

GenAI
Building Retrieval-Augmented Generation systems, or RAGs, is easy. With tools like LamaIndex or LangChain, you can get your RAG-based Large Language Model up and running in no time. Sure, some engineering effort is needed to ensure the system is efficient and scales well, but in principle, building the RAG is the easy part. What's much more difficult is designing it well.
Having recently gone through the process myself, I discovered how many big and small design choices need to be made for a Retrieval-Augmented Generation system. Each of them can potentially impact the performance, behavior, and cost of your RAG-based LLM, sometimes in non-obvious ways.
Without further ado, let me present this — by no means exhaustive yet hopefully useful — list of RAG design choices. Let it guide your design efforts.

RAG components
Retrieval-Augmented Generation gives a chatbot access to some external data so that it can answer users' questions based on this data rather than general knowledge or its own dreamed-up hallucinations.
As such, RAG systems can become complex: we need to get the data, parse it to a chatbot-friendly format, make it available and searchable to the LLM, and finally ensure that the chatbot is making the correct use of the data it was given access to.
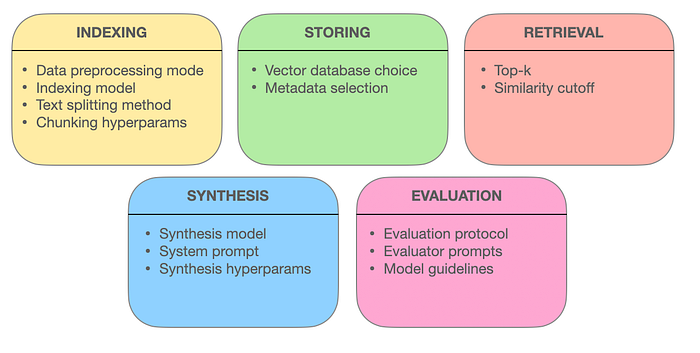
I like to think about RAG systems in terms of the components they are made of. There are five main pieces to the puzzle:
- Indexing: Embedding external data into a vector representation.
- Storing: Persisting the indexed embeddings in a database.
- Retrieval: Finding relevant pieces in the stored data.
- Synthesis: Generating answers to user's queries.
- Evaluation: Quantifying how good the RAG system is.
In the remainder of this article, we will go through the five RAG components one by one, discussing the design choices, their implications and trade-offs, and some useful resources helping to make the decision.
Indexing
In the context of RAG systems, indexing is the first step toward making the external data available to an LLM. It refers to fetching the data from wherever they live (SQL databases, Excel files, PDFs, images, video files, audio files, you name it) and converting it to a vector representation.

The indexing step, in essence, involves setting up, deploying, and maintaining a workflow that processes input data of different modalities and outputs vectors of numbers that represent the corresponding inputs.
The idea is that similar inputs will produce similar vector representations, while different inputs will end up far apart in the embedding space. This is key to enabling retrieval, where we look for content relevant (similar) to the user's query.
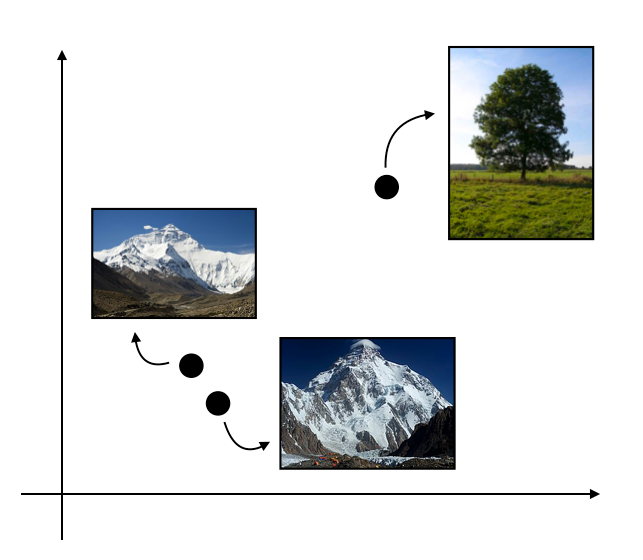
In this article, for the sake of simplicity, I will stick to the most popular use case of using textual data in RAGs. Bear in mind, though, that working with other modalities is possible, too.
