
Practical patterns — from simple presigned PUTs to edge-accelerated, resumable, and zero-trust flows — that keep uploads fast, safe, and cheap.
Nine production-ready file upload designs using S3, Cloudflare R2, and signed URLs. Learn when to use presigned PUT/POST, multipart, resumable, edge, and zero-trust pipelines.
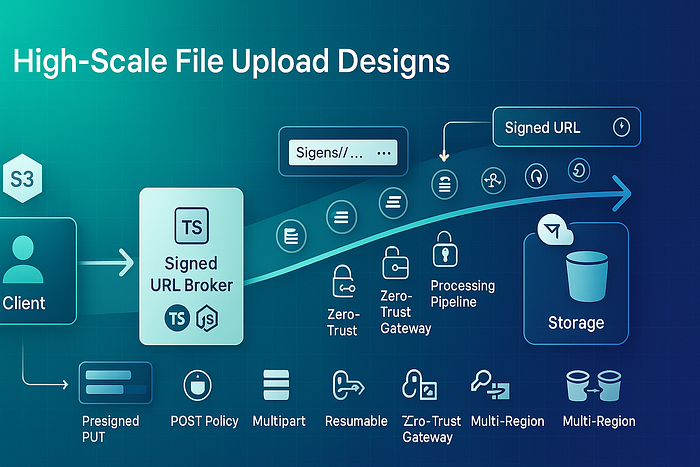
You ship a file upload. It works on your Wi-Fi. Then a customer in another region tries a 2 GB video on mobile, and suddenly your server falls over or the browser hangs at 92%. Let's be real: uploads are a networking problem wrapped in product expectations. Below are nine designs I keep reaching for in 2025 — each tuned for scale, predictability, and cost.
1) Direct-to-Bucket with Presigned PUT (the baseline)
Use when: Small/medium objects (<100 MB), simple paths, minimal moving parts.
Idea: Your API signs the operation; the browser uploads directly to S3/R2. Your servers never proxy bytes.
// Node/Express: presign S3 PUT (AWS SDK v3)
import { S3Client, PutObjectCommand } from "@aws-sdk/client-s3";
import { getSignedUrl } from "@aws-sdk/s3-request-presigner";
const s3 = new S3Client({ region: "us-east-1" });
app.post("/sign", async (req, res) => {
const { key, type } = req.body;
const url = await getSignedUrl(
s3,
new PutObjectCommand({ Bucket: process.env.BUCKET, Key: key, ContentType: type }),
{ expiresIn: 60 }
);
res.json({ url });
});Why it scales: Your compute stays almost idle; storage handles the heavy lifting. Add object-level lifecycle rules and request payer tags to keep costs tidy.
2) Presigned POST with enforced metadata
Use when: You need strict server-side validation of fields (size, type) without custom middleware.
Idea: Generate a form with constraints baked into the signature. The browser submits straight to the bucket.
// S3 POST policy fields (TypeScript)
const policy = {
expiration: new Date(Date.now() + 60_000).toISOString(),
conditions: [
{ bucket: process.env.BUCKET },
["starts-with", "$Content-Type", "image/"],
["content-length-range", 0, 10_000_000],
["starts-with", "$key", "uploads/"]
]
};
// Sign the policy; return url + fields to the clientWhy it scales: Validation happens at the storage edge; you get fewer garbage writes.
3) Multipart Upload for large files (S3 & R2)
Use when: Files >100 MB, unreliable networks, or you need parallelism.
Idea: Split the object into parts; upload in parallel; complete the upload with a manifest of ETags.
// Browser: parallel multipart with S3 presigned URLs (pseudo)
const { uploadId, partUrls } = await fetch("/init-multipart?key=video.mp4").then(r => r.json());
const etags = await Promise.all(partUrls.map((u, i) => fetch(u, { method:"PUT", body: chunk(i) })
.then(r => ({ ETag: r.headers.get("ETag"), PartNumber: i+1 }))));
await fetch("/complete-multipart", { method:"POST", body: JSON.stringify({ uploadId, etags }) });Why it scales: Retries are cheap (re-send a part), throughput is high, and memory use stays reasonable. On R2, pair with Workers for edge-close control.
4) Resumable Uploads (TUS or your own part ledger)
Use when: Mobile networks, flaky Wi-Fi, uploads that must survive tab or process crashes.
Idea: Keep a small server-side ledger (key → uploaded parts/offset). The client resumes from the last good offset instead of starting over.
Implementation sketch: Use a KV/Redis to track {key, uploadId, nextPart}. Expose /resume to query progress. The browser probes, then continues at nextPart. UX feels magically robust.
5) Edge-Accelerated Ingest (R2 + Workers, or S3 + CloudFront)
Use when: Your users are far from your origin, or p95 is dominated by distance.
Idea: Move the first hop closer to the user. For R2, terminate at a Worker in the user's region and stream to the bucket. For S3, terminate via CloudFront or an EC2 ALB close to the user.
// Cloudflare Worker: receive chunks, pipe to R2
export default {
async fetch(req, env) {
const key = new URL(req.url).searchParams.get("key");
const obj = await env.R2_BUCKET.put(key, req.body, { httpMetadata: { contentType: req.headers.get("content-type") }});
return new Response(JSON.stringify({ ok: true, size: obj.size }), { headers: { "content-type":"application/json" }});
}
}Why it scales: Shorter RTTs, fewer mid-path failures, and lower variance at the 95th–99th percentiles.
6) Zero-Trust Upload Gateway (signed URL broker)
Use when: You must never expose bucket write permissions directly, or you want per-user, per-file scoping.
Idea: Your gateway issues one-time, short-lived signed URLs scoped to {userId, key, size, mime}. Every URL is auditable, ephemeral, and minimal in scope.
Security notes:
- Include a server-issued
x-amz-meta-userid/custom metadata for traceability. - Enforce tight expirations (≤60s).
- Rate-limit the broker per account.
7) Post-Write Processing Pipeline (antivirus, thumbnails, transcodes)
Use when: You need to "bless" an object before it becomes public or searchable.
Idea: Upload to a quarantine prefix. Emit an event (S3 Event / R2 Object Created). A processing worker scans/transcodes and moves the final object to a public prefix with immutable cache headers.
Operational tips:
- Treat the move (or copy+delete) as the publish step.
- Attach a status document in DynamoDB/Firestore so the app can display "Processing…".
8) Customer-Owned Encryption & Compliance (SSE-KMS, legal holds)
Use when: Regulated data, deletion windows, or BYOK.
Idea: Use S3 SSE-KMS with per-tenant keys; on R2, use encryption at rest plus application-level envelope encryption when needed. Keep object tags for retention, legal hold, and data residency.
Why it scales: Crypto is delegated to managed services; you enforce policy with tags and IAM boundaries instead of custom code.
9) Cost-Aware Multi-Region Strategy (hot/cold + replication)
Use when: You need durability and fast reads across continents — without doubling your bill.
Idea:
- Ingest to the user's nearest region (edge or region).
- Replicate asynchronously to a cheaper cold region for durability and batch processing.
- Serve downloads from the closest edge cache; keep origin egress minimal.
Pragmatic knobs: Lifecycle rules for big videos, intelligent tiering, and request-payer buckets for internal pipelines.
Practical guardrails (that save weeks later)
- Chunk size: 5–64 MB works well for multipart; larger parts reduce overhead but raise retry cost.
- Key design: Use deterministic keys:
tenantId/yyyy/mm/dd/uuid.ext. Prevents hot partitions and eases cleanup. - Content validation: Don't trust
Content-Typefrom the client—sniff server-side in the processor stage. - Idempotency: Add an
uploadTokenoridemkey when initializing; safe retries reduce support tickets. - Observability: Log
key, userId, size, region, p95, retries. Uploads are "write once, debug forever" unless you keep the breadcrumbs.
Tiny end-to-end example (presigned multipart, TypeScript)
Server (init & complete):
// Pseudo: AWS SDK v3
import { S3Client, CreateMultipartUploadCommand, CompleteMultipartUploadCommand } from "@aws-sdk/client-s3";
const s3 = new S3Client({ region: "us-east-1" });
export async function initMultipart(key: string, contentType: string) {
const { UploadId } = await s3.send(new CreateMultipartUploadCommand({
Bucket: process.env.BUCKET, Key: key, ContentType: contentType
}));
// Generate presigned URLs for parts 1..N in a separate step to control concurrency
return { uploadId: UploadId };
}
export async function completeMultipart(key: string, uploadId: string, parts: { ETag:string, PartNumber:number }[]) {
await s3.send(new CompleteMultipartUploadCommand({
Bucket: process.env.BUCKET, Key: key, UploadId: uploadId,
MultipartUpload: { Parts: parts.sort((a,b)=>a.PartNumber-b.PartNumber) }
}));
}Client (resumable notion):
// Browser (simplified)
const CHUNK = 8 * 1024 * 1024;
async function sendFile(file: File) {
const { uploadId } = await post("/init", { key: file.name, type: file.type });
let part = 1, offset = 0, etags: any[] = [];
while (offset < file.size) {
const slice = file.slice(offset, offset + CHUNK);
const url = await post("/sign-part", { key: file.name, uploadId, part }); // short-lived
const resp = await fetch(url, { method: "PUT", body: slice });
etags.push({ PartNumber: part, ETag: resp.headers.get("ETag")! });
offset += CHUNK; part++;
}
await post("/complete", { key: file.name, uploadId, etags });
}Why this combo performs: Direct-to-bucket removes server bottlenecks; multipart enables retries; short-lived signed URLs maintain zero-trust; you can add edge termination later without changing the contract.
Choosing the right design (quick map)
- Under 100 MB, simple rules: Presigned PUT.
- Strict browser-side validation: POST policy.
- >100 MB, unreliable networks: Multipart with resume.
- Global audience: Edge-accelerated ingest.
- Sensitive data: Zero-trust gateway + KMS.
- Processing required: Quarantine → pipeline → publish.
- Cost pressure: Tiering + async replication; keep egress at the edge.
You might be wondering, "Can I mix them?" Absolutely. Many teams run presigned PUT for small stuff, multipart for the big hitters, and route VIPs to edge ingest.
Conclusion
Uploads aren't a one-size feature; they're a portfolio. Start with direct-to-bucket presigned PUTs, graduate to multipart + resume for large files, and pull in edge and zero-trust as your audience grows. Keep the contract stable (signed URLs + metadata), and you can swap in new infrastructure without breaking client code.
CTA: What's your biggest upload pain — mobile resumes, p95 variance, or virus scanning? Drop a comment and I'll share a focused recipe for your stack.