

Explore best practices for CI/CD in Machine Learning in 2024. Learn to build, test, and deploy ML models efficiently with expert strategies.
By Grig Duta, Solutions Architect at Qwak
Building and deploying code to production environments is a fundamental aspect of software development. This process is equally pivotal in the realm of production-grade Machine Learning, where models undergo regular retraining with new data and are deployed for serving predictions.
In this article, we delve into actionable strategies for designing a robust CI/CD pipeline for Machine Learning. Our goal is to achieve near-complete automation, streamlining the process of retraining and redeploying models in production.
This guide is tailored to assist Data Scientists and ML Engineers in applying DevOps principles to their Machine Learning projects and systems.
Throughout this article, we'll generally refer to ML models as 'predictive,' acknowledging that while the landscape of machine learning now includes less about prediction and more about embedding, recognition and generative capabilities, the core principles of model deployment remain constant.
Understanding CI/CD Pipelines
In software development, a CI/CD (Continuous Integration / Continuous Deployment) pipeline is a sequential set of automated steps designed to facilitate the integration and delivery of incremental changes to a live application.
Typically triggered by a new commit to the version control system, CI/CD pipelines guide changes through various stages until they safely reach the production environment.
Between the initial code commit and the deployment to production, the code undergoes processes such as:
- unit testing, linting, vulnerability checks
- packaging into binaries or container images
- deployment to a staging environment for end-to-end testing.
Depending on the application type, these changes may also undergo manual testing (User Acceptance Testing or UAT) or be directly deployed to production as a canary release.
The Integration pipeline focuses on the initial stages of software delivery, encompassing tasks like building, testing, and packaging the application. On the other hand, the Deployment pipeline ensures the smooth deployment of new software packages in both testing and production environments.
This shift from traditional Ops teams to fully automated workflows in software development stems from the necessity to deliver smaller, incremental changes more frequently than the traditional approach of larger updates. The traditional method, with multiple manual steps performed by a release team, increased the likelihood of human errors affecting live systems.
CI/CD pipelines, and more recently, GitOps principles, have become standard procedures for DevOps teams. In the following sections, we will explore the distinctions between traditional CI/CD pipelines and those tailored for the Machine Learning lifecycle.
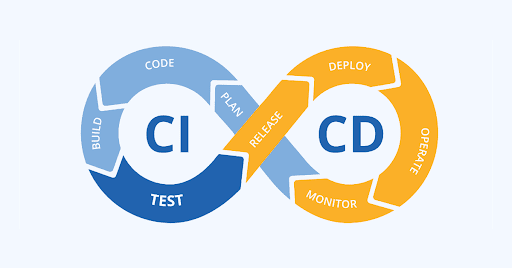
Why Use CI/CD for Machine Learning
I vividly recall a particular interview question: 'Why is it crucial to package a model into a container instead of just reloading the serialized model file in the existing deployment?' The answer to this question mirrors the essence of why automated pipelines play a pivotal role in the construction and deployment of machine learning models. The key lies in pursuing an 'immutable' process — one that seamlessly runs through the same steps from start to finish, devoid of any 'side effects' that could complicate the troubleshooting of model behavior changes, such as disparities in Python package versions between data scientists' laptops.
Continuous Integration / Continuous Delivery (CI/CD), originating from and gaining prominence in Software Development, is centered around the idea of regularly delivering incremental changes to a live application via an automated process of rebuilding, retesting, and redeploying.
Can this approach benefit Machine Learning models? Absolutely. Yet, the primary reason for automating these processes is the inherent susceptibility of Machine Learning models to degradation, necessitating regular (or at least occasional) retraining with new data and subsequent redeployment.
In contrast to traditional CI/CD pipelines for standard software applications, Machine Learning introduces two additional dimensions: Model and Data. While conventional software engineering practices revolve around code, ML involves extensive codebases alongside the management of substantial datasets and models to extract actionable insights.
Designing an ML system involves grappling with challenges like:
- Storing model artifacts and enabling teams to track experiments with their metadata for result comparability and reproducibility.
- Handling often large and rapidly changing datasets. In addition to monitoring model performance from an application standpoint, ML demands vigilance in tracking data changes and adjusting models accordingly.
