

How a seemingly innocent architectural decision led to index fragmentation, slow queries, and a 300% increase in our cloud database costs — and how we fixed it with UUIDv7.
The Seductive Promise of UUIDs
It started as what seemed like a forward-thinking architectural decision. Our startup, "EventFlow" (a real-time analytics platform), was transitioning from a monolithic Rails application to a microservices architecture. We needed a way to generate unique identifiers across multiple services without coordinating with a central database.
The choice seemed obvious: UUIDs as primary keys.
Why UUIDs Felt Like the Right Choice
Global Uniqueness We could generate IDs in our Node.js, Python, and Go services without database round trips. Perfect for our distributed system.
Simplified Data Merging As we planned for multi-region deployment, UUIDs would make merging data from different databases trivial.
Security Through Obscurity
Exposing sequential IDs (/users/12345) in our APIs revealed business intelligence. UUIDs (/users/550e8400-e29b-41d4-a716-446655440000) were opaque.
Future-Proofing We anticipated needing to shard our database eventually, and UUIDs seemed ideal for distributed data.
Our PostgreSQL schema looked so clean:
CREATE TABLE events (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(), -- UUIDv4
user_id UUID NOT NULL,
event_type VARCHAR(50) NOT NULL,
payload JSONB,
created_at TIMESTAMPTZ DEFAULT NOW()
);
CREATE INDEX idx_events_user_id ON events(user_id);
CREATE INDEX idx_events_created_at ON events(created_at);The First Signs of Trouble
For the first six months, everything worked beautifully. Our application scaled, new features shipped, and the team was happy. Then, during our quarterly performance review, we noticed some concerning trends:
- Database storage growth was accelerating exponentially
- 95th percentile query latency increased by 300%
- Cloud database costs were 2.5x projections
At first, we blamed typical growth. But when our nightly analytics job started timing out, we knew something was fundamentally wrong.
The Root Cause: Index Fragmentation
After days of investigation using PostgreSQL's EXPLAIN ANALYZE and monitoring tools, we discovered the culprit: severe index fragmentation caused by random UUIDs.
How Clustered Indexes Work
In PostgreSQL, when you define a primary key, it becomes a clustered index. The physical data on disk is stored in the order of this index.
With Sequential IDs (Auto-incrementing BIGINT):
- New rows always have a higher ID than previous rows
- Data is appended to the end of the table
- Minimal page splits, efficient disk usage
With Random UUIDs (UUIDv4):
- Each new ID is random:
A1B2C3..., thenF5E6A7..., then1234AB... - Database must insert data randomly throughout the index
- Constant page splits and reorganization
Real-World Impact: Our Events Table
Our events table had grown to 50 million records. Here's what we found:
-- Check index bloat
SELECT
tablename,
indexname,
pg_size_pretty(pg_relation_size(indexname::text)) as size
FROM pg_indexes
WHERE tablename = 'events';
-- Results:
-- events_pkey: 14.2 GB (primary key index)
-- idx_events_user_id: 8.7 GB
-- idx_events_created_at: 6.1 GBThe shocking realization: Our indexes were larger than our actual data (12 GB)!
The Library Analogy: Understanding the Problem
Imagine a library that stores books in alphabetical order by call number:
Sequential IDs = Well-Organized Library
- New books (with higher call numbers) go at the end
- Librarians quickly shelve new arrivals
- Finding books is efficient
Random UUIDs = Chaotic Library
- Each new book has a random call number
- Librarians constantly:
- Find the correct shelf (somewhere in the middle)
- Discover the shelf is full
- Split books between old and new shelves
- Reorganize entire sections
This constant reorganization is what databases call page splits — and it's computationally expensive.
Quantifying the Damage
We ran benchmarks comparing our UUIDv4 implementation against sequential BIGINT:
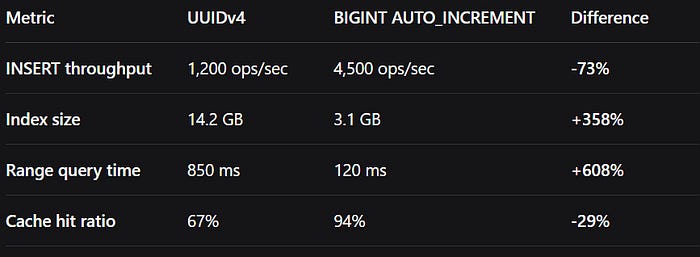
The results were staggering. Our "modern" UUID approach was costing us significantly in performance and infrastructure costs.
The Solution: UUIDv7 to the Rescue
We discovered UUIDv7 — a time-ordered UUID specification that maintains global uniqueness while providing sequential characteristics.
