
Stories So Far
Welcome to our final series on JPA/Hibernate best practices.
I will be referencing other articles in the series, please check them out for any in depth analysis. You can always just follow the heuristics described in this article.
Transaction vs JPA Session Boundary in Spring JPA
Getting your query execution in control
medium.com
Background
Over the last 20 years of on and off using JPA/Hibernate, I have seen tons of anti-patterns and bugs in the wild. If anyone had any experiences with JPA/hibernate, they have run into some or all of the followings:
- loading entire database into memory from accidental eager fetching
- infamous N+1 lazy fetching
- unintended eager
ToOnemapping LazyInitializationException- unintentional cascade deletes or orphaned records
- poor performance from unintended eager fetching
After experiencing these issues, I have seen some of my colleagues have grown a special dislike for Hibernate and ORM in general; and instead opted for more flexible, straight forward SQL templating frameworks. What I've discovered is that more often than not, these "troubles" on using ORM tend to stem from having inconsistent decisions during the design phase. While there certainly exists nuisance on using ORM frameworks, I still strongly believe in using ORM (Hibernate if using Java) IF we have full control over the underlying relational database schemas.
Although Spring's official JPA documentation does not go too far into how to adopt DDD principles, it is their recommended approach. Here I will share some heuristics of building a good Hibernate relationship design with help from Domain-Driven Design principles that help to avoid some of forementioned issues.
Designing the (Relational) Database Schema
Domain driven design requires us to first define the business subdomain. From there, we can define what are the aggregates/entities that we will store in our relational database. (For the rest of the article, "entities" are referring to JPA entities, not DDD's entity)
The obvious requirement to create the ideal hibernate mappings for your database entities is to first get the schema design right. But before you do, create a component diagram that explains the relationships between your components.
"DO NOT start with Hibernate entity design. Create the entity relational diagram (ERD) first. Then, you can move unto ORM mappings"
Let's say we have the following entities.
Customer
Customer Home Address
Order
Order Line: where it has count of each product
Shipping Address
Product
Product Category
ProductA very basic pseudo entity relational diagram that explains relationship between them may looks like this
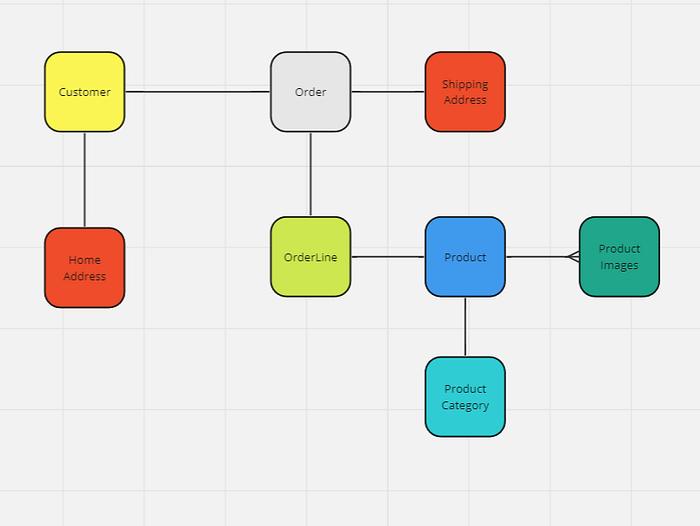
One of the key decisions we could make at this stage is to share a same table for bothShippingAddressand HomeAddress So we now end up with 6 tables: customer order address orderline product product_category
Now updated with some OneToMany relationships
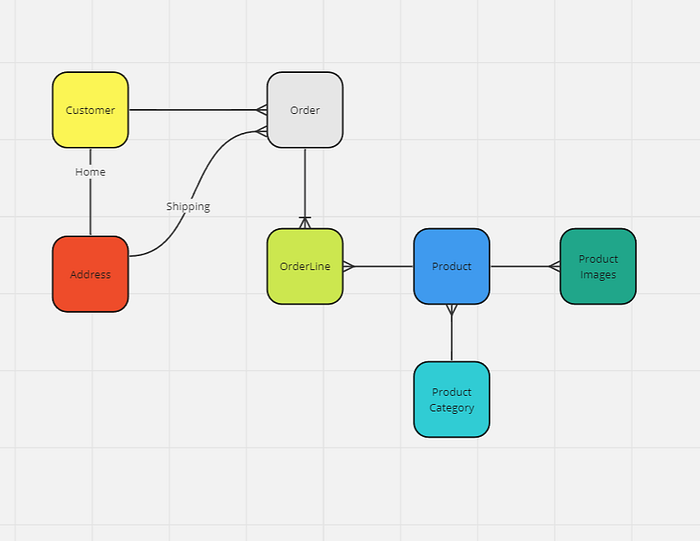
Finding the Aggregate Roots
In DDD, aggregate root is "an entity that acts as a gateway to the entire aggregate, ensuring that the integrity and consistency of the aggregate are maintained." In a much simpler term, what are your primary and most relevant/important entities for your service? That will depend on the business context. Let's assume that we are building a monolith service that will serve all these entities and business requires us to have following requirements.