ML systems demand consistent monitoring for performance and data drift. When model accuracy dips below a set baseline or data experiences concept drift, the entire system must undergo another cycle. This means replicating all steps, from data validation to model training and evaluation, testing, and deployment. This underscores why ML systems stand to gain significantly from automated pipelines, especially in the context of CI/CD.
In the upcoming sections, we'll delve into how CI/CD pipelines for Machine Learning deviate from traditional integration and delivery in software development.
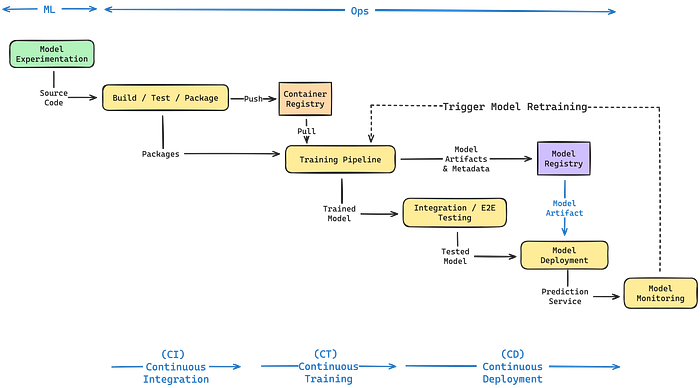
Exploring The Machine Learning Lifecycle
The Machine Learning (ML) lifecycle is a structured sequence of stages, critical for developing, deploying, and continuously improving ML models. This lifecycle is central to ensuring models remain effective and relevant in dynamic production environments.
- Model Development (Experimentation Phase)
Machine learning is fundamentally an exploratory field, diverging from traditional software development's linear paths. In this experimentation phase, data scientists and ML engineers engage in a creative process, prototyping and iterating over various models. They apply diverse techniques to explore data and algorithms, aiming to uncover the most effective solutions. While automation might not be central to this stage, the goal is clear: to identify and refine promising models for deployment, thereby enhancing the value delivered to end-users. This phase culminates with the selection of models ready to enter the ML CI/CD pipeline for further development and deployment.
2. Model Integration and Training (Build Phase)
Once a model is conceptualized, it enters the build phase. Here, new or updated code is tested and constructed into container images, which are then used for both training the model and serving predictions. The result is a trained model, stored in a Model Registry, and its associated container images housed in a container registry. This phase ensures that the model is not only trained with the latest data but is also packaged for efficient deployment and testing, marking a critical integration point in the lifecycle.
3. Model Deployment
The deployment phase sees the new model deployed in a production environment, serving either all traffic or a portion, contingent on the chosen release strategy. Best practices recommend employing separate environments like staging and production or implementing shadow (canary) deployments to receive duplicated live traffic without impacting users. The outcome is a production service for the model.
4. Monitoring and Retraining (Maintenance)
The final phase in the lifecycle is where the deployed model is closely monitored to assess its performance against predefined metrics and baselines. Monitoring helps identify when a model begins to drift or underperform due to changing data patterns or other factors. This phase is not the end but a trigger for a new cycle of improvement — initiating retraining, adjustments, or complete redevelopment as needed. It's here that the lifecycle truly embodies a continuous loop, with insights from monitoring feeding directly back into development and training, ensuring that models evolve and improve perpetually.
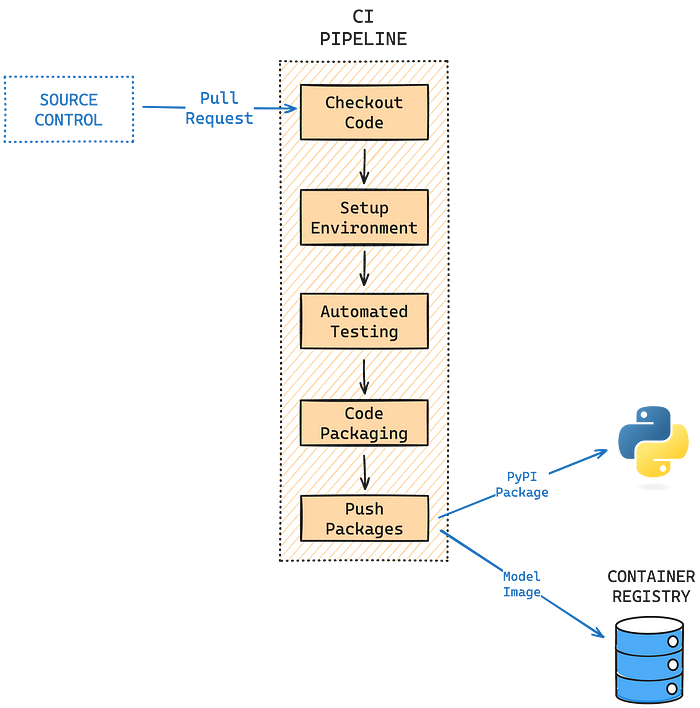
Continuous Integration (CI) in Machine Learning
In traditional software development, the activation of a Continuous Integration (CI) pipeline is an essential process triggered by the introduction of new code into a source control platform. This pipeline evaluates the code through various processes such as unit testing, linting, security vulnerability checks, and the assembly of a container image. Following this construction phase, the pipeline may proceed to local code execution or move towards deployment in a staging environment for comprehensive end-to-end testing. The culmination of this process is the publishing of the containerized code to a container registry.
