


Choosing the best Primary Key to use in your SQL database is often a balancing act. When architecting modern distributed systems, teams often prefer to go for globally unique GUIDs (UUID), rather than the classic and generally better performing option of an INT or BIGINT Identity column. I have always been a big fan of using GUID Primary Keys; I'll explain why and demonstrate how the performance impact of using GUIDs for your PKs can be mitigated.
In this article I'll cover some different approaches for designing your SQL tables when using a GUID as your Primary Key. We'll look at some benchmarks to see how the different approaches affect performance, and also cover some additional performance optimizations that helped for our particular use-case. I'm using .NET, Entity Framework Core and SQL Server to demonstrate the different approaches, however the techniques used will apply to any language and any flavour of SQL.
Why use a GUID as your Primary Key?
If SQL performs best using numeric PKs, then why use a GUID..?!
Application Generation
The power of a GUID comes from the fact that by definition it is 'Globally Unique'. That means that our consuming app can safely generate the value of the PK itself, without waiting for a response from the database. Numeric PKs are usually associated with an auto-incrementing Identity, where our app won't know the value until after the record is committed to the database.
I'm a huge fan of Domain-Driven Design, which promotes encapsulating as much of your business/domain logic as possible in your Entity classes. Having your database generate your Entity's most important property, it's ID, is a huge violation of one of the core principles of DDD.
Security and Privacy
Unlike numeric Identity columns, UUIDs do not follow a predictable pattern. This can enhance security and privacy by making it more difficult for attackers to guess or infer the sequence of inserted records. Auto-incrementing IDs also give-away details to your customers about how much data is in your database tables; depending on your use-case this could also be an issue.
Drawbacks of using a GUID as your Primary Key
Unfortunately, there are also some big disadvantages to using GUIDs as your Primary Keys as well. Before we get to the drawbacks, there's some relational database concepts that you need to understand first.
Fragmentation
Fragmentation occurs in a database when data is not stored contiguously on disk or in memory, leading to inefficient access patterns. There are two types of fragmentation:
Internal Fragmentation:
When storage space within a database page (or block) is not fully utilized. For instance, if a page has room for 100 rows but only 80 are stored, the remaining space is wasted, leading to inefficiency.
External Fragmentation:
When the logical order of data does not match the physical order on disk. For example, if records are stored in a random order due to non-sequential inserts (such as when using GUIDs), the database may need to jump around to different locations on disk to retrieve data, leading to slower performance.
Page Splits
A page split occurs when a database page (a fixed-size block of storage, typically 8 KB in many systems) becomes full and additional data needs to be inserted.
- Initial State: Imagine a page that can hold 100 rows of data, and it is currently at capacity.
- Insertion Trigger: When a new row needs to be inserted, and the page is full, the database engine must find a way to accommodate this new row.
- Splitting Process: The database engine will split the full page into two pages, leaving space for future inserts.
- Impact: I/O is required to allocate the new page, move existing rows and update indexes to reflect the new page structure.
Clustered Index
A Clustered Index determines the physical order of data in the table. Because of this, there can be only one clustered index per table. By default, the Primary Key is used as the Clustered Index.
Due to the impact of Fragmentation and Page Splitting, the most effective Clustered Index will be a sequential key with a predictable order. This will allow SQL to efficiently fill pages at the end of the table's data, leading to better performance and less space required to store data and indexes.
Drawbacks of a GUID Primary Key
Assuming that your GUID Primary Key is also you Clustered Index, your data will be stored out of order and you will see extremely high Fragmentation and Page Splitting in your tables. This will lead to poor performance as your data volumes grow.
GUIDs are also 16 bytes compared to 4 bytes for Integers. Larger keys mean more storage and longer index traversal times. Your Clustered Index is also stored in any Non-Clustered Indexes as well, doubling this storage penalty.
Does it really matter?
We all know that Software Architecture requires striking the right balance for the problem that you're trying to solve. Here we are looking at a trade-off between performance and scalability vs security and app functionality. My personal view is that having a GUID PK which my app can generate, far outweighs the performance advantage that a numeric PK can offer.
The reality is that this decision will have a negligible impact on your application unless your data is in the 100s of thousands of rows at least. It also depends on how important performance and scalability is for your use-case.
Luckily there are options for optimizing performance if you do decide that having a GUID PK is essential for you.
Benchmarks
Let's take a look at an example table which uses GUIDs for its Primary Key and Clustered Index. We will apply some performance optimizations and use a benchmark to compare.
Baseline Implementation
The examples use a table which stores a JSON serialized array of events in a varchar(max) column. This is a very simplified use case for storing Event Streams in SQL when using Event Sourcing. When using Event Sourcing, Event Streams will always be queried and updated using their ID.
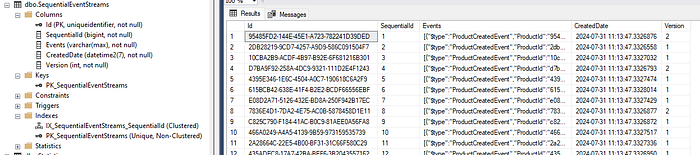
I prefer to use Entity Framework Core 'code-first' migrations to manage changes to the database schema. This can be achieved using an IEntityTypeConfiguration as shown above. The generated baseline table schema and some Event Stream data is shown below.

Here we can see that the data is not stored in the same order as inserts because the CreatedDate value jumps around for each row. This will cause significant fragmentation and page splits.
The benchmark inserts 6 million Event Stream rows into the relevant table and subsequently makes 1.2 million updates to the data. The benchmarks are run in parallel across 12 threads. The full benchmark code can be found in my GitHub here.

Optimization #1: Non-Clustered Primary Key
The baseline implementation uses the GUID Id column for both the Primary Key and Clustered Index. Having a non-sequential GUID Clustered Index is the issue.
Instead, we can change the GUID Id to a Non-Clustered Index. We can also add an additional column for the Clustered Index which uses an auto-incrementing numeric Identity column. The new Identity column will ensure that our data is stored in a sequential order. This will ensure that data is always inserted into the end of the table, so that minimal fragmentation and page splitting occurs.
A new SequentialId column must be added to our SequentialEventStream implementation, however our app doesn't need to use it for anything else. We will continue to query by the GUID Id using the new Non-Clustered Index.
We can now see that data is stored in the table in the order that it was inserted.
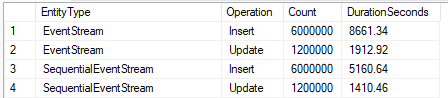
Storing the Event Streams in a sequential order has a dramatic effect on performance. Inserts were 40% faster and Updates were 26% faster across the benchmark.
Optimization #2: Sequential GUID Primary Key
The first optimization is a massive improvement; however, it requires making a big change to the table schema. We can also achieve a sequential ordering for data by using a sequential GUID. The newer UUID v7 specification actually requires time-ordered values to achieve this. There are also lots of libraries out there that you can use to generate sequential GUID/UUIDs; in this example I am using the SequentialGuidValueGenerator built directly in Entity Framework Core.
One of the big benefits of this implementation is that the schema of the original table does not have to be changed at all.

The benchmark runs in parallel across 12 threads to mimic a distributed system. This can cause the generated GUID Ids to be slightly out of order, however this shouldn't have a big effect since all inserts will still be at the end of the table.
This optimization was even faster than the previous implementation. We are now achieving 48% faster Inserts and 36% faster Updates than the original baseline. This additional increase in performance is due to not requiring an additional Non-Clustered Index anymore. Non-Clustered Indexes require an additional lookup to the Clustered Index when querying data and they must also be maintained when inserts occur.

Optimization #3: Compression
The final optimization is not related to the GUID Primary Key; however, it is interesting to understand. Since the data stored in the Events column is a JSON string, it should compress down fairly well.
The Events data can be compressed using GZip and a custom Entity Framework ValueConverter.
The values must now be stored in a varbinary column instead of a varchar column.

Using the sequentially ordered GUID Primary Key and GZip compression results in 51% faster Inserts 48% faster Updates across the benchmark.
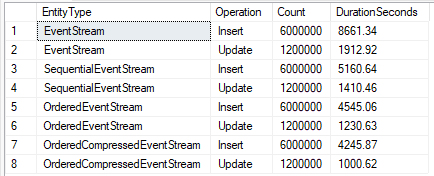
Both of the optimizations discussed here are great ways of boosting the performance of your app when using GUID Primary Keys. The option that you choose will depend on whether you already have data in your tables and how easy it is to introduce schema changes to your database.
If you have less than 100k rows of data, it is unlikely that either of these optimizations will have any effect on performance. However, if you aren't sure how big your data may get in the future, then there's absolutely no harm in using a Sequential GUID for your ID from the start!
The code for all of the benchmarks in this article can be found on my GitHub below.