- We need to easily retrieve customers by their email address.
- We need to easily retrieve customer's home address
- We need to easily retrieve orders from a given customer.
- We need to easily retrieve information from a given order including different products in the order as well as quantity of each product.
Given the requirements above, we group the entities with Customer Order Product as the Aggregate Roots. This also means that all database queries should only query against these aggregate root entities. e.g) You shouldn't create a SQL query selecting on Address table; Address should only be accessed by traversing through Customer or Order entity.
In other words, we should only have CustomerRepository OrderRepository ProductRepository (Do not cheat by defining custom queries inside the repositories "select"ing on a different entity than the aggregate root entity the repository was meant for.)
Heuristic 1: Spring Repository should only be defined for Aggregate Root Entities
Once the aggregate roots are defined, we can use this information to help us define the Hibernate Mappings for each entity.
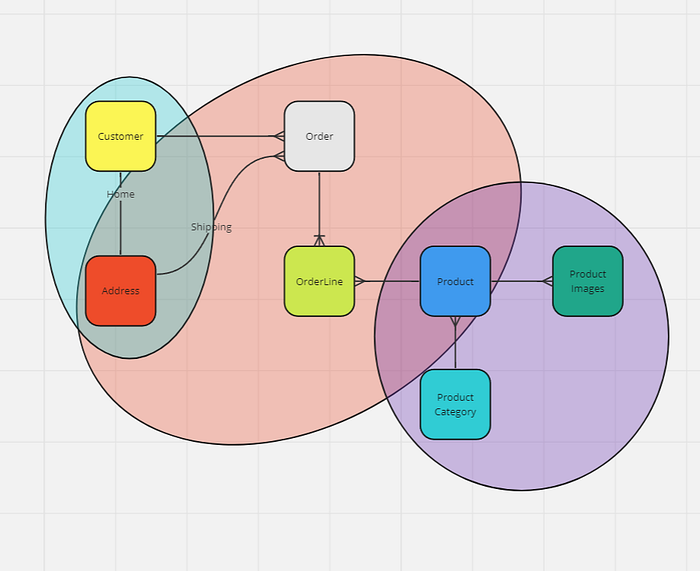
This also means that we will assume our application only has CustomerRepository OrderRepository and finally ProductRepository. Other entities can only be indirectly referenced by querying for these three Aggregate Roots.
Four Decisions to Make when creating Hibernate Relationship Mapping
- Creating Relationship Mapping or Not
- Uni or Bidirectional Relationship
- Lazy or Eager Fetching
- What to Cascade, or Not
Deciding to Create Relationship Mapping or Not
One of the biggest anti-patterns when it comes to Hibernate mapping is creating mapping for every relationship in ERD. Just because the relationship exists, it does not mean the Hibernate mapping must exist; we could instead just keep the foreign key as just a normal attribute.
The best way to avoid ill-formed relationship mapping is to not have one at all!
As described in my previous article, you do not need to always create a mapping. For instance, HomeAddress does not have to be an entity, it could just be a Value object. In JPA, this would be done by using @Embeddable and @Embedded annotations.
Heuristic 2: Within Aggregate, consider using Value object instead of@OneToOne or even some@ManyToOne
Another place where a strong consideration is required on whether to create a relationship mapping or not is when an Aggregate Root is related to another.
In our application, Customer can have many Orders. But these are both Aggregate Roots. It would be easy to always create mapping, it becomes difficult to manage and fine tune SQL performance when fetching across Aggregate Roots. I have also seen the entire database being loaded into memory due to recursively eager fetching all aggregate roots in the system.
Heuristic 3: Try to avoid mapping relationships across Aggregate Root, just map the foreign key as is.
Following this heuristic, we would only have Long customerId within Order entity. In order to load both a customer info as well as all of the orders of the customers, two separate repository calls would have to be made.
