
Introduction
Breaking down your large data files into more manageable segments is one of the most crucial steps for enhancing the efficiency of LLM applications. The goal is to provide the LLM with precisely the information needed for the specific task, and nothing more.
"What should be the right chunking strategy in my solution" is one of the initial and fundamental decision a LLM practitioner must make while building advance RAG solution.
In his video, Greg Kamradt provides overview of different chunking strategies. These strategies can be leveraged as starting points to develop RAG based LLM application. They have been classified into five levels based on the complexity and effectiveness.
Your goal is not to chunk for chunking sake, our goal is to get our data in a format where it can be retrieved for value later.
Level 1 : Fixed Size Chunking
This is the most crude and simplest method of segmenting the text. It breaks down the text into chunks of a specified number of characters, regardless of their content or structure.
Langchain and llamaindex framework offer CharacterTextSplitter and SentenceSplitter (default to spliting on sentences) classes for this chunking technique. A few concepts to remember -
- How the text is split: by single character
- How the chunk size is measured: by number of characters
- chunk_size: the number of characters in the chunks
- chunk_overlap: the number of characters that are being overlap in sequential chunks. keep duplicate data across chunks
- separator: character(s) on which the text would be split on (default "")
Level 2: Recursive Chunking
While Fixed size chunking is easier to implement, it doesn't consider the structure of text. Recursive chunking offers an alternative.
In this method, we divide the text into smaller chunk in a hierarchical and iterative manner using a set of separators. If the initial attempt at splitting the text doesn't produce chunks of the desired size, the method recursively calls itself on the resulting chunks with a different separator until the desired chunk size is achieved.
Langchain framework offers RecursiveCharacterTextSplitter class, which splits text using default separators ("\n\n", "\n", " ","")
Level 3 : Document Based Chunking
In this chunking method, we split a document based on its inherent structure. This approach considers the flow and structure of content but may not be as effective documents lacking clear structure.
- Document with Markdown: Langchain provides MarkdownTextSplitter class to split document that consist markdown as way of separator.
- Document with Python/JS: Langchain provides PythonCodeTextSplitter to split the python program based on class, function etc. and We can provide language into from_language method of RecursiveCharacterTextSplitter class.
- Document with tables: When dealing with tables, splitting based on levels 1 and 2 might lose the tabular relationship between rows and columns. To preserve this relationship, format the table content in a way that the language model can understand (e.g., using
<table>tags in HTML, CSV format separated by ';', etc.). During semantic search, matching on embeddings directly from the table can be challenging. Developers often summarize the table after extraction, generate an embedding of that summary, and use it for matching. - Document with images (Multi- Modal): Embeddings for images and text could be contents different (Though CLIP model support this). The ideal tactic is to use multi-modal model (like GPT-4 vision) to generate summaries of the images and store embeddings of it. Unstructured.io provides partition_pdf method to extract images from pdf document.
Level 4: Semantic Chunking
All above three levels deals with content and structure of documents and necessitate maintaining constant value of chunk size. This chunking method aims to extract semantic meaning from embeddings and then assess the semantic relationship between these chunks. The core idea is to keep together chunks that are semantic similar.
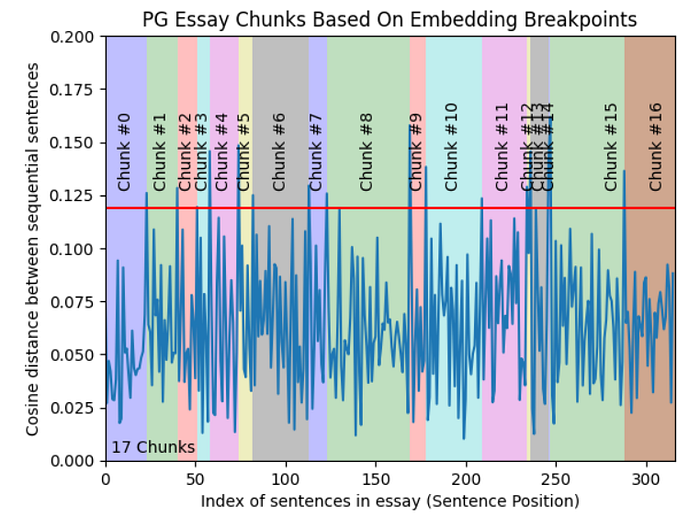
Llamindex has SemanticSplitterNodeParse class that allows to split the document into chunks using contextual relationship between chunks. This adaptively picks the breakpoint in-between sentences using embedding similarity.
few concepts to know
- buffer_size: configurable parameter that decides the initial window for chunks
- breakpoint_percentile_threshold: another configurable parameter. The threshold value to decide where to split the chunk
- embed_mode: the embedding model used.
Level 5: Agentic Chunking
This chunking strategy explore the possibility to use LLM to determine how much and what text should be included in a chunk based on the context.
To generate initial chunks, it uses concept of Propositions based on paper that extracts stand alone statements from a raw piece of text. Langchain provides propositional-retrieval template to implement this.
After generating propositions, these are being feed to LLM-based agent. This agent determine whether a proposition should be included in an existing chunk or if a new chunk should be created.

Conclusion
In this article, we explored different chunking strategies and methods to implement them in Langchain and Llamaindex framework.
To find the code from Greg: https://github.com/FullStackRetrieval-com/RetrievalTutorials/blob/main/5_Levels_Of_Text_Splitting.ipynb
As Generative AI and Machine learning is evolving faster, so I will keep updating this article. I frequently write about developments in Generative AI and Machine learning, so feel free to follow me on LinkedIn (https://www.linkedin.com/in/anurag-mishra-660961b7/)