When designing the indexing step, there are a few design choices to make:
- Data processing mode
- Indexing model
- Text splitting method
- Chunking hyperparameters
Let's look at them one by one.
Data processing mode
We can index new data either in batch mode or in streaming mode. Batch mode means that once in a pre-defined unit of time (hour, day, week, etc.) we collect all new data and pass it to the indexing model. The streaming mode, on the other hand, works continuously and indexes the new data the moment they become available.
This choice determines how quickly new data is available to the RAG system. The batch mode approach is typically cheaper and easier to maintain, but in situations where the chatbot must have the very latest information, streaming might be the only viable option.
For example, if you're building a legal assistant to answer questions about new pieces of legislation, and your government is only publishing new laws in a weekly bulletin, then batch processing with a weekly schedule will work great for you. On the other hand, if you need your chatbot to be knowledgeable about sports, including live results and statistics, streaming of the live data might be necessary.
Indexing model
Once we've decided how we will be passing the new data to the indexing model, we need to pick the model itself. Note that it does not need to be the same model we will use later for generating responses. The indexing model is only responsible for embedding texts into vectors. We will use it for both the external data, and the user queries so that they are mapped onto the same vector space enabling similarity search.
The indexing model we choose impacts the quality of the embeddings we store, and consequently, the relevance of contexts retrieved at synthesis. Typical considerations apply: proprietary and larger models tend to be better, but also slower and more expensive to access or run. This HuggingFace leaderboard compares different LLMs against a text embedding benchmark. Note that the best embedders are different than the best generators!
The best embedding models might be different than the best LLMs in general.
The speed aspect is important here since indexing happens not only while we embed new external data, but also at synthesis time when the model is generating responses (user query must be indexed before we can search for relevant data that matches it). Hence, a slower indexing model means the chatbot takes longer to generate the answer, negatively impacting the user experience.
Another important aspect that we need to take into account when deciding on the embedding model is that unlike the LLM used for generation which we can swap at any moment, a change of the indexing model requires us to re-index all the data. This might be expensive for large datasets. Hence, it's best to spend some thinking time on this design choice and pick the model that will work not only now, but also in the future (think of the predicted amount of data to embed, requirements for indexing and synthesis latency, cost evolution with more data and/or more queries, etc.).
Text splitting method
Before the input texts are indexed, they are first split into parts, and each part is indexed separately. We can choose to split the texts in a myriad of ways: by sentences, by tokens, by paragraphs, or even semantically (where each chunk is a group of semantically related sentences) or hierarchically (resulting in a hierarchy of child and parent chunks).
This design choice determines what pieces of text will be retrieved at synthesis. If we choose a paragraph-based split, we ensure that while generating the answer, our LLM will have access to full paragraphs of text. Splitting on tokens, on the other hand, will result in the model seeing word sequences that might not even form full sentences.
This choice should be dictated by the specifics of our application. For example, for a question-answering system where precise, detailed answers are required, indexing by sentences or semantically related chunks might be most effective. This allows the model to retrieve and synthesize information from specific, closely related pieces of text, leading to more accurate and contextually relevant answers.
On the other hand, for applications requiring a broader understanding or generation of text, such as summarization or topic exploration, paragraph-based or hierarchical indexing might be preferable. These methods ensure that the model can access and integrate a wider range of information, providing a more comprehensive view of the topic at hand.
Chunking hyperparameters
Finally, the text splitting or chunking process has a couple of hyperparameters to set, such as the chunk size (expressed in the number of tokens) and chunk overlap (are subsequent chunks overlapping, and how much).
This choice impacts the precision of the embeddings we generate. Smaller chunks lead to very specific and granular embeddings. This ensures that the retrieved information is precise, but we are risking that the most useful piece of information is absent from the top retrieved chunks. On the other hand, larger chunks should provide all the necessary information, but they can miss fine-grained details.
Another consideration is synthesis time. With larger chunks, the LLM will take longer to retrieve the context and respond to the user.
This blog post from LlamaIndex shows how to experiment with chunk sizes and pick the optimal one.
Storing
Once we have passed our input data to an indexing model to create the embeddings, we need to persist them somewhere from where they can be retrieved by the LLM when needed.
When designing the storing step of a RAG pipeline, the two most important decisions are:
- Database choice
- Metadata selection
Let's jump right in.
Database choice
While nothing prevents you from dumping your embeddings into your regular SQL database, this is a highly sub-optimal choice. RAG systems typically use what's called vector databases or vector stores instead. Vector stores are a specific type of database optimized for storing vector representations and running quick and efficient searches across them — just what the RAG system needs.
With the advent of LLM-powered systems, a myriad of new vector database solutions have been springing up. Take a look at this website offering a quite detailed comparison of different offerings. When choosing your database, the two main aspects to consider are the price and the available features.
Depending on your budget, you can choose from free, open-source vector stores, or managed software-as-a-service offerings. The latter typically come in two flavors: either everything runs on their cloud and you pay depending on your plan, or the solution is deployed in your own cloud where you pay for the resources you use. Some vector store providers also offer a system in which they host the database but let you pay for what you use only, e.g. storage and read and write units.
Next to pricing the other crucial aspect of a vector store is the feature it offers. Here is a short list of features you might want your vector store to offer:
- Integration with your development framework, such as LlamaIndex or Langchain.
- Multi-modal search support — only if you are dealing with many modalities, e.g. images and text.
- Advanced search support, e.g. techniques such as hybrid search — more on that later.
- Embedding compression — some vector stores offer built-in compression, decreasing your storage usage. This is particularly useful when you have a lot of data.
- Auto-scaling — some vector stores will adapt to traffic requirements, ensuring constant availability.
When picking the vector store, know your budget and critically think about what features you really need. You will find that, in order to distinguish themselves from the crowd, some vector stores offer cool advanced features, but most of them won't probably be needed for your use-case.
Metadata selection
Next to the indexed data itself, you might want to also store some metadata in your vector store. Metadata helps to find relevant pieces of input data at retrieval.
For example, if your RAG is a sports news chatbot, you might want to tag all your input data with the corresponding discipline such as 'football' or 'volleyball'. At retrieval, if the user is asking about football matches, you might remove all data without the 'football' tag from the search, making it much faster and more accurate.
In many applications, you will already have a lot of metadata: the input text's source, topic, creation date, etc. These are useful to store in the vector store. Moreover, frameworks such as LlamaIndex offer automated metadata extraction which uses LLMs to automatically create some metadata from your input data, such as the questions that a given piece of text can answer or the entities (i.e. names of places, people, things) it mentions.
Storing the metadata is not free, however. Thus, my advice is to picture the ideal-scenario working RAG system, and to ask oneself: what kind of questions will the users ask, and how what kind of metadata might help find relevant data to answer these questions? Then, store only that. Storing all the metadata you can think of might result in the costs ramping up.
Retrieval
Retrieval refers to finding pieces in the stored data that are relevant to the user's query. In its simplest form, it boils down to embedding the query with the same model that was used for indexing and comparing the embedded query with the indexed data.
There are a few things you would need to think about when designing the retrieval step:
- Retrieval strategy
- Retrieval hyperparameters
- Query transformations
Let's tackle each of them.
Retrieval strategy
The arguably simplest way to retrieve context from the stored data is to pick the embeddings that are the most similar to the user's query, as measured by some similarity metric such as cosine similarity. This approach is known as semantic search, as we aim to find texts semantically similar to the query.
However, with this basic semantic search approach, the retrieved text might fail to include the most important keywords from the query. A solution to this is the so-called hybrid search, which combines the results from the semantic search with those from the literal keyword search.
