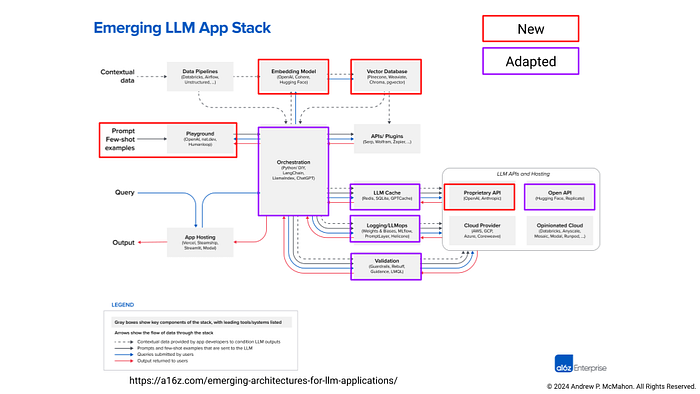
Taking all of this into consideration is important as you try and develop an architecture that will stand the test of time in terms of its general principles and data flows but also be adaptable in terms of specific components and technologies that need to be implmented as part of that architecture.
I've spoken in a lot of generalities, now let's showcase a specific example of a really nice architecture!
A RAG Architecture Example from Quantum Black
Disclaimer: I've worked with a lot of the QB team on several projects and I think they're great — apologies for not being my usual super critical self!
The Quantum Black team have written an excellent post on their work building a large scale knowledge assistant for use across McKinsey. Read that article and you'll see a brilliantly in-depth exploration of what it takes to build a great LLM based system to scale.
The design and breakdown that they provide is excellent. I've taken that and in Figures 7,8 and 9 highlighted some challenges and opportunities that I foresee as teams look to implement something similar at scale. I've also added some further details on the sort of data services I think that a system like this could hook into in Figure 8.
I'll let you read through these opportunities and challenges and ask you the question for reply in the comments, what is missing?
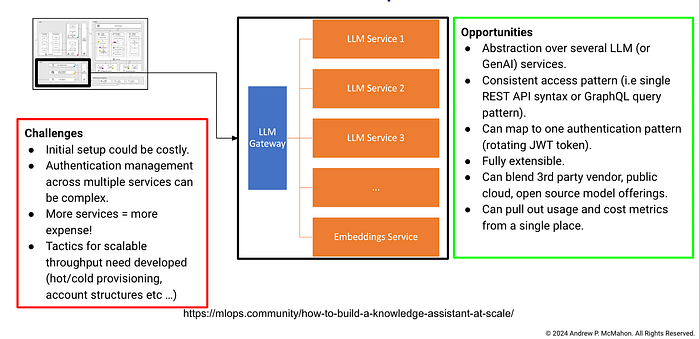
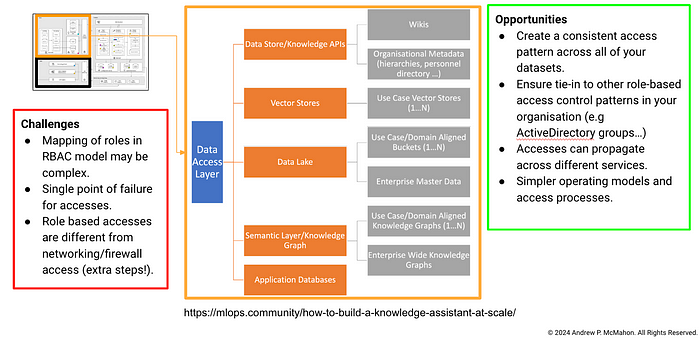
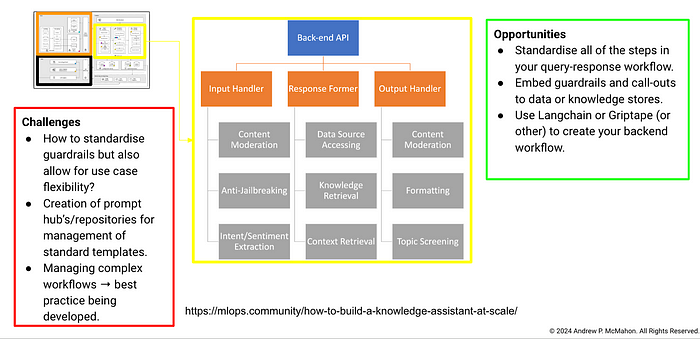
As you can see, there are many dimensions to consider for this problem that at a first glance may be easy to miss. It is going to be incumbent upon us as the Ops professionals to try and consider all of these points as we design, implement and scale generative AI use cases.
Wrapping Up
In this article I've covered a few principles and design ideas you should bear in mind as you proceed on your MLOps journey. I've also highlighted some great resources to help you on this journey and then discussed some newer considerations I have been mulling over for LLMOps. I then showed an example of a really nice architecture and discussed some of the opportunities and challenges I think it is easy to miss when you build out these new solutions.
Stay tuned for more on MLOps, LLMOps and everything in between — happy building!