

Thanks for huge response to my previous write-ups. Recently I participated in a Bug Bounty program and I have found "Sub-domain takeover" issue by leveraging the Amazon S3 hosting service.
Even though you have an idea on the subdomain takeover via AWS S3. In this write-up, I will show the non-typical way of S3 subdomain takeover and also show the OSINT process to find the s3 regions and finally how I found the correct region of the target.
Introduction — Sub-Domain & S3
Subdomain: A Subdomain is a domain that the part of a larger domain. For example blog.example.com, www.example.com are subdomains of example.com

AWS S3: S3 is Simple Storage Service provided by the AWS cloud platform. In which they provide the cloud object storage and that offers industry-leading scalability, data availability, security, and performance.
Subdomain Takeover:
Subdomain takeover is a process of registering a non-existing domain name to gain control over another domain.
Actually before going to understand the subdomain takeover we have to discuss "DNS & CNAME" record. The main logic behind subdomain takeover is tangled with the actual subdomain CNAME record. CNAME records can be used to alias one name to another.
Let's illustrate the actual flow of subdomain takeover via S3:
- If you have subdomains of a target and you gathered the domain CNAMEs.
- Below Linux command gives the information of CNAME
- Let us assume that the one of the domain CNAME is pointing to the Amazon S3
dig cname assets.flawdomain.com 
While visiting the 'assets.flawdomain.com' gives the below response. Then you can easily takeover that subdomain by creating the bucket name with 'assets.flawdomain.com' in the 'US East (N. Virginia)' region.
I hope now all you understand the typical subdomain takeover process for the S3 pointed subdomains.
Let's discuss how I takeover the Subdomain in one of the bug bounty program.
In my reconnaissance process, I follow my step by step enumeration process. This process gives the focused targets result for the particular pattern.
Once I get all subdomains of a target then I ran the whatweb scan on all subdomains to fingerprint the domain information. Then instead of going to get CNAMEs data of all subdomains, first I filter the S3 pointed targets from the whatweb scan result based on the Server header.
you can export the whatweb scan output in a JSON file and easily grep the JSON file content using the gron tool
gron https_whatweb_scan.json|grep "AmazonS3" -A 8
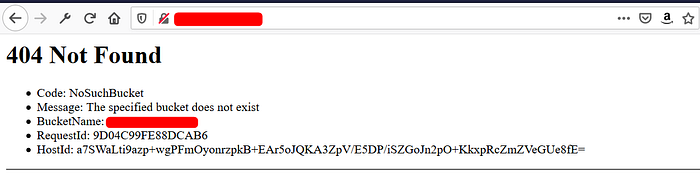
In all subdomains one of the subdomains have the "Server: AmazonS3" header in the response and it is being redirected to the "https://aws.amazon.com/s3/". And visiting by a random resource value gives the below errors. Please carefully observed the below images.
assets.flawdomain.com → redirecting to https://aws.amazon.com/s3/
https://assets.flawdomain.com/dasdsa/ → Permanent Redirect error
https://assets.flawdomain.com/teest1245678 → NosuchBucket error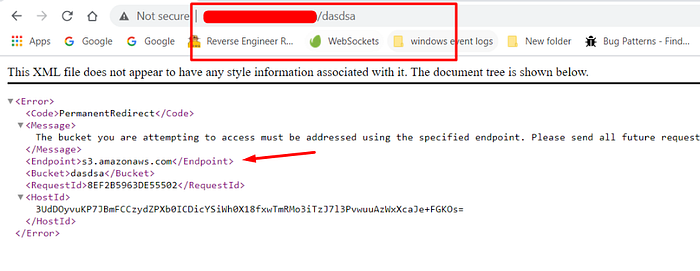
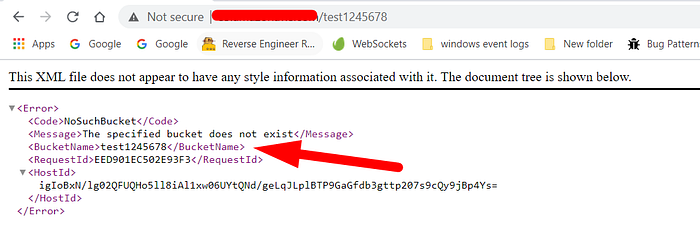
While I am learning about the S3 service I observe this similar redirection and the same response pattern with the domain "s3.amazonaws.com".
s3.amazonaws.com → redirecting to https://aws.amazon.com/s3/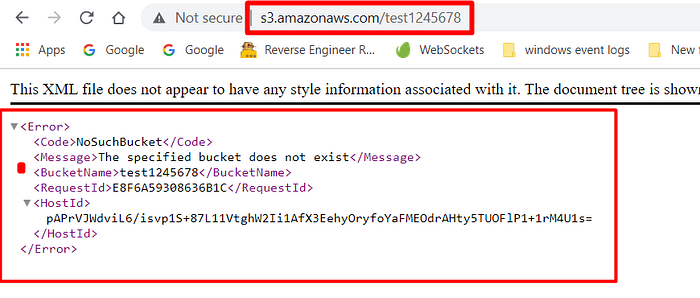
This is so suspicious.

