

You're staring at a default Apache landing page. No obvious links. No sitemap. No robots.txt. Yet your gut tells you there's more lurking beneath the surface.
This is where most security assessments hit their first roadblock. But not yours.
Content discovery isn't just about running automated scans. It's about understanding how web applications hide their secrets and knowing exactly which tools will crack them open. After years of digging through hidden directories and forgotten admin panels, I've learned that the right approach can turn a blank webpage into a goldmine of attack vectors.
Why Content Discovery Matters More Than You Think
Hidden content represents the largest attack surface most organizations don't even know exists. Every backup file, staging directory, and forgotten admin panel is a potential entry point.
The statistics are sobering. In my experience across hundreds of assessments, roughly 60% of critical findings stem from content that wasn't linked anywhere on the target site. We're talking about database backups with default credentials, development endpoints with debug information enabled, and administrative interfaces protected by nothing more than obscurity.
Here's what happens when you skip thorough content discovery:
You miss the low-hanging fruit. Administrative panels accessible via /admin/ or /wp-admin/ remain invisible without proper enumeration.
Backup files go unnoticed. Files like backup.sql, config.php.bak, or site.zip, often contain credentials or source code.
API endpoints stay hidden. Modern applications expose REST endpoints that aren't documented anywhere but contain sensitive functionality.
Development artifacts persist. Test files, staging directories, and debugging endpoints should have been removed before production.
Understanding Web Application Architecture
Before diving into tools, you need to understand what you're hunting for.
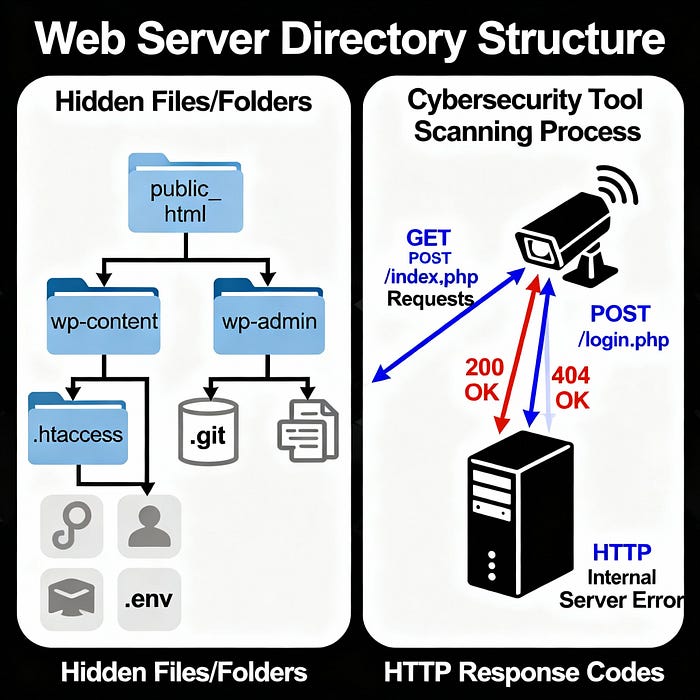
Web servers organize content in predictable patterns. Apache serves files /var/www/html/ by default. Nginx uses /var/www/. IIS prefers C:\inetpub\wwwroot\. Understanding these conventions helps you predict likely directory structures.
Modern applications follow frameworks with known patterns:
- Laravel applications expose
/storage/and/vendor/directories - WordPress sites have
/wp-content/,/wp-includes/, and/wp-admin/ - Drupal uses
/modules/,/themes/, and/sites/ - Django projects often have
/static/and/media/folders
Content management systems create predictable paths. Backup plugins generate files in /backups/ or /wp-content/uploads/. Database administrators create dumps in /db/ or /database/. Developers leave testing files in /test/ or /dev/.
File extensions reveal technology stacks. PHP applications use .php, .inc, and .php3. ASP.NET sites employ .aspx, .asmx, and .ashx. Understanding the target's technology helps you choose appropriate wordlists.
The Content Discovery Methodology
Effective content discovery follows a systematic approach. Start broad, then narrow your focus based on findings.
Phase 1: Passive Reconnaissance
Begin with zero direct interaction with the target. This phase gathers intelligence without alerting security systems.
Google Dorking reveals indexed content. Use site:target.com filetype:pdf to find documents. Try site:target.com inurl:admin to locate administrative areas. Search for site:target.com "index of" to find directory listings.
Wayback Machine analysis shows historical content. Use web.archive.org to see how the site evolved. Look for old paths that might still be accessible. Check for removed pages that could contain useful information.
Certificate Transparency logs expose subdomain structure. Tools like crt.sh reveal DNS names from SSL certificates. These often include development and staging environments with relaxed security.
robots.txt examination provides the first clue about hidden areas. While not authoritative, it often lists directories the site owner wants to keep private. Check /robots.txt and note any Disallow: entries.