In Machine Learning (ML) applications, while the CI process integrates many principles of traditional software CI, it also exhibits a distinct focus and scope. The primary goal in ML CI revolves around ensuring code quality and functionality, preparing the codebase for subsequent phases of the ML lifecycle.
The separation of model training and evaluation from the CI pipeline in ML is driven by several key reasons:
- Complexity and Resource Requirements: Model training often demands significant computational resources, including specialized hardware like GPUs. Integrating such resource-intensive tasks into the CI phase is impractical and could impede the efficiency of the code integration process.
- Separation of Concerns: By decoupling the model training phase from the integration process, there is greater flexibility in the development workflow. Training can be conducted independently with various parameters and evaluation methods. Simultaneously, CI can proceed unencumbered, enabling direct deployment of the model using pre-existing trained models without necessitating retraining during each integration cycle.
- Iterative Nature of ML Development: Model training in ML is inherently iterative, often involving experimentation with different parameters and methods. Including this iterative training within the CI workflow would significantly slow down the process, hindering the rapid iteration and integration that CI aims to achieve.
As a result of these considerations, the outcome of the CI phase in ML is a packaged model code, prepared and ready for deployment in either a prediction serving or a training environment. This separation ensures that the model is primed for training, evaluation, and eventual deployment, adhering to the unique requirements and workflows inherent in ML development.
Tools for Continuous Integration
For the purposes of this article, we've chosen to demonstrate the CI pipeline using GitHub Actions. This choice is informed by the platform's widespread adoption and its rich library of community-curated 'Actions', which greatly simplify the creation of CI workflows.
Why GitHub Actions?
- Integration with GitHub: As a GitHub-native solution, GitHub Actions offers the advantage of residing in the same ecosystem as your code. This integration eliminates the need for navigating between different platforms, streamlining the development process.
- Workflow Automation: GitHub Actions is a powerful tool for automating build, test, and deployment processes. It allows for the creation of workflows that automatically build and test each pull request, ensuring that changes are ready for deployment.
Alternatives: CircleCI and Jenkins
While GitHub Actions serves as our primary example, it's important to acknowledge alternatives like CircleCI and Jenkins. Both are capable of achieving similar outcomes:
- CircleCI: Known for its ease of use and quick setup, CircleCI is a strong contender, especially for teams looking for a straightforward, cloud-based CI solution.
- Jenkins: As an open-source platform, Jenkins offers a high degree of customization and control, making it a preferred choice for teams with complex, bespoke CI requirements.
CI Workflow for Machine Learning
Here's how a Continuous Integration workflow looks like in practical terms:
name: Machine Learning CI Pipeline
on:
workflow_dispatch:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
build-and-test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
name: Check out source code
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.X' # Adjust this to your project's Python version
- name: Install Python dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt # Or use another way to install dependencies
- name: Run tests
run: |
# Add your testing commands here, e.g., pytest for Python tests
pytest tests/
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Build Docker Image
run: |
docker build -t my-ml-model:latest . # Replace with your preferred image name
- name: Log in to Docker Registry
uses: docker/login-action@v3
with:
registry: # Replace with your Docker registry URL
username: ${{ secrets.DOCKER_USERNAME }}
password: ${{ secrets.DOCKER_PASSWORD }}
- name: Push Docker Image to Registry
run: |
docker push my-ml-model:latest # Replace with your image nameTriggering the Pipeline
Just like in traditional software development, Machine Learning (ML) code typically begins its journey in a version control system. A push or a pull request to the 'main' branch is the standard trigger that activates the Continuous Integration (CI) workflow. This event signals the start of the process, ensuring that any new code integrations are immediately tested and validated.
