


Search engines are massive public databases. Imagine knowing how to query them so you can extract the valuable signals that help you connect the dots — public documents, forgotten subdomains, leaked configurations — and identify the weak paths an attacker might try for initial access.
Think of search engines as public satellite imagery of the internet: from that view, you can spot open windows (public docs), construction sites (staging hosts), and delivery routes (service endpoints). If you can read the map, you'll see the back doors an attacker might use — or, better, see them first and close them. That's why defenders should own dorking: used responsibly, it provides visibility into what an adversary can find and allows you to fix issues before they do. Run short, timeboxed sweeps (30–45 minutes) against assets you control, validate findings non-invasively, and hand off an executive one-liner plus a technical appendix.
What is search-engine dorking
Search-engine dorking is more than "asking" — it's the disciplined use of advanced query syntax across public indexing services to extract proper signals at scale. You can run the same structured query across multiple public databases (web search engines, code hosts, service indexers) to gather a broad set of leads, or you can narrow the scope and compose precise queries when you need focused results. The skill is knowing how to shape questions and where to run them so you get usable signals, then correlating those signals into a coherent finding.
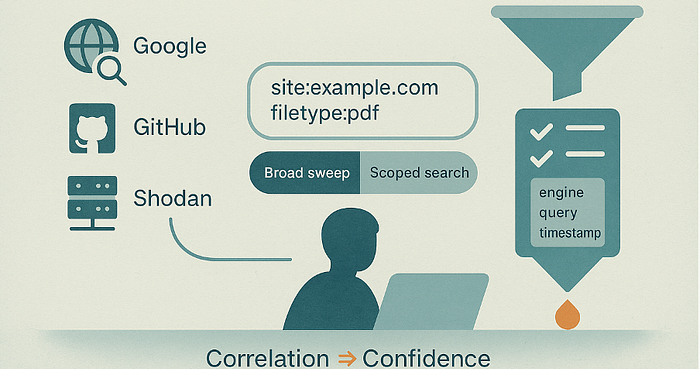
All-resources sweep (broad)
Run a small set of engine-appropriate queries across Google, Bing, GitHub, and Shodan to maximise coverage and surface unexpected assets. Use this when you're exploring or doing an initial discovery.
Example (broad):
Google: site:example.com filetype:pdf
GitHub: org:example filename:env
Shodan: hostname:example.com
Scoped search (narrow)
Tighten queries to a subdomain, path, or filetype, or add proximity/context operators when you need high-precision results. Use this when you're validating a hypothesis or reducing noise for a handoff.
Example (narrow):
Google: site:staging.example.com inurl:admin intitle: "index of"
GitHub: org:example path:deploy filename:prod.yml
Correlation is the multiplier
Matching results across engines (e.g., a host found in CT logs, a repository reference, and a Shodan banner) turns weak leads into high-confidence signals. Record provenance (engine, query, timestamp) for each hit so you can justify escalation.
Approach for search-engine dorking
Treat search-engine dorking as querying a system of libraries. Each public engine (Google, Bing, GitHub, Shodan) is a librarian that manages access to many sub-libraries — S3 buckets, blob storages, public repos, archived pages, paste sites, or specialized indexers. Some sub-libraries are well-known and apparent; others are small, niche collections that are only routinely indexed or used by particular communities. The real skill is knowing which librarian to ask and which shelf to point them at.
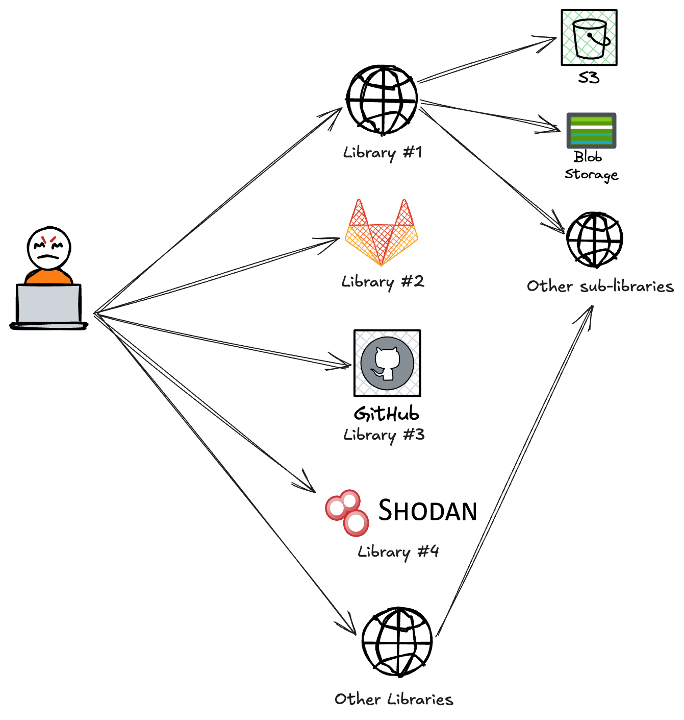
A concrete, recent example: people found ChatGPT conversations showing up in Google search results — not because someone "hacked" storage, but because those conversations had been shared publicly and were therefore indexable. In library terms, the artefacts lived on a public shelf that a crawler could read. The takeaway for defenders is the same: you don't always need to break in to find a problem — often you need to know which public shelf (shared exports, public pages, user-shared buckets) to check and what those items typically look like.
The crucial first step when you walk into a library is to know the book you want. If you can describe the artefact in plain terms — its type, likely filenames or tokens, and the service that might host it — you can translate that mental image into precise search pivots that filter noise and surface proper signals.
How to translate a mental image into queries (thinking, not a checklist)
Describe the book in one sentence. Type (document, spreadsheet, export), likely tokens in the filename or path, and probable host (docs subdomain, user content bucket, repo).
Extract search pivots. Convert your description into axes you can combine: site: (host/subdomain), filetype: (pdf/xls/zip), inurl: or path: tokens, and contextual words likely to appear near the artifact.
Pick the librarians. Choose engines that index the slices you care about: web search for pages/docs, code hosts for commits/files, and service indexers for banners/ports. Use at least two complementary engines to increase coverage.
Treat answers as leads, not proofs. A single result is a whisper. The same host appearing in a page, a repo, and a service index is a chorus — that correlation raises confidence and justifies action.
Practical exercise
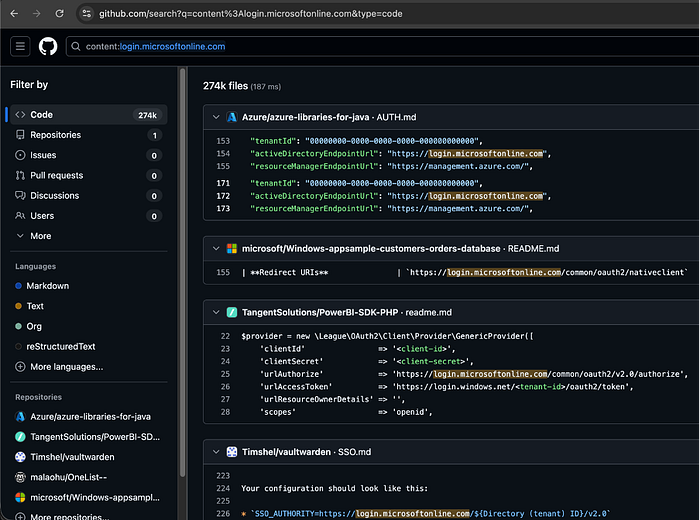
The screenshot reads like multiple librarians answering the same question: many public files on GitHub reference the token login.microsoftonline.com. That repetition isn't proof of a leak by itself — it's a pattern. Notice the artifact types (README, AUTH.md, code snippets) and the repo owners: documentation or official samples usually signal examples, whereas personal or unknown repos can indicate developer mistakes. In short, the token is a clue; the surrounding lines and ownership are what turn a clue into a finding.
These screenshots show a practical pattern I'd call "tenant ID trails." In plain terms, a tenant identifier that appears in an OpenID configuration or a config snippet is a clear indication of which directory or tenant an application communicates with. By itself, a tenant ID isn't a secret — it's an identifier — but it's a proper context for an attacker because it reduces uncertainty (which tenant to target) and, when combined with other signals (redirect URIs, client IDs, or leaked credentials), can speed escalation.