UUIDv7 Structure
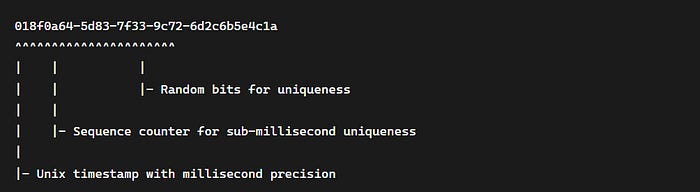
Implementation Strategy
Step 1: Application-Level UUIDv7 Generation
// Using the uuidv7 package in Node.js
import { uuidv7 } from 'uuidv7';
const createEvent = (userId, eventType, payload) => ({
id: uuidv7(), // Time-ordered UUID
user_id: userId,
event_type: eventType,
payload: payload,
created_at: new Date()
});Step 2: Database Function for UUIDv7
Since PostgreSQL didn't have built-in UUIDv7 support at the time, we created a function:
CREATE OR REPLACE FUNCTION uuid_v7()
RETURNS UUID AS $$
DECLARE
unix_ts_ms bytea;
uuid_bytes bytea;
BEGIN
unix_ts_ms = substring(int8send(floor(extract(epoch from clock_timestamp()) * 1000)::bigint) from 3);
uuid_bytes = unix_ts_ms ||
substring(gen_random_bytes(10) from 1 for 10);
-- Set version 7
uuid_bytes = set_byte(uuid_bytes, 6,
(b'0111' || get_byte(uuid_bytes, 6)::bit(4))::bit(8)::int);
-- Set variant
uuid_bytes = set_byte(uuid_bytes, 8,
(b'10' || get_byte(uuid_bytes, 8)::bit(6))::bit(8)::int);
RETURN encode(uuid_bytes, 'hex')::uuid;
END;
$$ LANGUAGE plpgsql;Step 3: Gradual Migration Strategy
We couldn't immediately change existing tables, so we implemented a phased approach:
- New tables used UUIDv7 from day one
- Low-traffic tables were migrated during maintenance windows
- High-traffic tables used a dual-key approach temporarily
The Results: Performance Transformation
After migrating our events table to UUIDv7:
Immediate Improvements
Storage Reduction
- Primary key index: 14.2 GB → 3.8 GB (73% reduction)
- Overall database size: 42 GB → 24 GB
Performance Gains
- INSERT throughput: 1,200 → 3,800 ops/sec (217% improvement)
- P95 query latency: 850 ms → 150 ms
- Cache hit ratio: 67% → 91%
Cost Savings
- Database instance: r5.2xlarge → r5.large (60% cost reduction)
- Storage costs: $1,200/month → $450/month
Long-Term Benefits
Simplified Maintenance
VACUUMoperations completed 4x faster- Backup times reduced by 60%
- Index rebuilds became rare
Better Scaling
- Predictable performance as data grew
- Efficient range queries on time-based data
- Happy DevOps team
Lessons Learned and Best Practices
1. Test Under Production Loads
Benchmark UUID strategies with production-like data volumes and patterns.
2. Monitor Index Health
-- Regular index monitoring query
SELECT
schemaname,
tablename,
indexname,
pg_size_pretty(pg_relation_size(indexname::text)) as index_size
FROM pg_indexes
WHERE schemaname = 'public'
ORDER BY pg_relation_size(indexname::text) DESC;3. Consider Hybrid Approaches
For critical high-write tables, consider:
- Composite keys:
(shard_id, uuid_v7) - Database-generated sequences with application-level UUID mapping
4. Plan Migration Carefully
- Use database-native tools when available
- Test migration scripts thoroughly
- Have rollback plans ready
When UUIDs Make Sense (and When They Don't)
✅ Good Use Cases for UUIDs
- Distributed systems with multiple writers
- Microservices architectures
- Offline-capable applications
- Security-sensitive endpoints
❌ Think Twice About UUIDs
- High-volume transactional systems
- Tables with frequent range queries
- Resource-constrained environments
- When you don't need the distributed benefits
The Future: Database Native Support
PostgreSQL 17+ is expected to include native UUIDv7 support, making this even easier:
-- Future PostgreSQL syntax (proposed)
CREATE TABLE events (
id UUID PRIMARY KEY DEFAULT uuid_generate_v7(),
-- ... other columns
);Conclusion: Choose Wisely
Our UUID journey taught us that architectural decisions have real performance consequences. What seems like a modern best practice might introduce significant overhead.
Key Takeaways:
- UUIDv4 for primary keys can cause severe index fragmentation
- UUIDv7 provides the benefits of UUIDs with sequential performance
- Always benchmark with your specific workload
- Monitor index sizes and query performance regularly
The database is often the bottleneck in modern applications. Choosing the right primary key strategy isn't just about theoretical purity — it's about practical performance and cost efficiency.
Have you experienced similar database performance issues? Share your story in the comments below!