
In the realm of Computer Vision, a shift is underway. This article explores the transformative power of Foundation Models, digging into their role in reshaping the entire Computer Vision pipeline.
From conceptual shifts to the integration of cutting-edge models like CLIP, SAM, and GPT-4V, we show you how and why we believe Computer Vision is ready to land into uncharted territories, where a Data-Centric way remains the right approach to follow in setting up production-grade AI systems.
Table of contents
- What is different: Foundation Models
- The promised land: CLIP + SAM + GPT-4V + …
- The current Computer Vision pipeline
- The new Computer Vision pipeline
- Conclusions
1. What is different: Foundation Models
1.1. What is a Foundation Model?
"We define foundation models as models trained on broad data (generally using self-supervision at scale) that can be adapted to a wide range of downstream tasks." Stanford Institute for Human-Centered AI (HAI)
For instance, Grounding DINO [1], a zero-shot object detection model that extends DINO [2], can be employed to detect arbitrary objects in various contexts. This adaptability is attained by leveraging the knowledge and representations acquired during the foundational training.
1.2 The rise of Foundation Models in Computer Vision

Figure 1 details the evolution of Computer Vision from a Foundation Model angle. We can see four main categories: Traditional Models (1998), Textually Prompted Models (2021), Visually Prompted Models (2021), and Heterogeneous Models (2023).
For every group, there is one particular model that accelerated the speed of evolution 🚀. For instance, Traditional "Inputs <Model> Output" Models, have evolved from LeNet and progressesed through AlexNet [5], VGG [6], InceptionNet [7], ResNet [8], and accelerated with Vision Transformer (ViT) [9].
Despite some controversy with respect to whether or not Computer Vision is Dead. The truth is that Computer Vision is evolving in parallel to other major breakthroughs in Artificial Intelligence (e.g., LLMs, Diffusion Models).
1.3 Enters GPT-4V!
The current pinnacle of Vision in the Generative AI (GenAI) domain (given that Gemini isn't fully available yet) is GPT-4V [4].
The following example shows how, given a query in the form of an image, this multi-modal Foundation Model can describe the provided image in very rich detail: perhaps even better than the average college student 😎!
- Input:

- Code:
import base64
import requests
import os
# OpenAI API Key
api_key = os.environ.get("MAGIC_API_KEY")
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Function to call endpoint
def gpt4v(image_path, api_key):
prompt = classification_prompt()
base64_image = encode_image(image_path)
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What's in this image?"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
"max_tokens": 300
}
response = requests.post("https://api.openai.com/v1/chat/completions",
headers=headers, json=payload)
print(response.json())- Output:
{'id': 'chatcmpl-68K9JOoOEvB', 'object': 'chat.completion', 'created': 1437, 'model': 'gpt-4-1106-vision-preview', 'usage': {'prompt_tokens': 1122, 'completion_tokens': 254, 'total_tokens': 1376}, 'choices': [{'message': {'role': 'assistant', 'content': 'This image captures a high-energy moment of equestrian barrel racing. The focus is on a horse and rider duo executing a tight turn around a barrel. The horse is a bay with a shiny coat, and its muscular build is on full display. It has its ears pinned back, showing concentration or the strain of the tight turn, and it wears a bridle with a bit and reins. The rider is leaning into the turn, showing good balance and control. They are wearing traditional western attire, including a cowboy hat, a plaid shirt, denim jeans, and cowboy boots. The rider\'s left leg is extended, only the toe touching the stirrup, as they guide the horse around the barrel.\n\nThe barrel is labeled "ALBERTA PREMIUM". The force of the turn is kicking up dirt and sand from the ground, creating a dynamic cloud of particles that accentuates the action. The background is slightly blurred, emphasizing the speed of the movement, and we can see fences and some banners or signs, suggesting that this is taking place in an arena during a competitive event.\n\nThe action is frozen in time by the photographer, giving the scene a dramatic and intense feeling, almost as if we can feel the ground vibrating from the horse\'s powerful strides.'}, 'finish_details': {'type': 'stop', 'stop': '<|fim_suffix|>'}, 'index': 0}]}- 🤖 GPT-4V: "This image captures a high-energy moment of equestrian barrel racing. The focus is on a horse and rider duo executing a tight turn around a barrel. The horse is a bay with a shiny coat, and its muscular build is on full display. It has its ears pinned back, showing concentration or the strain of the tight turn, and it wears a bridle with a bit and reins. The rider is leaning into the turn, showing good balance and control. …"
2. The promised land: CLIP + SAM + GPT-4V + [Whatever The Next Big Thing is]
2.1 The hype: computer vision is solved!
So, given that Foundation Models have taken the world by storm, the obvious question is now: Is Computer Vision finally solved?
One interesting way to answer this query is by looking at actionable answers! In other words: What are people out there creating with these new powerful building blocks? 🏗
This creative post details how to use GPT-4V in combination with other Foundation Models to detect objects. The main idea is that despite the limitations of GPT-4V to object detection, a two step process, where you first use one Foundation Model (e.g. Grounding DINO) to identify general objects, and then use GPT-4V to identify the exact objects you're looking for, lets you assemble an object detector.
2.2 The reality: A tool is not a system
Despite the promising breakthroughs brought by Foundation Models, stacking together a multitude of models to solve a problem at scale is quite different from building a demo.
To begin with, two of the fundamental costs associated with transforming a demo into a production-grade system are:
- 1) Development: A Foundation Model might work well in general but what about your specific task or use-case? In this scenario you might need to fine-tune your Foundation Model. For instance, what if you work with satellite images and need to fine-tune CLIP for this task? Assuming 4 months of development and 2 months of testing, a single ML Engineer's salary for this task might be around GBP 35,000. What if you need the job done in 3 months instead of 6 months? Will you be willing to pay the double of this amount?
- 2) Engineering: Connecting the inputs-outputs of "chained" Foundation Models to operate at high-speed and high-throughput requires your MLOps team to figure out a Foundation Model "connecting" pipeline. Foundation Models are great at zero-shot tasks, but assembling a line of models where the output of one stage can affect the input of the next stage is only one of the potential challenges to be addressed.
2.3 But Foundation Models are actually good enough!
This is absolutely true and exciting! Foundation Models are reshaping Computer Vision!
In the next two sections we describe the traditional Computer Vision pipeline, and the role we expect Foundation Models to play in a new generation of Computer Vision pipeline.
3. The traditional Computer Vision pipeline

Figure 4 shows the traditional Computer Vision pipeline from Data Collection to Model Monitoring. The illustration highlights the nature of each stage: Model-Centric, Data-Centric or Hardware.
In this current pipeline, the first three stages precede the main stage in a Model-Centric approach: Model Training. For many years, model-centric has been crucial to develop new architectures (e.g., ResNet, Transformers).
However, to build production grade ML systems, a Data-Centric approach has proven to be more effective. At least 6 of the 8 stages in this pipeline are Data-Centric in nature, meaning that they involve data at the core. For instance, Model Evaluation requires ML teams to identify the root causes of why a model is failing, so that it can be fixed before reaching the next stages. Also, Model Selection, often considered a Model-Centric stage, is, in reality, more closely tied to data: a profound understanding of how a model behaves varies with different slices of data.
We argue that, the rise of Foundation Models in Computer Vision might change the way this pipeline is being built though.
4. The new Computer Vision pipeline

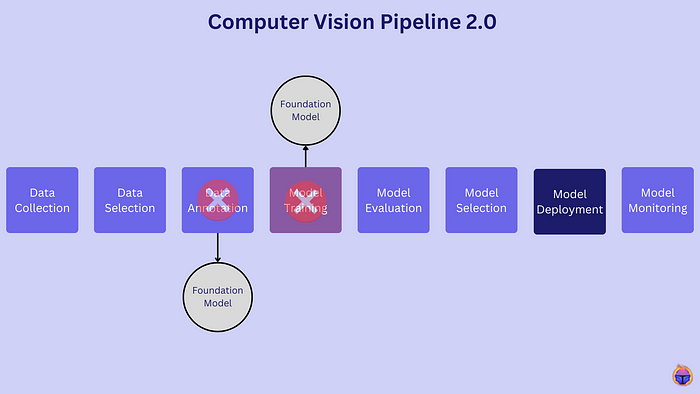
Figure 5 shows the way we envision the Computer Vision pipeline 2.0. As this diagram reveals, Foundation Models are likely to eliminate two of the stages of the traditional pipeline:
- Data Annotation: Annotating data at scale (i.e. 1M+ datasets) is perhaps the second most expensive process after model training. Controlling the quality of the labels is often the hardest challenge. Foundation Models could improve auto-labelling, and overtime take this stage out of the CV pipeline.
- Model Training: Once you have an annotated dataset, you can actually train a model. Nowadays, training a high-quality model for a specific use-case in industry is expensive. Large size datasets often require distributed training as the norm, if you aim to train a fine quality model. Hence, Foundation Models are well positioned to takeover this stage of the CV pipeline too.
As a result of these changes, all stages except deployment are likely to lean towards a data-first approach. Hence, data remains the key to building AI systems in the real-world.
5. Conclusion
In summary, the Computer Vision pipeline 2.0 presents a transformative shift led by Foundation Models.
Foundation Models hold the promise to streamline the cumbersome process of annotating large datasets and training high-quality models, reshaping the conventional pipeline.
These changes solidify the pivotal role of data in constructing effective AI systems for real-world applications.
References
[1] Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
[2] Emerging Properties in Self-Supervised Vision Transformers
[3] Foundational Models Defining a New Era in Vision: A Survey and Outlook
[4] GPT-4V(ision) System Card
[5] ImageNet Classification with Deep Convolutional Neural Networks
[6] Very Deep Convolutional Networks For Large-Scale Iimage Recognition
[7] Going deeper with convolutions
[8] Deep Residual Learning for Image Recognition
[9] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Authors: Jose Gabriel Islas Montero, Dmitry Kazhdan
If you would like to know more about Tenyks, sign up for a sandbox account.