The screenshot shows many public S3-hosted pages surfaced for the token "password" — essentially one librarian (a web indexer) pointing to multiple sub-libraries (S3 buckets) that contain content mentioning that word. That repetition is a pattern: it tells you that "password"-related artifacts exist in publicly indexable storage, but it is not in itself proof of leaked credentials. The artifact type (PDF, help page, product doc), the path, and the owning domain are the context that converts a token into a meaningful signal.

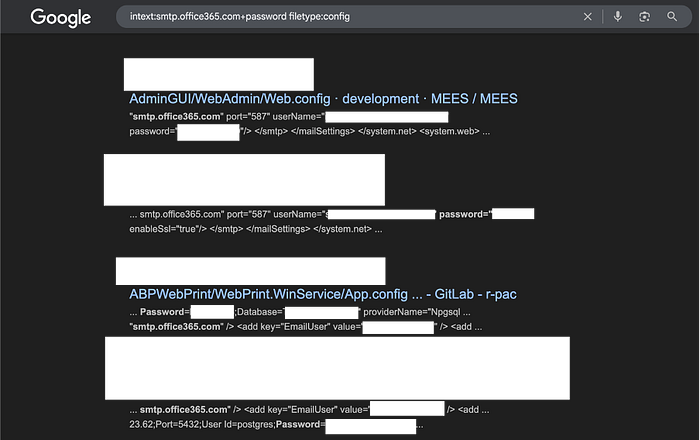
Narrow queries turn a noisy map into a focused slice of the stacks. In this screenshot, you're no longer seeing generic docs — you're seeing config artefacts (web.config / app.config style files) where the token smtp.office365.com sits next to password=. That pairing is an essential type of clue: the shape suggests that credentials or connection strings might be present, but the presence of the token alone isn't proof of a live secret (it could be a placeholder, a redacted value, or a sample configuration).
The ability to narrow your search is critical for effective search-engine dorking. You need to know your target: how it operates, which services and naming patterns it uses, and where artefacts are likely to land (pages, buckets, repos, service endpoints). Those mental cues enable you to refine broad sweeps into high-precision queries and transition from noisy hits to high-confidence leads. For an example of how to think about service naming and pivoting from endpoints to hosts, see my post "Service URLs — The Hidden Gateways in Your Attack Surface"
Conclusion
Search-engine dorking isn't a hobby — it's a visibility tool. Treat search engines as librarians and sub-libraries (buckets, repos, pages, service indexes): start with a clear idea of the "book" you want, translate that mental image into precise queries, and read results as leads that need provenance and correlation. A single hit is a whisper; the same token appearing across different librarians is the chorus that justifies action.
For defenders, the goal is simple: gain the same visibility that attackers use, so you can reduce surprise. This means teaching teams how artefacts are named and stored, scanning the public map for recurring patterns (not secrets), and converting confident signals into operational work — such as redaction, remediation, monitoring, or policy changes — through your normal secure disclosure and incident processes.