Setting up the Environment
The CI pipeline's initial task is to check out the code and establish a pristine environment for testing. Given that most ML applications heavily rely on Python, our example workflow prioritizes setting up the correct Python version and installing the necessary dependencies. While we've used requirements.txt for simplicity, alternative tools like Conda and Poetry are equally effective for managing dependencies, offering flexibility based on project needs.
Automated Testing
Automated testing typically encompasses code lints and unit tests. These tests are crucial for verifying that the model code functions as intended and does not disrupt existing features. It's important to distinguish this step from model performance testing — which is conducted post-training and involves model validation and evaluation. This distinction aims for different objectives: ensuring code integrity versus assessing model effectiveness.
Model Code Packaging
Python, being the predominant language for ML models and applications, presents two primary packaging options:
- PyPI Artifacts: Ideal for Python-centric applications, this method allows for easy distribution and usage of your code. Users can simply pip install your package in their environment. This approach is often favored by Data Science teams due to its ease of sharing and implementation.
- Container Images: These offer enhanced reproducibility and portability by encapsulating not just the Python code, but all the required dependencies for training and deploying the model. This method is particularly advantageous for deploying models across various cloud platforms or edge devices, and is thus more aligned with production environments.
It's worth noting that these packaging methods are not mutually exclusive. For instance, you could publish your Python code to a PyPI repository, enabling Data Science teams to utilize it in their experiments, while also packaging it into a container image for production deployment.
Deployment Preparation Finally, to facilitate the model's deployment for training or serving, this workflow pushes the container image to a container registry. This could be DockerHub, Amazon ECR, Google GCR, or another similar service. The choice of registry often depends on the deployment platform and organizational preferences.
Continuous Training (CT) in Machine Learning
Continuous Training (CT) is a pivotal component in the machine learning (ML) lifecycle, focusing on the ongoing process of training and retraining ML models. This process is essential in keeping models relevant and effective in the face of evolving data and changing environments.
What is Continuous Training?
Continuous Training refers to the systematic and automated retraining of ML models. Unlike a one-time training process, CT ensures that models adapt over time, learning from new data, and improving or maintaining their performance. It's particularly crucial for applications where data patterns change frequently, such as recommendation systems, fraud detection, and predictive maintenance.
Tools for Continuous Training
Continuous Training (CT) in machine learning can be facilitated using a variety of tools, ranging from self-managed solutions like Kubernetes with open-source tracking tools to fully managed platforms. Here's a detailed look at some of these options:
Self-Managed Solutions
Self-managed solutions offer flexibility and control, appealing to teams with specific infrastructure needs or those who prefer hands-on management of their ML workflows.
- Kubernetes with Kubeflow and Training Operator: Kubernetes provides the backbone for scalable and efficient container orchestration. When combined with Kubeflow, it creates a powerful environment tailored for ML workflows, allowing teams to run training jobs seamlessly on a multi-node cluster. The Training Operator in Kubeflow further simplifies the management of training jobs, supporting various ML frameworks. This setup is ideal for those who seek granular control over their infrastructure and ML processes.
Dedicated MLOps Platforms Adopting a dedicated ML training platform ensures that your training jobs are self-contained, automating several DevOps aspects and minimizing the need for direct intervention. These platforms offer unique advantages in simplifying and streamlining the training process:
- Amazon SageMaker: SageMaker offers an end-to-end managed environment that simplifies building, training, and deploying ML models.It allows you to run custom training jobs using your own container images while leveraging AWS's cloud infrastructure for scalability.
- Google Vertex AI: As a unified platform, Vertex AI integrates various Google Cloud ML services, making it easier to manage the ML lifecycle. Its strength lies in its seamless integration with other Google services and tools.
- Qwak: Specifically tailored for MLOps, Qwak enables you to train and build your model code into a deployable artifact, starting from either your local machine or a GitHub repository. Qwak's native support for GitHub Actions through custom actions further simplifies the process, making it highly accessible for continuous integration and deployment workflows.