Typically, we will find multiple embeddings that are similar to the user's query. Thus, it's very useful if they are ordered correctly, that is: the larger the computed similarly to the user's query, the more relevant the text chunk. Ranking algorithms take care of this, and one of the most popular ones in RAGs is BM25, or Best Match 25. It's a term-based ranker that scores text chunks based on their lengths and the frequencies of different terms in them. A slightly more complex method is the Reciprocal Rank Fusion or RRF. It evaluates the search scores from already ranked results to generate a single result. You will find all of these already implemented in frameworks like LlamaIndex.
Choosing the right retrieval strategy should mostly be guided by our RAG's performance (more on RAG evaluation later on), as well as the costs. It's good to think about it much earlier, at the indexing stage already, since the choice of the vector store might restrict the available retrieval strategies.
The choice of the vector store might restrict the available retrieval strategies.
Chunk window retrieval is an interesting twist to vanilla retrieval strategies. In it, we identify the most relevant chunks using any of the approaches discussed above, but then, instead of passing only these retrieved chunks to the model as context, we additionally pass the preceding and following chunks for each of them. This provides the LLM with a larger context.
Increasing the window size (e.g. by passing two previous and two next chunks, or three) hopefully leads to more relevant contexts, but it also means a larger token usage and consequently a larger cost. Moreover, the benefits of increasing the window size tend to level off, so my advice is: don't set it too large.
Retrieval hyperparameters
Whichever retrieval strategy we end up choosing, it will come with some hyperparameters to tune. Most strategies will at least involve the following two:
- Top-k
- Similarity cutoff
Top-k affects how many text chunks are provided to the model at synthesis. A larger top-k means a larger and more relevant context at the price of increasing the number of tokens and the cost. When we set top-k too high, however, we risk passing less relevant chunks to the model.
The similarity cutoff plays much of the same role. It limits the text chunks we pass to the LLM to only those that are at least this similar to the user's query. Set it too high, and you might end up retrieving few or even no chunks. Too low a value will lead to lots of irrelevant texts being passed to the model.
The interplay between top-k and similarity cutoff requires us to evaluate different combinations of these two jointly.
Retrieval hyperparameters should be treated like all hyperparams in a machine learning process: one should tune them based on the model's performance. One thing to remember is to always tune them both in tandem. The interplay between top-k and similarity cutoff requires us to evaluate different combinations of these two jointly.
Query transformations
So far, when talking about the retrieval process, we've discussed the vector store side of it: how to find what's relevant in these databases and how to pass it to the model. However, there is the other side of the coin, too: the user's query.
In some cases, the way the query is phrased is not optimal in the context of finding relevant data to support the answer. A solution is to augment the user's query before performing retrieval. This can be done in a couple of different ways.
- Query rewriting: Use an LLM to rephrase the query using different words and grammatical structures. This is especially useful for queries provided by non-native speakers of the language in which perform the retrieval, as it can correct mistakes and make the query clearer.
- Sub-query generation: Split the user's query into parts or generate new, more detailed queries based on the original one, and pass them all to the model as separate, bullet-listed sub-queries. This approach can improve the RAG performance for short or vague queries.
- Hypothetical Document Embeddings (HyDE): A very clever technique in which we let the plain LLM generate a (possibly hallucinated or otherwise inaccurate) answer to the user's query, and then we perform retrieval on the queries and the answer combined. This approach assumes that the generated answer, even if poor, will be similar in some respects to a good answer that we are looking for, so including it in the search can improve the relevancy of retrieved context.
Query transformation techniques can improve RAG performance a great deal, so it's always a good idea to try them out — especially if you have a reason to expect short and vague queries and non-native speakers as RAG users.
The possible downside of employing these techniques to keep in mind is a slower retrieval (due to more versions of the query or additional subqueries or answers being involved in the search). Additionally, techniques such as HyDE should be used with caution, as they may bias open-ended queries and mislead when the query can be misinterpreted without context (see the LlamaIndex docs for some examples of these cases).
Synthesis
Synthesis, also referred to as generation, is the RAG step in which the LLM synthesizes a response to the user's query.
The three most important considerations at this step are:
- Synthesis model
- System prompt
- Synthesis hyperparameters
Let's discuss each of them.
