

Enabling AIs to understand enterprise data is one of the most consequential next steps of the AI revolution. Already, large language models (LLMs) enable stunningly rich conversations spanning vast unstructured datasets. These models however, cannot easily understand enterprise data, which is typically structured into databases. In principle, we could bridge these worlds by transforming natural language prompts into the language of databases, SQL. However, this text-to-SQL problem is incredibly difficult, requiring a deep understanding of the intricate data schema used by complex enterprises. With over 4 billion queries running on the Snowflake platform every day [1], we have unparalleled insight into this challenge and the value this can create for our customers.
Here we present an exciting development. We have combined a fine-tuned Snowflake SQL generation model and Mistral's new state of the art Mistral Large model to create a new text-to-SQL engine for Snowflake Copilot. This new setup is on the frontier for complex real-world SQL generation tasks.
Text-to-SQL is highly complex
The journey to this point has been filled with challenges. Real-world customer data can span trillions of rows [1] across a huge number of tables and columns. Writing SQL queries for such data demands a nuanced understanding of not just the database schema but also the intent behind each query. It's about more than correctly parsing natural language; it's about inferring the right set of operations that reflect the user's goals, which can be highly contextual and complex.
For example the widely-used Spider dataset (and its variants) represents only a fraction of the diversity and complexity found in real-world scenarios. We demonstrated this by fine-tuning Meta's Code Llama, and nearly matching GPT-4 on this dataset, but realized that this model could not understand real-world customer data. The real test comes not from these curated datasets but from the unpredictable and varied demands of real-world use cases. This insight forced us to create our own text-to-SQL evaluation datasets that better capture the complex datasets maintained by Snowflake.
Furthermore, SQL queries are subtle and ambiguous, and the "correct answer" is often a subtle question of style. Therefore, we have also created a new LLM-as-judge evaluation metric for text-to-SQL, called Evaluation Score. Unlike traditional Execution Accuracy, which struggles with stylistic nuances and the fuzzy matching of outputs, Execution Score does not require access to underlying datasets and complements Execution Accuracy to provide a fuller evaluation of text-to-SQL performance.
The greatest challenge, perhaps, is "understanding the data." Fully solving text-to-SQL means that the language model must understand how and why this data was collected, including intricacies like when and why some data may be missing or incorrect. We have therefore also invested heavily in understanding the amount of metadata to inject in our text-to-SQL models.
The new frontier in text-to-SQL
Given all this infrastructure — new training datasets, new evaluation metrics, and the ability to inject relevant metadata into our prompts — we can then get to the heart of the matter: developing models to solve text-to-SQL. Impressively but unsurprisingly, GPT-4 is the state of the art (SoTA) today, achieving 46.0% on our core Evaluation Accuracy metric. Other models, including from the Code Llama family, have shown promise but did not surpass 36.6% without SQL specific fine-tuning. With fine-tuning, we were able to achieve 40.6%, which is still below the SoTA and doesn't meet our customer needs.
The recent introduction of Mistral Large, the latest LLM from Mistral, marks a significant milestone in this journey. Even in a zero-shot, no fine-tuning scenario, it achieves an impressive 39.1% on Evaluation Accuracy. Furthermore, as part of our partnership with Mistral, we are incredibly excited to offer Mistral Large in Snowflake Cortex, Snowflake's fully managed LLM and vector search service that enables organizations to quickly build AI apps securely with their enterprise data.
However, this is still not exceeding zero-shot GPT-4 performance. That's when we had an insight: could we combine the powers of our fine-tuned Snowflake SQL generation model with Mistral Large in our text-to-SQL engine? The former is well trained on the intricacies of Snowflake SQL and generally makes good initial guesses. The latter offers greater conversational abilities (another important dimension we will discuss in a future article) and can "check" the output of our codegen models. What's more, Mistral Large has great tool-use capabilities, allowing our Snowflake SQL generation model to be used as a tool.
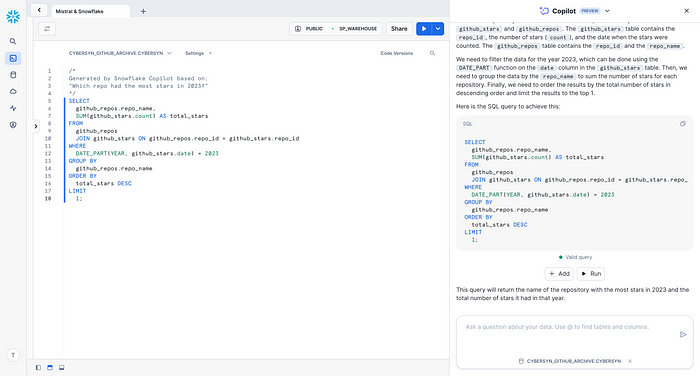
To bring this to life, see the following example of a question a user may ask to our Copilot, and what the responses of the Snowflake SQL generation and combined model are. In this example we're using Cybersyn's GitHub Archive dataset from Snowflake Marketplace.
User Question:
What was the month-to-month growth of stars for each repo in Q1 2024?
Snowflake SQL:
WITH monthly_stars AS (
SELECT
github_stars.repo_id,
DATE_TRUNC('MONTH', github_stars.date) AS month,
SUM(github_stars.count) AS total_stars
FROM
github_stars
WHERE
DATE_PART(YEAR, github_stars.date) = 2024
AND DATE_PART(QUARTER, github_stars.date) = 1
GROUP BY
github_stars.repo_id,
month
)
SELECT
monthly_stars.repo_id,
monthly_stars.month,
monthly_stars.total_stars,
(
monthly_stars.total_stars - LAG(monthly_stars.total_stars) OVER (
PARTITION BY monthly_stars.repo_id
ORDER BY
monthly_stars.month
)
) AS month_to_month_growth
FROM
monthly_stars
ORDER BY
monthly_stars.repo_id,
monthly_stars.month;Snowflake SQL + Mistral Large:
To answer your question, we need to calculate the month-to-month growth of stars for each repo separately in Q1 2024. We can achieve this by using the
github_starstable, which contains therepo_id,count, anddatecolumns. We will use therepo_idcolumn to identify each repository, thecountcolumn to determine the number of stars, and thedatecolumn to filter the data for Q1 2024 and group it by month.
First, we will create a CTE (Common Table Expression) to aggregate the star counts for each repository per month in Q1 2024. We will use the
DATE_TRUNCfunction to group the data by month and theSUMfunction to calculate the total stars for each repository in that month. We will filter the data using theWHEREclause to only include data from Q1 2024.
Next, we will calculate the month-to-month growth by using the
LAGwindow function. This function allows us to access data from a previous row within the same result set. In this case, we will use it to access the total stars from the previous month for each repository. We will then subtract the previous month's total stars from the current month's total stars to calculate the growth.
Here's the final SQL query:
WITH monthly_stars AS (
SELECT
github_stars.repo_id,
DATE_TRUNC('MONTH', github_stars.date) AS month,
SUM(github_stars.count) AS total_stars
FROM
github_stars
WHERE
DATE_PART(YEAR, github_stars.date) = 2024
AND DATE_PART(QUARTER, github_stars.date) = 1
GROUP BY
github_stars.repo_id,
month
)
SELECT
monthly_stars.repo_id,
monthly_stars.month,
monthly_stars.total_stars,
(
monthly_stars.total_stars - LAG(monthly_stars.total_stars) OVER (
PARTITION BY monthly_stars.repo_id
ORDER BY
monthly_stars.month
)
) AS month_to_month_growth
FROM
monthly_stars
ORDER BY
monthly_stars.repo_id,
monthly_stars.month;This query will provide the month-to-month growth of stars for each repository separately in Q1 2024.
Delightfully, this combined architecture is greater than the sum of its parts, achieving 46.4% on Evaluation Accuracy. Qualitatively, we find that it gives customers a satisfyingly accurate and conversational experience writing SQL queries using natural language in our Copilot product. Here are the results compared to the other models we've evaluated:
- CodeLlama 34B Instruct: 30.8%
- Phind 34B Instruct: 36.6%
- Mistral Large: 39.1%
- Snowflake SQL: 40.6%
- GPT-4: 46.0%
- Snowflake SQL + Mistral Large: 46.4%
Conclusion
We are incredibly excited about how Mistral Large is set to redefine the capabilities of Snowflake Copilot and similar SQL copilot products in the industry. In particular, combining Mistral Large with our own proprietary, dedicated Snowflake SQL generation model, we are able to deliver leading text-to-SQL performance. Notably we are using our internal benchmark for this, which is significantly harder than open source benchmarks, and better captures the real-world complexity of enterprise data.
However, this is just the beginning. One future step will be enabling our text-to-SQL models to be composed into even bigger, more powerful data pipelines and richer conversational interfaces. The larger dream is to enable enterprises to leverage generative AI to achieve true AI-based cognition over all of their data. In the rapidly evolving field of AI, Snowflake has led the charge in leveraging cutting-edge technologies to deliver text-to-SQL capabilities to our customers.
Further reading
This blog builds on insights shared in our previous blog posts:
- Part 1 explains why Spider and other open-source text-to-SQL datasets are insufficient to solve real-world data understanding problems.
- Part 2 introduces a new LLM-as-judge evaluation metric for text-to-SQL, called Evaluation Score, and shows why our new metric complements and overcomes limitations of the widely used Execution Accuracy score.
- Part 3 explores the challenge of integrating customer metadata into a text-to-SQL engine at prompt time.
- Part 4 describes the training infrastructure we use at Snowflake to perform large-scale LLM training.
References
[1] Based on internal Snowflake data between January 1, 2024 and January 31, 2024, we handle 4.2 billion queries a day on customer datasets that sometimes exceed 50 trillion rows