Pipeline Triggers for Model Retraining
ML pipeline triggers can be automated to facilitate the retraining of models with new data based on different scenarios:
- Automated Trigger Post-CI: In many ML workflows, the training pipeline is automatically triggered once the CI pipeline successfully completes. This ensures that the model is trained on the most recent, validated code.
- Ad-hoc Manual Execution: For some projects, especially those with complex models or expensive training processes, triggering training manually is preferred. This allows data scientists to decide when to train the model, often after significant code changes or dataset updates.
- Scheduled Retraining: Training can be scheduled to occur at regular intervals (e.g., nightly, weekly) regardless of code changes. This is common in cases where models need to be updated frequently due to evolving data.
- Model Performance Degradation: When the model monitoring triggers an alert for prediction performance falling beneath a certain baseline, a webhook can be created to initiate retraining.
- Significant Changes in Data Distributions: Modern Feature Stores monitor data distributions for significant changes, indicating concept drift. You can set up alerts to retrain the model on fresh data when substantial shifts in feature distributions used for prediction are detected, suggesting the model has become outdated.
Continuous Training (CT) Workflow
Here's how a Training Pipeline looks like with Qwak and Github Actions:
name: Machine Learning Training Workflow
on:
# Trigger when the previous workflow (CI) has finished
workflow_run:
workflows: ["Machine Learning CI Pipeline"]
types:
- completed
# Trigger daily at 12 AM
schedule:
- cron: "0 0 * * *"
# Manual execution trigger
workflow_dispatch:
# Webhook trigger from a monitoring tool
monitoring_webhook:
types:
- webhook
jobs:
ml-training:
runs-on: ubuntu-latest
steps:
- name: Check out source code
uses: actions/checkout@v4
- name: Trigger Model Training
uses: qwak-ai/build-action@v1
with:
qwak-api-key: ${{ secrets.QWAK_API_KEY }}
model-id: ${{ vars.QWAK_MODEL_ID }} # Qwak Model ID
instance: 'gpu.t4.xl' # example with a GPU instance
tags: ${{ github.head_ref }} # tagging with the Github branch
from-file: '.config/build_conf.yml' # model config from YAML file
wait: false # shut down after triggering
# This step will execute ML training when triggeredIn our example, we simplify the process by focusing on a dedicated MLOps platform that facilitates custom model training.
Our workflow begins with checking out the code into the working directory. The reason for this step is that our chosen training platform handles the building of the container image. Unlike traditional methods where the user needs to build and push the container image, this platform requires just the model code, streamlining the process.
The training platform is being configured with a YAML file on which parameters to use for the model training, and uses GPU cloud infrastructure to leverage parallelized computations.
The training job is triggered with a custom GitHub Action, detailed here. It simply uploads your model code from the repository to a remote training platform, where the model is trained and automatically published to a model registry for later deployment.
Let's take AWS SageMaker as an alternate example. Here, you would need to set up AWS credentials before triggering the training job, then pass the container image that was built in the integration phase. Further details are available in this Medium article.
It's advisable to trigger the training job and then conclude the GitHub Actions workflow. Given that model training can be a lengthy process, sometimes extending over hours or days, it's impractical and costly to have the GitHub runner wait for its completion.
Let's visualize the outlined process with the following diagram:
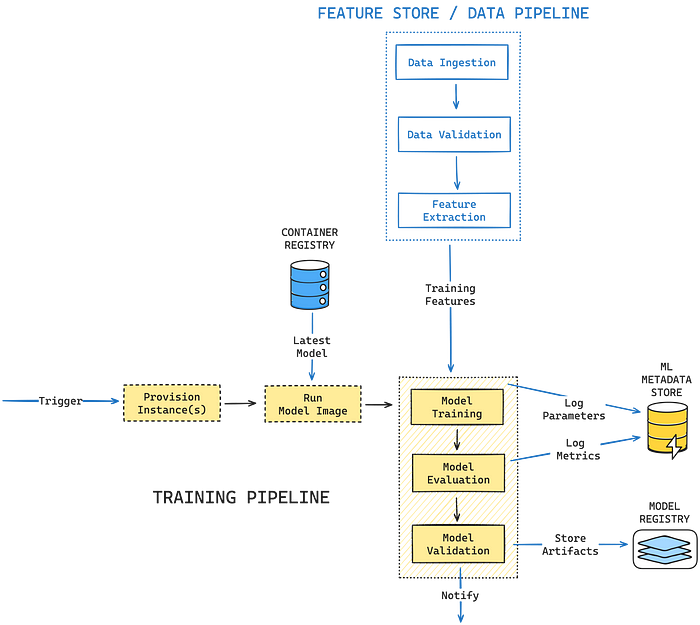
Additional Components
Data Pipeline / Feature Store
While data is a crucial ingredient for a successful model, we position it at the end of the ML lifecycle because it relates more to data preparation than the model itself. Model Development covers the process of extracting, validating, and transforming data into ML features, forming the foundation for designing the Data Pipeline or Feature Store.
Model Registry & Metadata Store
The additional components outlined in the previous diagram are accessed via model code, as many tools for storing features and trained models, along with their metrics, provide an SDK or REST API for interaction. Examples include DVC, Weights & Biases, MLflow, and others.
Most tools serving as Model Registries not only store trained models but also capture model metadata such as parameters, metrics, and various artifacts. Although a model registry may differ from a model experimentation platform in typical scenarios, for this use case, we consider them to converge in functionalities.
The next section will delve into how to seamlessly deploy your newly trained model to a staging environment and subsequently to production.
Continuous Deployment (CD) in Machine Learning
Continuous Deployment in ML is the process of automatically deploying ML models to production after they are trained and validated. This process ensures that the latest, most effective version of the model is always in use, thereby improving the overall efficiency and performance of the system.
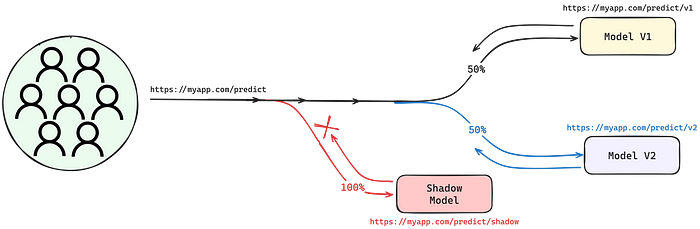
Staging or Shadow Deployment
In the MLOps pipeline, models are initially deployed to a staging or shadow environment. This environment is a close replica of the production setup, designed to mimic real-world conditions as closely as possible.
In a shadow deployment, the new model runs in parallel with the existing production model. However, it does not influence actual operational decisions or outputs. This setup allows for an observational assessment of the model under realistic conditions, without any risk to the current operations.
The key advantage here is the ability to validate the model in a safe, controlled environment that still provides valuable insights into how it would perform in production.
Monitoring and Evaluation
Once deployed in this preliminary environment, the model's performance is rigorously monitored. This involves tracking key metrics that are critical for the model's success. These metrics could include accuracy, latency, throughput, and specific business KPIs.
Monitoring in this phase is crucial to ensure that the model behaves as expected and meets the set standards before it impacts real users.
A/B Testing
A common approach in this stage is A/B testing, where decisions made by the new model are compared against those made by the current model. This comparison helps in evaluating whether the new model marks an improvement or shows regression.
A/B testing provides a data-driven approach to decision-making, ensuring that changes in model performance are not just observed but quantified.
Automated Deployment to Production
Upon successful validation in the preliminary environment, the model is automatically deployed to production when the Pull Request is being merged.
Deployment strategies, such as canary releases or blue-green deployments, can be used. These methods allow a gradual and controlled transition to the new model, minimizing risk.
To better visualize this process please see the following diagram:
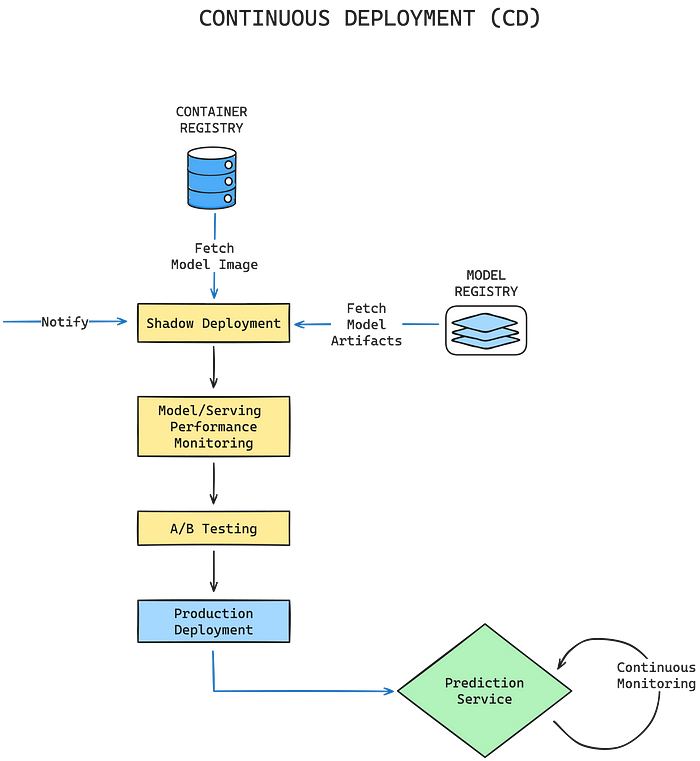
In this case, the workflow can be triggered by the successful closure of a pull request, indicating a successful merge to the main branch.
name: Deploy Model to Staging
on:
pull_request:
types: [closed]
workflow_dispatch: # Enables manual trigger
jobs:
deploy:
runs-on: ubuntu-latest
if: github.event.pull_request.merged == true
Steps:
# Deploy model to a shadow/canary endpoint
- name: Deploy Qwak Build
uses: qwak-ai/deploy-action@v1
with:
qwak-api-key: ${{ secrets.QWAK_API_KEY }}
deploy-type: 'realtime' # Deploying a real time endpoint
model-id: ${{ vars.QWAK_MODEL_ID }} # Qwak Model ID
build-id: ${{ github.head_ref }} # Using the branch name as build ID
param-list: |
variation-name=shadow,from-file=.config/deploy_conf.yamlIn the provided example, the workflow deploys to the Qwak platform, specifically targeting a shadow endpoint. The deployment's configuration is sourced from a configuration file stored within the repository. This configuration encompasses various settings, including the number of serving workers per replica, the total number of replicas (which corresponds to Kubernetes pods), variation settings, batching parameters for parallel processing, timeout settings, and more.
The choice to use Qwak's platform for this process is driven by its simplicity and ease of use, especially when compared to the complexities that might be involved in explaining a deployment using ArgoCD on a Kubernetes cluster.
The workflow is designed to be triggered in two scenarios: either manually at the user's discretion or automatically when a pull request is merged. It leverages a custom GitHub action that interfaces with Qwak, streamlining the deployment process and ensuring efficient and reliable model deployment to the shadow environment.
Continuous Monitoring in the MLOps Lifecycle
In discussing the automation of the MLOps pipeline, it's crucial to emphasize the significance of closing the loop with Continuous Monitoring. This essential phase ensures that the entire cycle, from integration and deployment to continuous training, isn't a one-off process but a dynamic, ongoing journey
Continuous Monitoring in the MLOps lifecycle, particularly following CI/CD/CT processes, is critical for maintaining and enhancing the performance of machine learning models in production. This phase ensures that models are not only deployed efficiently but also continue to operate effectively over time. Through continuous performance evaluation and drift detection, it enables timely responses to changes in data or model behavior. Importantly, it establishes a feedback loop, where insights from production directly inform and improve subsequent iterations of model development and training. This creates a dynamic cycle of continuous improvement, essential for the long-term success and relevance of ML models in real-world applications.
Conclusion
In conclusion, navigating the complexities of building and operating an integrated ML system in production represents the true challenge in machine learning. It extends beyond the initial model-building phase, considering the dynamic nature of datasets that organizations commonly encounter.
The journey involves designing effective CI/CD pipelines, accommodating not just code integration but also the intricacies of model training, deployment, and ongoing testing. Successfully orchestrating these workflows is crucial for maintaining model performance, addressing drift, and ensuring the reliability of predictions in real-world scenarios.
For a hands-on guide on implementing these workflows, explore the documentation in Qwak's CI/CD for Machine Learning section. It offers practical insights into setting up integrated model training, building and deployment using Github Actions.
Originally published in the Qwak Blog.