Synthesis model
The choice of the model that will generate the responses is crucial. It affects how coherent, grammatically correct, helpful, unbiased, and safe the responses are. It might also significantly impact the cost of your solution should you choose a proprietary model.
Unless restricted by budget limits or inference time requirements, you would typically want to use the best Large Language Model out there. But how do you find it? A simple approach is to look at the benchmarks.
In the Chatbot Arena, people ask a question to two anonymous models (e.g., ChatGPT, Claude, Llama) and vote for the better one, not knowing what models are competing. The winner of the battle receives points and the loser gets them subtracted (to be precise, they're computing ELO scores). As a result, a leaderboard emerges that lets us see which LLMs are currently the best, according to the community.
If your RAG application is highly domain-specific, such as analyzing legal texts, you might want your synthesis model to be very good at logical reasoning, for example, even at the cost of a worse performance in other aspects. If that's the case, take a look at the common LLM evaluation benchmarks and pick the model that optimizes for the particular benchmark you're most interested in.
System prompt
The system prompt is the message prepended to the context and query sent to the LLM. It "pre-programms" the chatbot to behave in the desired way.
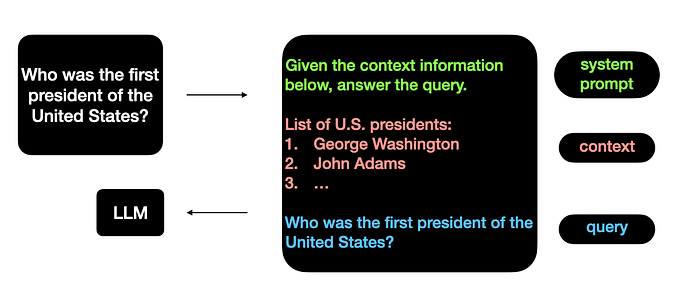
The exact wording of the system prompt turns out to be very important for the RAG performance. Unfortunately, coming up with the right phrasing is more of an art than a science and you'd need to experiment to find what works best for your application.
One thing that you definitely should include in the system prompt is the instruction to behave like a good RAG, such as: "Given the context information below, answer the query. Use only the information from the context. Don't use any general knowledge.".
You might also consider using the system prompt to provide a template for how the response should look like, to tell the LLM to answer in the style of somebody famous, to be as succinct as possible, or to the contrary, to provide long and detailed answers. Whatever works best for your use case. LlamaIndex docs detail different approaches to prompt engineering for RAG.
Synthesis hyperparameters
Another step in the RAG pipeline means yet another set of hyperparameters to guess, ahem, to tune.
At synthesis, the two main hyperparams you should be interested in are context window size and maximum response size. They affect how much context the model gets to see and how long a reply is it allowed to produce, respectively.
Context window size deliberations are somewhat similar to what we already discussed when talking about the retrieval hyperparameters (top-k and similarity cutoff). A longer context window means more information at the model's disposal but also a risk that some of it is irrelevant.
Maximum response size should typically be guided by your application use case. A simple tuning strategy that worked for me is to choose a starting value that you believe is large enough so that the response can be comprehensive but small enough to avoid the generation of long stories. Then, at evaluation (see below), if you observe that the responses tend to answer the queries only partly while hitting the maximum size limit, you increase this limit.
Another important consideration is the cost. If you're using a proprietary LLM at synthesis, you might be charged depending on both the context length and the generated output length. Hence, decreasing these two hyperparameters can lead to a cost reduction.
Evaluation
RAG systems are basically Large Language Models on steroids. Evaluation of LLMs is a complex topic in itself (I have written a separate article about it) and the addition of context retrieval makes it even more challenging.
As per popular interest, I am going to write a dedicated piece about RAG evaluation and the so-called RAG triad metrics in the upcoming days. Be sure to follow so that you don't miss it! Here, let me list some higher-level considerations to ponder when designing a RAG.
The most important aspects of the evaluation step are:
- Evaluation protocol
- Evaluator prompts
- Model guidelines
Let's take a look at each of them.
Evaluation protocol
The evaluation protocol is a detailed description of how system evaluation will be carried out. It provides answers to the following questions:
- What data to test on?