The same behaviour is exhibited by the "assets.flawdomain.com". So at first, I thought the 'assests.flawdomain.com' act as 's3.amazonaws.com'. So, I created a bucket in the 'US East (N. Virginia)' region this region gives the 's3.amazonaws.com' domain name.
And I tried to access the created bucket with the 'assets.flawdomain.com'.
Finally, I got this below Permanent Redirection error

If I access with the actual s3 domain region domain it is working

Finally I realize, By reading the this issue on the github. I got to know this error cause if we accessing the bucket with wrong region.
Same error with other s3 region domain
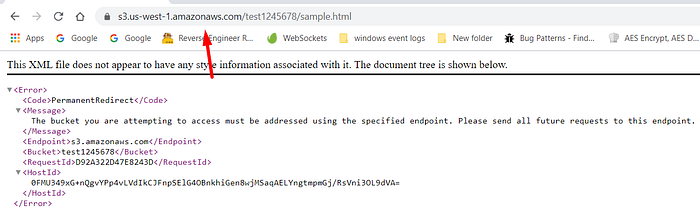
So here my challenge is we have to find the correct region.
How do I find the correct S3 region
As per the documentation, there are several s3 domains, based on the region of the Bucket. So it means the 'assets.flawdomain.com' acting as one of the below domain.
s3.amazonaws.com
s3-us-east-1.amazonaws.com s3-us-west-2.amazonaws.com s3-us-west-1.amazonaws.com s3-eu-west-1.amazonaws.com s3-eu-central-1.amazonaws.com s3-ap-southeast-1.amazonaws.com s3-ap-northeast-1.amazonaws.com s3-ap-southeast-2.amazonaws.com s3-ap-northeast-2.amazonaws.com s3-sa-east-1.amazonaws.com s3-cn-north-1.amazonaws.com s3-ap-south-1.amazonaws.comThis enumeration is so simple, I just gathered the public-facing s3 static domain URLs using the google dorks.
site:s3-us-east-1.amazonaws.com → this gives the specific region public facing bucket urls.Using the above technique I gather all possible regions public facing endpoints and checked with 'assets.flawdomain.com'


So Finally, I found the correct region. The 'assets.flawdomain.com' is acting as alias of 's3.ap-south-1.amazonaws.com'.
So finally, I created a bucket in the "Asia Pacific (Mumbai)" region and accessed with the 'assets.flawdomain.com'.
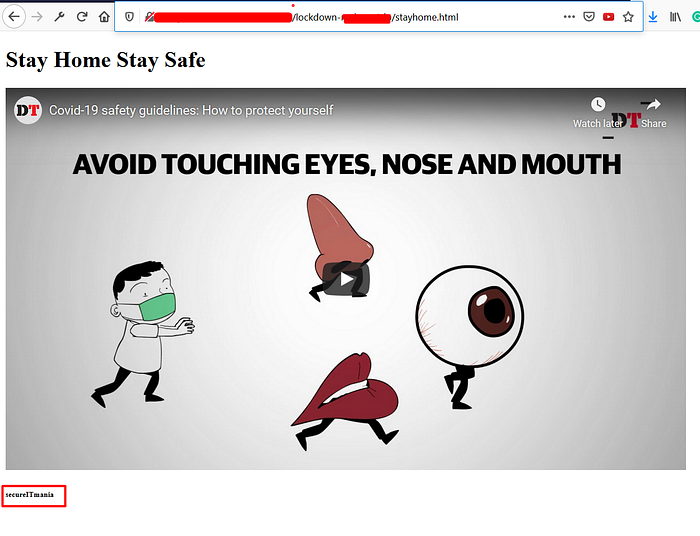
I hope this whole write-up gives an insightful knowledge of the recon process.
Conclusion:
Don't stick with known patterns and observe the behaviour of the result. if something goes weird results then analyze the result to explore the unknown patterns.
Thanks for reading. If you like this write-up please do follow me and stay tune for more hacking techniques.
Checkout my previous write-up that explain the technique to bypass the SOP using the URL parsers.
References: