
Introduction to Activation Functions Activation functions in neural networks, including Convolutional Neural Networks (CNNs), play a crucial role in determining the output of a neural node and influencing the learning process. These functions introduce non-linearity to the model, enabling it to learn and model complex data, like images, video, and time-series data.
1. What Are Activation Functions?
Activation functions are mathematical functions applied to each neuron in the neural network to determine whether it should be "activated" (fired) based on its input. Without activation functions, neural networks would only perform linear transformations, which would limit their ability to learn complex patterns and relationships in data.
Activation functions introduce non-linearities, which are critical for solving non-trivial tasks such as image classification, object detection, and language translation.
2. Common Activation Functions in CNNs
2.1 Sigmoid Activation Function The sigmoid activation function maps input values to the range (0, 1), making it useful for binary classification problems.
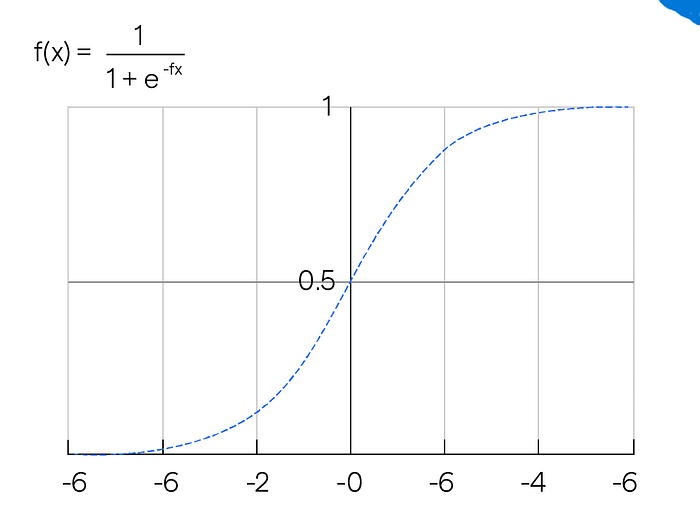
Properties: - Range: (0, 1) - Used for: Binary classification, especially in output layers for probabilistic interpretations. - Disadvantages: - Vanishing gradient: For very large or very small values of x, the gradient becomes almost zero, which makes it difficult for the model to learn. - Non-zero-centered output: Sigmoid can lead to inefficient weight updates.
2.2 Tanh (Hyperbolic Tangent) Activation Function The tanh function is similar to sigmoid but outputs values between (-1, 1).
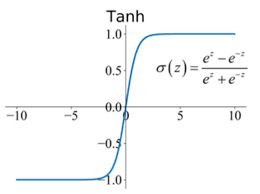
Properties: - Range: (-1, 1) - Used for : Classification tasks where we want the outputs to have negative values. - Advantages: - Zero-centered output: Unlike sigmoid, tanh outputs are centered around zero, leading to faster convergence. - Disadvantages: Still suffers from the vanishing gradient problem like sigmoid.
2.3 ReLU (Rectified Linear Unit) The ReLU function is one of the most commonly used activation functions in CNNs. It returns the input value directly if it's positive, and zero otherwise.
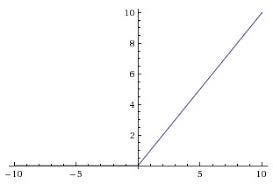
Properties: - Range: [0, ∞) - Used for: Most hidden layers in CNNs. - Advantages: - Computational efficiency: ReLU is computationally simple and efficient. - Non-saturating gradient: It avoids the vanishing gradient problem because its gradient is either 1 or 0. - Sparse activation: Many neurons are deactivated (output zero), which improves the computational efficiency of the network. - Disadvantages: - Dying ReLU problem: If many neurons output zero (especially for negative inputs), they can "die" during training and never activate again.
2.4 Leaky ReLU To address the dying ReLU problem, Leaky ReLU modifies the ReLU function by allowing a small, non-zero gradient for negative inputs.

Where alpha is a small constant, often set to 0.01.
Properties: - Range: (-∞, ∞) - Used for: Hidden layers in CNNs when dealing with dying ReLU issues. - Advantages: Reduces the problem of dead neurons. - Disadvantages: The small slope for negative values might still slow down training.
2.5 Parametric ReLU (PReLU) A more flexible version of Leaky ReLU, PReLU allows the slope of the negative part to be learned during training, instead of being fixed.
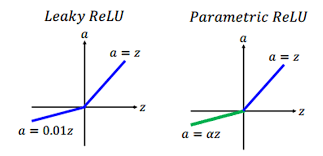
Properties: - Range: (-∞, ∞) - Used for: When you want the model to learn the slope of the negative region. - Advantages: Greater flexibility compared to Leaky ReLU, allowing the network to adapt the slope. - Disadvantages: More prone to overfitting due to the added learnable parameter.
2.6 Exponential Linear Unit (ELU) The ELU function improves upon ReLU by allowing negative values, which helps push the mean activations closer to zero, improving learning.
Properties: - Range: (-α, ∞) - Used for: CNNs with deep networks. - Advantages: ELU has a smoother curve for negative values, leading to faster convergence and better generalization. - Disadvantages: More computationally expensive than ReLU due to the exponential function.
2.7 Softmax Activation Function The Softmax function is primarily used in the output layer for multi-class classification problems. It converts raw output scores into probabilities.
Properties: - Range: [0, 1] - Used for: Multi-class classification (output layer). - Advantages: Provides a probability distribution over classes, which is useful for classification problems. - Disadvantages: Not suitable for hidden layers, as it's computationally expensive and sensitive to outliers.
— -
3. Activation Functions in CNN Layers
In CNNs, different activation functions are used for different layers. Here's a typical setup:
1. Convolutional Layers: ReLU (or its variants like Leaky ReLU, PReLU) is commonly used because it helps in extracting non-linear patterns from the input data while being computationally efficient. 2. Fully Connected Layers: ReLU or Leaky ReLU is used in most cases. However, in the output layer, we use sigmoid for binary classification and softmax for multi-class classification problems.
— -
4. Statistical Perspective: Bias-Variance Tradeoff
The choice of an activation function affects the bias-variance tradeoff in the model:
- ReLU and its variants (Leaky ReLU, PReLU) introduce low bias and high variance because they allow for piecewise linear decision boundaries. - Sigmoid and tanh introduce high bias and low variance due to their saturation at large positive/negative inputs.
Choosing the right activation function is crucial to balance model complexity and generalization ability: - ReLU is preferred for its simplicity and efficiency.