

In this experiment I am trying out 5 RAG methods open-sourced by LlamaIndex. They profess that they have reduced the RAG activity to ~1 line of code. So let us test that. Also we are going to compare among them to see which one gets the most accurate result.
TL; DR: Auto Merging Retriever Pack and Small-to-big Retrieval Pack provided by LlamaIndex perform the best for this experiment. Read on to see what went down.
Note: We are using OpenAI APIs for this language generation part. The code is available as a google colab notebook.
Installing the libraries
pip install llama-index llama-hub rank-bm25
pip install pypdfStep 2: Loading the data
import nest_asyncio
nest_asyncio.apply()
from llama_index import SimpleDirectoryReader
from llama_index.node_parser import SimpleNodeParser
import os
os.environ["OPENAI_API_KEY"] = "<Your key here>"
# load in some sample data
reader = SimpleDirectoryReader(input_files=["f1.pdf","f2.pdf","f3.pdf"])
documents = reader.load_data()
# parse nodes
node_parser = SimpleNodeParser.from_defaults()
nodes = node_parser.get_nodes_from_documents(documents)If you check in the code above, you can see that I am using 3 pdf files, f1, f2 and f3. Let me just explain what they are about.
- f1.pdf — Annual review 2022 for the company nestle (79 pages)
- f2.pdf — 3 different reports for 2022 rolled into one pdf having 206 pages
- f3. pdf — Sustainability report 2022 (63 pages)
Questions to be asked
For the 5 different strategies open-sourced by LlamaIndex, we are going to ask the following 2 questions
- Q1: What was the Annual Bonus percentage paid out to the CEO?

- Q2: What is the minimum number of members in the board of directors?

Strategy 1: Hybrid Fusion Pack
What this does: Generates multiple queries from the same question and then aggregates the answer (vector + keyword search + reranking)[Source]
from llama_index.llama_pack import download_llama_pack
HybridFusionRetrieverPack = download_llama_pack(
"HybridFusionRetrieverPack",
"./hybrid_fusion_pack",
)
hybrid_fusion_pack = HybridFusionRetrieverPack(
nodes, chunk_size=256, vector_similarity_top_k=2, bm25_similarity_top_k=2
)
questions=[
"What was the Annual Bonus percentage paid out to the CEO?",
"What is the minimum number of members in the board of directors?"
]
# this will run the full pack
for question in questions:
response = hybrid_fusion_pack.run(question)
print(question,"\n",str(response))
print("*"*100)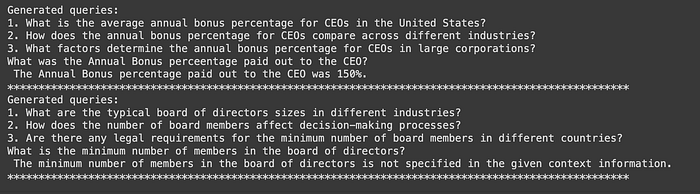
- Q1: What was the Annual Bonus percentage paid out to the CEO?
A: The Annual Bonus percentage paid out to the CEO was 150%.
- Q2: What is the minimum number of members in the board of directors?
A: The minimum number of members in the board of directors is not specified in the given context information.
Looks like it was able to answer 1 out of 2 questions.
Strategy 2: Query Rewriting Retriever Pack
What this does: Generates multiple queries from the same question and then aggregates the answer (Query Rewriting + Fusion)[Source]
# Download and Initialize Pack
from llama_index.llama_pack import download_llama_pack
QueryRewritingRetrieverPack = download_llama_pack(
"QueryRewritingRetrieverPack",
"./query_rewriting_pack",
)
query_rewriting_pack = QueryRewritingRetrieverPack(
nodes,
chunk_size=256,
vector_similarity_top_k=2,
)
# this will run the full pack
for question in questions:
response = query_rewriting_pack.run(question)
print(question,"\n",str(response))
print("*"*100)
- Q1: What was the Annual Bonus percentage paid out to the CEO?
A: The Annual Bonus percentage paid out to the CEO was 102.5%.
Interesting! Here it says that the annual bonus percentage paid out to the CEO was 102.5%. However we have seen in the previous answer that the percentage was 150. Let us look at the source material once:
So we go back to the file and do a reverse search with the value 102.5%

This means that the Hybrid Fusion Pack gave a wrong answer.
- Q2: What is the minimum number of members in the board of directors?
A: The minimum number of members in the board of directors is not specified in the given context information.
So this one got 1/2. Hybrid Fusion Pack got 0/2.
Strategy 3: Auto Merging Retriever Pack
It loads a document, builds a hierarchical node graph (with bigger parent nodes and smaller child nodes) and then gives the answer. [Source]
from llama_index.llama_pack import download_llama_pack
AutoMergingRetrieverPack = download_llama_pack(
"AutoMergingRetrieverPack",
"./auto_merging_retriever_pack",
)
auto_merging_pack = AutoMergingRetrieverPack(documents)
# this will run the full pack
for question in questions:
response = auto_merging_pack.run(question)
print(question,"\n",str(response))
print("*"*100)
- Q1: What was the Annual Bonus percentage paid out to the CEO?
A: The Annual Bonus percentage paid out to the CEO was 102.5% in 2022.
- Q2: What is the minimum number of members in the board of directors?
A: The minimum number of members in the board of directors is seven.
Which is correct. This one got both correct 2/2.
Strategy 4: Sentence Window Retriever
It loads a document, chunks it up, adds surrounding context as metadata to each chunk, and during retrieval inserts the context back into each chunk for response synthesis. [Source]
SentenceWindowRetrieverPack = download_llama_pack(
"SentenceWindowRetrieverPack",
"./sentence_window_retriever_pack",
)
sentence_window_retriever_pack = SentenceWindowRetrieverPack(
documents,
)
# this will run the full pack
for question in questions:
response = sentence_window_retriever_pack.run(question)
print(question,"\n",str(response))
print("*"*100)
- Q1: What was the Annual Bonus percentage paid out to the CEO?
A: The Annual Bonus percentage paid out to the CEO in 2022 was 102.5%.
- Q2: What is the minimum number of members in the board of directors?
A: The context information does not provide the minimum number of members in the board of directors.
Score: 1/2
Strategy 5: Small-to-big Retrieval Pack
It loads a document, builds a hierarchical node graph (with bigger parent nodes and smaller child nodes) [Source].
RecursiveRetrieverSmallToBigPack = download_llama_pack(
"RecursiveRetrieverSmallToBigPack",
"./recursive_retriever_stb_pack",
)
recursive_retriever_stb_pack = RecursiveRetrieverSmallToBigPack(
documents,
)
# this will run the full pack
for question in questions:
response = recursive_retriever_stb_pack.run(question)
print(question,"\n",str(response))
print("*"*100)
- Q1: What was the Annual Bonus percentage paid out to the CEO?
A: The Annual Bonus percentage paid out to the CEO was 102.5%.
- Q2: What is the minimum number of members in the board of directors?
A: The minimum number of members in the board of directors is seven.
Which is correct. This one got both correct 2/2.
Here is the comparison
- Strategy 1: Hybrid Fusion Retriever Pack — 0/2
- Strategy 2: Query Rewriting Retriever Pack— 1/2
- Strategy 3: Auto Merging Retriever Pack — 2/2
- Strategy 4: Sentence Window Retriever — 0/2
- Strategy 5: Small-to-big Retrieval Pack — 2/2
Looks like the Auto Merging Retriever Pack and Small-to-big Retrieval Pack provided by LlamaIndex perform the best for this experiment. In fact, I found both to be very similar.
The code is available as a google colab notebook. Give them a twirl and let me know if you find this useful.
Until next time.
Below are links to my other llm-based articles:
Open Source LLM:
**Textfiles on MemGPT** (Keep your eyes on this)
Paradigm Shift in Retrieval Augmented Generation: MemGPT [Not really open source as the article mentions use of OpenAI]
Multimodal Image Chat
Super Quick Visual Conversations: Unleashing LLaVA 1.5
PDF Related
Super Quick: Retrieval Augmented Generation Using Ollama
Super Quick: Retrieval Augmented Generation (RAG) with Llama 2.0 on Company Information using CPU
Evaluating the Suitability of CPU-based LLMs for Online Usage [Compare the time to response of three different LLMs for RAG activities]
Database Related
Super Quick: LLAMA2 on CPU Machine to Generate SQL Queries from Schema
Close Source LLM (OpenAI):
PDF Related
Chatbot Document Retrieval: Asking Non-Trivial Questions
Database Related
Super Quick: Connecting ChatGPT to a PostgreSQL database
General Info:
OpenAI Dev Day: 6 Announcements and why us RAGgers need to be worried
Super Quick: RAG Comparison between GPT4 and Open-Source

PlainEnglish.io 🚀
Thank you for being a part of the In Plain English community! Before you go:
- Be sure to clap and follow the writer️
- Learn how you can also write for In Plain English️
- Follow us: X | LinkedIn | YouTube | Discord | Newsletter
- Visit our other platforms: Stackademic | CoFeed | Venture