
In an industry as hyped as Generative AI, it's more important to know the things that don't work than those that do. However, knowing what's true and provable and what's empty hype is not something that standard media or incumbents will let you see.
Therefore, that type of content goes largely unnoticed, as these labs and corporations need society to believe AI is as 'smart as a PhD,' while, as you'll see today, that's simply a despicable lie.
And after the industry went full hype-mode with the release of OpenAI's o1 models — a brand new part of the ChatGPT platform that allegedly excel at reasoning — the first research-based results are starting to come out and, well, it's a bag of mixed feelings.
Regarding one of the key features AI must conquer, planning, the verdict is clear: AI still can't plan. In the process, I'll show you their primitive, expensive, and, most concerningly, deceiving nature, leading us to the trillion-dollar question:
Are foundation models actually worth it?
This is an extract from a previous article in my newsletter.
Get insights like this before anyone else by subscribing to TheTechOasis, the place where analysts, strategists, and executives get answers to AI's most pressing questions.
It's Progress, but It's Still Bad
Planning is an essential capability that has obsessed AI researchers worldwide for decades. It allows humans to face complex problems, consider the global picture, and strategize the best solution; it's one of the key features that separates us from the rest of animals.
In particular, planning is essential when facing open-ended questions where the solution isn't straightforward, and some search must be done to identify the best solution. Planning not only elucidates feasible options but also breaks down the problem into more straightforward tasks.
Most complex world problems fall into this definition, so almost nothing would be done without planning.
Sadly, LLMs are terrible at planning.
One of the Hardest AI Problems
When taking our state-of-the-art LLMs and testing them into planning benchmarks with examples like the task below, which are simple to solve for humans:
The results are discouraging, with the results on the 'Mystery Blocks world' benchmark being a net 0% of correct questions across ChatGPT, Claude, Gemini, and Llama.
This isn't that surprising, considering all these are System 1 thinkers. This means they can't iterate over the question to find the best possible solution, and instead, we simply expect them to get the correct plan in one go, something that even humans would struggle with.
But as I discussed two weeks ago, o1 models represent this precise paradigm shift, allowing them to explore possible solutions and converge on the right answer.
However, the results are underwhelming, but not for the reasons you think.
Overconfident and Dumb
At first, things look great. When evaluated on the same dataset, o1 models considerably improve the outcomes, saturating the first benchmark (97.8% accuracy) and increasing the results from GPT-4o's net 0% to 57% with o1-preview.
It seems like a really promising improvement, right?
Yes, but if you look carefully, things get ugly. For starters, if we increase the number of steps to solve the plan, accuracy will quickly crash, going back to 0% when the plan requires 14 steps or more.
We also need to consider the costs.
As you know, these models are sequence-to-sequence models (they input a sequence, and they give you one back). Thus, the cost of running these models is metered by the amount of input and output tokens, aka how many tokens they process and how many they generate.
Usually, the generating costs are around 5x the processing costs, meaning that the more tokens you generate, the worse. Sadly, this goes entirely against the nature of o1 models.
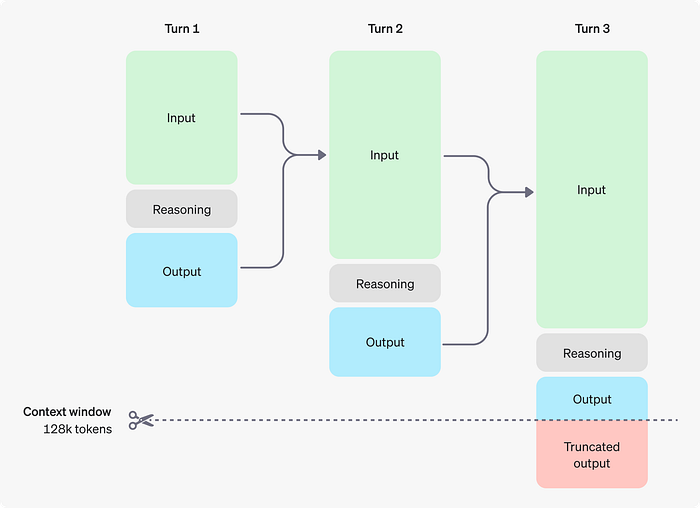
As they reason over their own generated output tokens (image above), they generate more tokens by design, sometimes reaching 100 to 1,000 times the average output size of GPT-4o. This leads to o1-preview being 100 times more expensive than the previous generation, and only because OpenAI is heavily subsidizing the costs on our behalf (aka the model should be much more expensive).
Concerningly, the model also overthinks too much. If we look at the table below, to solve a 20-step plan (which in this research's case refers to a plan that requires rearranging blocks 20 times), the model has to generate 6,000 tokens, or 4,500 words (1,500 more than this entire newsletter), to find the answer.
And that's the low bound of the image below, considering this is one-shot (the model can explore, but it's given only one try to get the answer correct).
Long story short, with o1 models, costs are going to literally explode, as OpenAI researchers want them to, eventually, think for entire weeks before answering. Seeing the incremental improvements over the previous generation, you may think it's worth it.
But… is it?
Are o1 Models Actually Worth it?
This research perfectly clarifies the biggest issue with current AI models: the depth vs breadth problem. No matter how broad we go, deep models still put LLMs to utter shame.
Cost Effectiveness
Unlike o1 models, claimed to be the 'smartest AI models alive,' another AI planning mechanism, Fast Downward, an AI that has been around since 2011, manages to get 100%, humiliating the mass-proclaimed 'state-of-the-art models.'
Importantly, Fast Downward is fast and very cheap to run. It is several orders of magnitude more cost-effective than o1 models and has three times better performance at the bare minimum.
Fast Downward works similarly to o1; it uses a search heuristic to iterate until it finds the best answer. The key difference is that, unlike o1 models, which are hundreds of GB in size (or TeraBytes) it's small (no LLM) and task-specific, meaning it can perform this search at a scale that o1 simply can't.
To make matters worse, researchers also tested models in 'unsolvable plans,' which led to concerning results.
One Hell of a Gaslighter
When evaluating whether AIs can acknowledge a plan is unsolvable and not try to solve it no matter what, o1 is convincingly… mostly incapable of doing so.
As shown below, o1-preview identifies a problem as unsolvable only 16% of the time. This leads to a plethora of different examples where the model generates completely unfeasible and stupid conclusions while being extremely eloquent about it, making it look more like a professional gaslighter.
In my newsletter, we already covered in detail why LLMs are already professional bullshitters.
This leads me to an unequivocal realization:
Maybe LLMs aren't dangerous to humanity because they are too powerful, as {insert Big Tech CEO} will tell you, but because they are 'convincingly flawed' they deceive us into using them in complex situations they can't manage, leading to disastrous consequences.
In a nutshell, a simple combination of GPT-4o with the ability to call Fast Downward would lead to performance that is orders of magnitude better than o1 models without all the extra gaslighting and outsized costs.
That makes you wonder, is this new paradigm worth it?
A New Form of Evaluating
As I discussed recently, incumbents are already factoring in Giga-scale data centers and models that cost hundreds of billions to train and hundreds of millions to run, probably considering o1-type models as 'the new normal.'
But as we've seen today, their promises are largely unfulfilled, and even if they are showing progress, they are still lagging behind 10-year-old AI algorithms running for 100,000 times less costs and with more outstanding performance.
Now, if you ask Sam Altman, he will tell you that a larger scale (larger model and larger training and inference budgets) will not only leave narrower solutions like Fast Downward obsolete and, in the process, 'discover all of physics.'
But let me be clear on this: this belief is based on absolutely nothing but the zealous conviction that larger compute budgets lead to larger outcomes, but no one, and I mean no one, can prove it to you.
Thus, whether you believe them or not is largely dependent on whether you trust people who are economically incentivized to spur those precise words.
A very promising 'best-of-both-worlds' solution is specialized generalists, foundation models that are fine-tuned extensively to perform better in a given task, which is why I am so bullish on LoRA-Augmented LLMs.
We Need To Meter Costs
We need to start looking at costs.
It's all fun and games when you only care for increasing performance 1%, even if that 1% requires millions of dollars more.
For that reason, it's crucial that we start measuring 'intelligence per watt,'; talking to AIs is fine but pointless if you need an average US home's entire monthly energy consumption to make a plan a human could do by itself.
But you probably won't see that happening anytime soon because then the picture becomes horrific to investors, and every single dollar invested in the industry is going into this precise yet uncertain vision.
In the meantime, Silicon Valley will simply gaslight you with the preach, 'Worry not mortal, bigger will yield better.' And while that has been true until now, when are we going to question whether it's worth it?
Nevertheless, a trillion dollars later, LLMs still can't consistently perform math, make simple plans, or acknowledge their own mistakes.
What makes us think an extra trillion dollars will do the trick? You know the answer by now: AI is a religion, not a science.
And I'm not hating on religions; humans need faith to make sense of their world, and that's totally fine. But I don't think it's ok to sell us blind faith as certainty when faith-based arguments are served as 'truth' to gaslight a society that knows no better.
Religion is regarded by the common people as true and by the rulers as useful.
— Seneca
LLMs or LRMs might be the answer, but we don't know for certain. Remember that.
For business inquiries on AI strategy or analysis, reach out at nacho@thewhitebox.ai
If you have enjoyed this article, I share similar thoughts in a more comprehensive and simplified manner for free on my LinkedIn.
If preferable, you can connect with me through X.