Sometimes, having the relationship is convenient over always needing to make another repository call to fetch the related Aggregate Root entities. Creating the mapping to another Aggregate Root should only be considered if the number of related entities is finite. In other words, it should be either *ToOne relationship OR in case of *ToMany relationship, your business logic does not allow the relationship to grow more than certain boundary.
Heuristic 4: Mapping relationship to another Aggregate Root should only be allowed if the relationship is bound.
For example, if ProductCategory is also defined as Aggregate Root, (Let's say there is a need to configure what category is, how can manage it, which organization can has access to administer it, etc.) Association from Product to ProductCategory could still be mapped since it's bound since Product can only be associated to a single category. (in our example) Even if a product can be associated to multiple categories, (ex: a book about pregnancy could be part of "Maternity", "Baby", "Book" categories) the number of associated categories would never grow more beyond a certain point. Conversely, Customer to Order relationship can grow infinitely as a customer makes more orders.
Uni or Bidirectional Relationship
It is easy to always create bidirectional relationships thinking it offers us the most flexibility, allowing us to traverse via both directions, but as we discussed in the previous article, this comes with the extra burden of keeping them in sync.
Heuristic 5: Always start with Unidirectional Relationships. Only convert to Bidirectional Relationship as need arises AND when the relationship does not cross Aggregate Roots.
For example, Order to OrderItem could have bidirectional relationships since only Order is the aggregate root.
Lazy or Eager Fetching
Lazy Loading is a design pattern that we use to defer initialization of an object as long as it's possible. Refer to my previous article for in depth discussion.
When you have multiple business use cases that require querying for one of the Aggregate Roots, which data from its associated entities may differ depending on each use case. Controlling which association in the relationship hierarchy by fine tuning the query can be done via multiple strategies. (Discussed in the same previous article)
Heuristic 6: Start with Lazy Fetching all child relationships from the Aggregate Root. Convert to eager fetching only if the related entity is ALWAYS REQUIRED
Since all of our queries start with an aggregate root, only time another aggregate root would be associated via the original children would be from ToOne or bounded ToMany relationship. These relationships may warrant lazy loadings due to possible deeply nested loads from eagerly fetching another aggregate root object. BE CAREFUL OF ToOne LAZY LOADS!
Heuristic 7: If you (happen to) have relationship to another aggregate root, never use eager fetching."
Cascading
JPA cascade refers to a feature that allows you to define how operations performed on an entity should propagate to related entities. When you use cascade in JPA, you specify that an operation (like persist, merge, remove, etc.) performed on a parent entity should also be performed on its associated child entities automatically. It is defined with cascade parameter of the relationship annotation.
If we correctly defined our entities and the aggregate root entities, then heuristic for cascading is simply
Heuristic 8: Cascade ALL non aggregate root entities. Cascade Nothing for associated aggregate entities
So, What Ifs
Here is a list of what ifs and my recommendation for each. Again, these are just recommendations, not rules.
A business requirement is stretching across two aggregate roots
Example: Provide a list of orders for customers that have home address in California.
Solution: Query for list of IDs of customers in California. Then Query for list of orders matching the customerIDs.
A new business requirement changes an entity from a non-root aggregate to aggregate root.
Example: Product Image is uploaded by administrators that requires direct ways to query and search for them.
Solution 1: Update the mapping to the recommended approach for dealing with aggregate root.
Solution 2: This defines a new bounded context. Consider breaking the feature out to another microservice. e.g) Image Admin Microservice vs Shopping Microservice.
Wrapping Up
Today we discussed how Domain Driven Design concept can be applied to designing JPA/Hibernate relationships.
Here are the eight heuristics.
Heuristic 1: Spring Repository should only be defined for Aggregate Root Entities
Heuristic 2: Within Aggregate, consider using Value object instead of@OneToOne or even some@ManyToOne
Heuristic 3: Try to avoid mapping relationships across Aggregate Root, just map the foreign key as is.
Heuristic 4: Mapping relationship to another Aggregate Root should only be allowed if the relationship is bound.
Heuristic 5: Always start with Unidirectional Relationships. Only convert to Bidirectional Relationship as need arises AND when the relationship does not cross Aggregate Roots.
Heuristic 6: Start with Lazy Fetching all child relationships from the Aggregate Root. Convert to eager fetching only if the related entity is ALWAYS REQUIRED
Heuristic 7: If you (happen to) have relationship to another aggregate root, never use eager fetching.
Heuristic 8: Cascade ALL non aggregate root entities. Cascade Nothing for associated aggregate entities
Please let me know if you have your own set of heuristics.
Next time, we'll cover some miscellaneous pitfalls on JPA/Hibernate to avoid.