Phase 2: Active Enumeration
Now you interact directly with the target using specialized tools.
Directory brute-forcing uses wordlists to guess common paths. Start with small, focused lists before expanding to comprehensive dictionaries. Monitor HTTP status codes carefully — 200 means success, 403 suggests protected content, 302 might indicate authentication redirects.
File extension fuzzing adapts to the discovered technology stack. If you find PHP files, test for .php.bak, .php~, and .php.orig. For Python applications, look for .py, .pyc, and .pyo files.
Recursive scanning dives deeper into discovered directories. When you find/admin/, scan /admin/* for additional content. Many tools support automatic recursion, but manual investigation often yields better results.
Parameter fuzzing tests for hidden functionality in discovered endpoints. Use tools like Arjun or Param Miner to find hidden parameters that might unlock additional features.
Tool Selection and Comparison
If you're finding this useful, please give it a few 'claps' and share it with your network! Your support helps this content reach more people.
Choosing the right tool depends on your specific requirements and target characteristics.

Gobuster: Speed and Simplicity
Gobuster excels at straightforward directory enumeration. Written in Go, it handles thousands of requests per second without breaking systems.
Strengths:
- Exceptional performance on large wordlists
- Clean, parseable output
- Minimal resource consumption
- Excellent for CI/CD integration
Best use cases:
- Initial broad scans with large wordlists
- Subdomain enumeration
- Virtual host discovery
- Automated pipeline integration
Sample command:
gobuster dir -u https://target.com -w /usr/share/wordlists/dirb/common.txt -x php,html,txt -o gobuster_results.txtFFUF: Flexibility and Power
FFUF (Fuzz Faster U Fool) brings unprecedented flexibility to content discovery. It handles complex fuzzing scenarios beyond simple directory enumeration.
Strengths:
- Multi-position fuzzing (directories, parameters, headers)
- Advanced filtering and matching options
- Recursive scanning capabilities
- Custom output formats
Best use cases:
- Complex fuzzing scenarios requiring multiple FUZZ positions
- Parameter discovery and testing
- Custom header fuzzing
- Advanced filtering requirements
Sample command:
ffuf -u https://target.com/FUZZ -w /usr/share/seclists/Discovery/Web-Content/raft-large-directories.txt -fc 404 -recursion -recursion-depth 2Dirb: Reliability and Tradition
Dirb represents the classic approach to directory enumeration. While slower than modern alternatives, it handles edge cases that sometimes trip up newer tools.
Strengths:
- Mature, battle-tested codebase
- Excellent handling of unusual server responses
- Built-in wordlists for common scenarios
- Reliable authentication handling
Best use cases:
- Legacy systems with unusual behaviors
- Thorough, methodical scanning
- Educational purposes and training
- Backup tool for verification
Sample command:
dirb https://target.com /usr/share/dirb/wordlists/big.txt -o dirb_results.txtDirsearch: Intelligence and Adaptation
Dirsearch brings intelligence to directory enumeration through smart filtering and adaptive scanning techniques.
Strengths:
- Smart filtering of false positives
- Automatic detection of server technologies
- Threading optimization for different targets
- Excellent progress indication
Best use cases:
- Targets with complex filtering or WAF protection
- Situations requiring careful rate limiting
- Mixed-technology environments
- Real-time monitoring during scans
Sample command:
python3 dirsearch.py -u https://target.com -e php,html,js -w /usr/share/seclists/Discovery/Web-Content/common.txt --random-agentAdvanced Techniques and Optimization
Beyond basic tool usage lies a world of advanced techniques that separate skilled practitioners from script kiddies.
Wordlist Intelligence
The wordlist makes or breaks your enumeration. Generic lists miss target-specific content. Technology-specific lists improve hit rates dramatically.
Start with reconnaissance-driven wordlists. If the target runs WordPress, prioritize WordPress-specific paths. Discovered PHP applications? Focus on PHP-related extensions and common PHP file structures.
Generate custom wordlists from target analysis. Extract keywords from the main site content. Company names, product terms, and employee names often appear in hidden directory structures. Tools like CeWL can automate this process.
Combine multiple wordlists strategically. Start with small, high-value lists for quick wins. Gradually expand to comprehensive dictionaries. Use tools like sort and uniq to merge lists without duplication.
Consider internationalization. Non-English targets might use localized directory names. Research common terms in the target's primary language.
Rate Limiting and Stealth
Aggressive scanning triggers defensive measures. Smart practitioners balance speed with stealth.
Implement request throttling. Most tools support rate limiting through -t or similar flags. Start conservatively with 10-20 threads and monitor target response times.
Randomize request patterns. Use random user agents and vary request timing. Tools like --random-agent in dirsearch or custom headers in ffuf help avoid detection.
Monitor for blocking indicators. Watch for consistent 429 (Too Many Requests), 503 (Service Unavailable), or sudden increases in response times. These suggest you've triggered rate limiting.
Distribute load across multiple source IPs. Large assessments benefit from rotating through multiple exit points. VPN services or proxy chains can distribute requests.
Response Analysis
Status codes tell only part of the story. Advanced practitioners analyze response content, timing, and patterns.
Size-based filtering eliminates false positives. Many applications return consistent content for non-existent paths. Filter responses by content length to focus on unique responses.
Time-based analysis reveals processing differences. Longer response times might indicate backend processing, database queries, or file system access. All signs of interesting functionality.
Content pattern matching identifies dynamic responses. Look for responses containing specific keywords, error messages, or structural patterns that indicate successful discovery.
Header analysis provides additional context. Server headers, cache-control directives, and custom headers often leak information about discovered content.
Practical Examples
Real-world content discovery requires adapting techniques to specific scenarios.
WAF Evasion and Advanced Bypassing
Web Application Firewalls (WAFs) increasingly protect modern applications. Successful content discovery must account for these defenses.
Detection Avoidance
Signature evasion uses encoding and obfuscation to bypass pattern-based detection. URL encoding (%2e%2e/), case variation (AdMiN), and alternative separators (admin;/) can slip past basic filters.
Request distribution spreads scanning across time and source addresses. Slow, distributed scans appear more like legitimate traffic than rapid-fire enumeration.
User agent rotation and header manipulation make requests appear to come from legitimate browsers rather than scanning tools.
Bypass Techniques
HTTP method variation tests different request methods for the same path. Some WAFs only filter GET requests, allowing HEAD or OPTIONS to reveal protected content.
Path manipulation exploits normalization differences between WAFs and backend servers. Double URL encoding, Unicode normalization variations, and path traversal sequences can bypass filters.
Content-Type fuzzing tests whether WAFs apply different rules based on request content types. XML, JSON, or form-data requests might receive different treatment.
Automation and Integration
Mature organizations integrate content discovery into continuous security testing pipelines.
CI/CD Integration
Automated baseline scans run during deployment pipelines to catch new exposures before production release. Tools like Gobuster integrate easily into GitHub Actions or Jenkins workflows.
Differential analysis compares current scans against previous baselines to identify newly exposed content. This approach focuses attention on changes rather than known, accepted exposures.
Reporting integration feeds discovered content into vulnerability management platforms or security dashboards for tracking and remediation.
Custom Script Development
API-driven enumeration leverages target-specific APIs for more intelligent discovery. Custom scripts can authenticate, parse responses, and follow application-specific logic.
Multi-tool orchestration combines different tools' strengths while compensating for individual weaknesses. Scripts can run multiple tools in parallel, correlate results, and provide unified reporting.
Dynamic wordlist generation creates target-specific wordlists based on discovered content, technology stack analysis, and organizational intelligence.
Responsible Disclosure and Ethics
Content discovery often reveals sensitive information. Handling discoveries responsibly protects both researchers and organizations.
Legal Considerations
Authorization verification ensures you have explicit permission before conducting any active scanning. Written authorization protects against legal liability.
Scope limitations respect defined boundaries around target systems, data types, and testing methods. Exceeding authorized scope can violate agreements and laws.
Data handling follows appropriate procedures for sensitive information discovered during testing. Avoid downloading, copying, or storing sensitive data beyond what's necessary for verification.
Best Practices
Minimal impact testing uses the least intrusive methods necessary to demonstrate findings. Proof of concept over exploitation.
Immediate reporting communicates critical findings to appropriate stakeholders as soon as possible. Don't delay reporting while continuing testing.
Professional communication documents findings clearly with appropriate technical detail while maintaining a professional tone and constructive recommendations.
The Road Ahead
Content discovery continues evolving alongside web application architecture and security practices.
API-first architectures shift focus from traditional directory structures toward endpoint discovery and GraphQL introspection.
Containerization and microservices create new patterns of hidden content in health checks, metrics endpoints, and service meshes.
Modern JavaScript frameworks implement client-side routing that obscures server-side structure, requiring discovery approaches.
Machine learning integration promises more intelligent wordlist generation and response analysis, potentially revolutionizing discovery effectiveness.
The fundamentals remain constant: understand your target, choose appropriate tools, analyze results intelligently, and act responsibly with discoveries.
Every hidden admin panel you discover, every forgotten backup file you uncover, and every exposed API endpoint you document make the internet a safer place. Keep digging. Keep learning. Keep protecting what matters.
Ready to put these techniques to work? Follow me for weekly insights into practical cybersecurity techniques that actually work in the real world. Your network's hidden secrets are waiting to be discovered.