- Which metrics to look at?
- What are the optimizing and satisficing metrics?
Obtaining a good test set for RAG goes a long way toward designing a high-quality system. Unlike in traditional machine learning systems, for RAG evaluation with often don't need the ground truth, which in this case would be "golden", reference answers. It's enough to collect user queries, retrieved contexts, and generated answers.
Ideally, all these should come from the target users of our RAG system. For example, some users can be granted early access to play with the first version of the system, at the same time generating test datasets for evaluation.
Ideally, the test data should come from the target users of our RAG system, e.g. collected through an early access release.
When this is not possible, or we want to evaluate the RAG before releasing it to anyone, we can use one of the LLama Datasets for that purpose. This evaluation, however, will not be representative of the production environment our RAG will operate in.
Next, we need to collect the performance metrics to track and optimize. There is quite a lot to choose from, including:
- Response accuracy and truthfulness;
- The RAG triad: groundedness, answer relevance, and context relevance;
- Coherence and grammatical correctness of the generated text;
- The amount of bias, harmful content, or impoliteness in the answer;
- User satisfaction, as captured by some sort of survey.
Once we have selected the metric, we need to pick one of them to be the optimizing metric, that is the one whose value we want to optimize as much as possible, as long as the other (satisficing) metrics meet pre-selected thresholds. If this approach is new to you, check out this YouTube video by Andrew Ng from DeepLearningAI where he explains optimizing and satisficing metrics.
Depending on the use case, you might choose different metrics as the optimizing metric. My suggestion is usually to use a (possibly weighted) average of the three RAG triad metrics since they capture the essence of the RAG system's purpose quite well — more on this in an upcoming article!
Evaluator prompts
With the evaluation protocol in place, we can proceed with computing the individual metrics. The fun part begins with LLM-based metrics (metrics generated by a Large Language Model, which need to be prompted to generate them).
Consider the faithfulness score which captures whether the generated answer is supported by the retrieved context. To get this score, we prompt our RAG with a test set example and collect the answer it generated and the context that was retrieved. Then, we pass these two to another LLM, prompting it to evaluate the faithfulness.
The default faithfulness prompt in LlamaIndex, for example, is the following:
Please tell if a given piece of information is supported by the context. You need to answer with either YES or NO. Answer YES if any of the contexts supports the information, even of most of the context is unrelated. Some examples are provided below. (…)
This leads to a binary score where each test example is awarded either 0 (not faithful) or 1 (faithful).
As you can imagine, however, the exact wording of the evaluator prompt can have a large impact on its behavior. While the default prompts in popular frameworks like LlamaIndex or LangChain work decently well (after all, quite some work was invested in fine-tuning every little word), you might find that tweaking them could be beneficial for your use case.
Model guidelines
Model guidelines are a set of rules you define that the RAG system should follow. Let's once again take a look at the LlamaIndex's defaults.
"The response should fully answer the query." "The response should avoid being vague or ambiguous." "The response should be specific and use statistics or numbers when possible."
These are great in general, but you might want replace or extend them with something else that better fits your use case.
For example, you might want to emphasize clarity and conciseness, especially if your application is focused on delivering information quickly and clearly. In such cases, you could add:
"The response should be concise, avoiding unnecessary words or complex sentences that could confuse the user."
For applications dealing with sensitive topics or aiming to foster a positive community, guidelines related to respect and sensitivity might be crucial:
"The response should be respectful and sensitive to users' diverse backgrounds, avoiding language that might be considered offensive or discriminatory."
And so on — you get the gist.
Conclusion
Designing a Retrieval-Augmented Generation system requires a lot of large and small decisions that might have a huge impact on the RAG performance. I strived to cover the most important ones based on my own experience building RAGs. If you see anything missing, do let me know in the comments so that I can add it to the article!
And for now, I will leave you with this cheatsheet summarizing the most important RAG design choices.

Thanks for reading! If you liked this post, please consider subscribing for email updates on my new articles. Want to chat? You can ask me anything or book me for a 1:1 here. You can also try one of my other articles. Can't choose? Pick one of these: