


Model merging is a technique that combines two or more LLMs into a single model. It's a relatively new and experimental method to create new models for cheap (no GPU required). Model merging works surprisingly well and produced many state-of-the-art models on the Open LLM Leaderboard.
In this tutorial, we will implement it using the mergekit library. More specifically, we will review four merge methods and provide examples of configurations. Then, we will use mergekit to create our own model, Marcoro14–7B-slerp, which became the best-performing model on the Open LLM Leaderboard (02/01/23).
The code is available on GitHub and Google Colab. I recommend using my automated notebook to easily run mergekit: 🥱 LazyMergekit.
A special thanks to Charles Goddard, the author of the mergekit library, for reviewing this article.
🤝 Merge algorithms
In this section, we will focus on four methods currently implemented in mergekit. Note that there are other methods, such as linear and Task Arithmetic. If you're interested in papers on model merging, I recommend this excellent collection on Hugging Face.
1. SLERP
Spherical Linear Interpolation (SLERP) is a method used to smoothly interpolate between two vectors. It maintains a constant rate of change and preserves the geometric properties of the spherical space in which the vectors reside.
There are several reasons to prefer SLERP over a traditional linear interpolation. For example, in high-dimensional spaces, linear interpolation can lead to a decrease in the magnitude of the interpolated vector (i.e., it reduces the scale of weights). Moreover, the change in direction of the weights often represents more meaningful information (like feature learning and representation) than the magnitude of change.
SLERP is implemented using the following steps:
- Normalize the input vectors to unit length, ensuring they represent directions rather than magnitudes
- Calculate the angle between these vectors using their dot product.
- If the vectors are nearly collinear, it defaults to linear interpolation for efficiency. Otherwise, SLERP computing scale factors based on the interpolation factor
t(t=0= 100% of the first vector,t=1= 100% of model 2) and the angle between the vectors. - These factors are used to weigh the original vectors, which are then summed to obtain the interpolated vector.
SLERP is currently the most popular merging method, but it is limited to combining only two models at a time. It is still possible to hierarchically combine multiple models, as shown in Mistral-7B-Merge-14-v0.1.
Example of configuration:
slices:
- sources:
- model: OpenPipe/mistral-ft-optimized-1218
layer_range: [0, 32]
- model: mlabonne/NeuralHermes-2.5-Mistral-7B
layer_range: [0, 32]
merge_method: slerp
base_model: OpenPipe/mistral-ft-optimized-1218
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16This is a classic SLERP configuration, applied to every layer of both models. Note that we input a gradient of values for the interpolation factor t. The parameters for the self-attention and MLP layers will use different combinations of OpenPipe/mistral-ft-optimized-1218 and mlabonne/NeuralHermes-2.5-Mistral-7B. The other layers are a 50/50 mixture of the two models.
You can find the final model on the Hugging Face Hub at mlabonne/NeuralPipe-7B-slerp.
2. TIES
Introduced in this paper by Yadav et al., TIES-Merging is designed to efficiently merge multiple task-specific models into a single multitask model. It addresses two main challenges in model merging:
- Redundancy in model parameters: It identifies and eliminates redundant parameters within task-specific models. This is achieved by focusing on the changes made during fine-tuning, identifying the top-k% most significant changes, and discarding the rest.
- Disagreement between parameter signs: Conflicts arise when different models suggest opposing adjustments to the same parameter. TIES-Merging resolves these conflicts by creating a unified sign vector that represents the most dominant direction of change across all models.
TIES-Merging is divided into the following three steps:
- Trim: Reduces redundancy in task-specific models by retaining only a fraction the most significant parameters (density parameter) and resetting the rest to zero.
- Elect Sign: Resolves sign conflicts across different models by creating a unified sign vector based on the most dominant direction (positive or negative) in terms of cumulative magnitude.
- Disjoint Merge: Averages parameter values that align with the unified sign vector, excluding zero values.
Unlike SLERP, TIES can merge multiple models at a time.
Example of configuration:
models:
- model: mistralai/Mistral-7B-v0.1
# no parameters necessary for base model
- model: OpenPipe/mistral-ft-optimized-1218
parameters:
density: 0.5
weight: 0.5
- model: mlabonne/NeuralHermes-2.5-Mistral-7B
parameters:
density: 0.5
weight: 0.3
merge_method: ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
normalize: true
dtype: float16With this config, we use Mistral-7B as a base model to calculate the delta weights. We merge the same two models: mistral-ft-optimized-1218 (50%) and NeuralHermes-2.5-Mistral-7B (30%) with normalization. Here, the density means that we're only retaining 50% of the parameters of each model (the other half comes from the base model).
Note that the sum of the weights is not equal to 1 in the config, but the normalize: true parameter will automatically normalize them internally. This config is inspired by the parameters provided by the author of OpenHermes-2.5-neural-chat-7b-v3–1–7B.
You can find the final model on the Hugging Face Hub at mlabonne/NeuralPipe-7B-ties.
3. DARE
Introduced by Yu et al. (2023), DARE uses an approach similar to TIES with two main differences:
- Pruning: DARE randomly reset fine-tuned weights to their original values (those of the base model).
- Rescaling: DARE rescales the weights to keep the expectations of model outputs approximately unchanged. It adds the rescaled weights of both (or more) models to the weights of the base model with a scale factor.
Mergekit's implementation of this method has two flavors: with the sign election step of TIES (dare_ties) or without (dare_linear).
Example of configuration:
models:
- model: mistralai/Mistral-7B-v0.1
# No parameters necessary for base model
- model: samir-fama/SamirGPT-v1
parameters:
density: 0.53
weight: 0.4
- model: abacusai/Slerp-CM-mist-dpo
parameters:
density: 0.53
weight: 0.3
- model: EmbeddedLLM/Mistral-7B-Merge-14-v0.2
parameters:
density: 0.53
weight: 0.3
merge_method: dare_ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
int8_mask: true
dtype: bfloat16In this configuration, we merge three different models based on Mistral-7B using dare_ties. This time, I chose weights that sum to 1 (the sum should be between 0.9 and 1.1). The density parameter is a little higher than what's recommended in the paper (<0.5), but it looks like it gives consistently better results (see this discussion).
You can find it on the Hugging Face Hub at mlabonne/Daredevil-7B. It's also the best merge model in this article, outperforming even Marcoro14–7B-slerp.
4. Passthrough
The passthrough method differs significantly from the previous ones. By concatenating layers from different LLMs, it can produce models with an exotic number of parameters (e.g., 9B with two 7B parameter models). These models are often referred to as "frankenmerges" or "Frankenstein models" by the community.
This technique is very experimental, but it managed to create impressive models, like goliath-120b using two Llama 2 70B models. The recently released SOLAR-10.7B-v1.0 also uses the same idea, called depth-up scaling in their paper.
Example of configuration:
slices:
- sources:
- model: OpenPipe/mistral-ft-optimized-1218
layer_range: [0, 32]
- sources:
- model: mlabonne/NeuralHermes-2.5-Mistral-7B
layer_range: [24, 32]
merge_method: passthrough
dtype: bfloat16The resulting frankenmerge will have all the 32 layers from the first model and 8 additional layers from the second model. This creates a frankenmerge with a total of 40 layers and 8.99B parameters. This config is inspired by GML-Mistral-merged-v1.
You can find the final model on the Hugging Face Hub at mlabonne/NeuralPipe-9B-merged.
💻 Merge your own models
In this section, we will use mergekit to load a merge configuration, run it, and upload the resulting model to the Hugging Face Hub.
First of all, we install mergekit directly from source as follows:
!git clone https://github.com/cg123/mergekit.git
!cd mergekit && pip install -q -e .In the following block, we load the merge configuration in a YAML format. We also specify the name of the merged model for future use. You can copy/paste any configuration from the previous section here.
This time, we will use two different models: Marcoroni-7B-v3 and Mistral-7B-Merge-14-v0.1 and merge them with the SLERP method. We save the config as a yaml file to be used as input in the merge command.
import yaml
MODEL_NAME = "Marcoro14-7B-slerp"
yaml_config = """
slices:
- sources:
- model: AIDC-ai-business/Marcoroni-7B-v3
layer_range: [0, 32]
- model: EmbeddedLLM/Mistral-7B-Merge-14-v0.1
layer_range: [0, 32]
merge_method: slerp
base_model: AIDC-ai-business/Marcoroni-7B-v3
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
"""
# Save config as yaml file
with open('config.yaml', 'w', encoding="utf-8") as f:
f.write(yaml_config)We run the merge command with the following parameters:
--copy-tokenizerto copy the tokenizer from the base model--allow-crimesand--out-shard-sizeto chunk the models into smaller shards that can be computed on a CPU with low RAM--lazy-unpickleto enable the experimental lazy unpickler for lower memory usage
In addition, some models can require the --trust_remote_code flag (this is not the case with Mistral-7B).
This command will download the weights of all the models listed in the merge configuration and run the selected merge method (it should take ~10 minutes).
# Merge models
!mergekit-yaml config.yaml merge --copy-tokenizer --allow-crimes --out-shard-size 1B --lazy-unpicklThe model is now merged and saved in the `merge` directory. Before uploading it, we can create a README file with all the information required for reproducibility. The following code block defines a Jinja template and automatically fills it with the data from the merge configuration.
!pip install -qU huggingface_hub
from huggingface_hub import ModelCard, ModelCardData
from jinja2 import Template
username = "mlabonne"
template_text = """
---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
{%- for model in models %}
- {{ model }}
{%- endfor %}
---
# {{ model_name }}
{{ model_name }} is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
{%- for model in models %}
* [{{ model }}](https://huggingface.co/{{ model }})
{%- endfor %}
## 🧩 Configuration
```yaml
{{- yaml_config -}}
```
"""
# Create a Jinja template object
jinja_template = Template(template_text.strip())
# Get list of models from config
data = yaml.safe_load(yaml_config)
if "models" in data:
models = [data["models"][i]["model"] for i in range(len(data["models"])) if "parameters" in data["models"][i]]
elif "parameters" in data:
models = [data["slices"][0]["sources"][i]["model"] for i in range(len(data["slices"][0]["sources"]))]
elif "slices" in data:
models = [data["slices"][i]["sources"][0]["model"] for i in range(len(data["slices"]))]
else:
raise Exception("No models or slices found in yaml config")
# Fill the template
content = jinja_template.render(
model_name=MODEL_NAME,
models=models,
yaml_config=yaml_config,
username=username,
)
# Save the model card
card = ModelCard(content)
card.save('merge/README.md')Now that we have a model card, we can push the entire folder to the Hub.
from google.colab import userdata
from huggingface_hub import HfApi
username = "mlabonne"
# Defined in the secrets tab in Google Colab
api = HfApi(token=userdata.get("HF_TOKEN"))
api.create_repo(
repo_id=f"{username}/{MODEL_NAME}",
repo_type="model"
)
api.upload_folder(
repo_id=f"{username}/{MODEL_NAME}",
folder_path="merge",
)The model is now available on the Hugging Face Hub at mlabonne/Marcoro14–7B-slerp. In another notebook, we can try the model on a free T4 GPU using the following code:
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "mlabonne/Marcoro14-7B-slerp"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)We're asking the question "What is a Large Language Model?" and received this output:
A large language model is a type of artificial intelligence (AI) system that has been trained on vast amounts of text data. It's designed to understand and generate human-like language, making predictions on what words or phrases might come next in a sentence or document. These models use complex algorithms and neural network architectures to learn from the data and improve their performance over time. Some well-known large language models include GPT-3 from OpenAI and BERT from Google.
It's looking good, but we need a more comprehensive evaluation. For this kind of general-purpose model, there are a few interesting benchmarks:
- Chatbot Arena, which compiles an Elo-based LLM leaderboard based on human votes.
- MT-bench (same link), which uses GPT-4 as a judge to grade model responses on a set of multi-turn questions.
- NousResearch benchmark suite, which aggregates four benchmarks: AGIEval, GPT4ALL, TruthfulQA, and Bigbench. GPT4ALL itself includes HellaSwag, OpenBookQA, Winogrande, ARC-Easy, ARC-Challenge, BoolQ, and PIQA.
- Open LLM Leaderboard, which aggregates six benchmarks: ARC, HellaSwag, MMLU, Winogrande, GSM8K, and TruthfulQA.
Unfortunately, we can't submit our model to the Chatbot Arena. Instead, I chose to evaluate it using the Open LLM Leaderboard and NousResearch benchmarks.
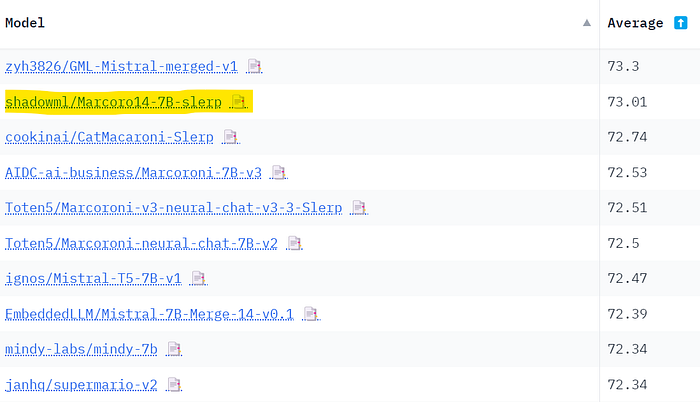
I submitted our model to the Open LLM Leaderboard ("🚀R Subit here!" tab). As shown in the introduction, it ranked as the best 7B parameter model on the leaderboard. Here are the complete results:

The problem with the Open LLM Leaderboard is that these benchmarks are public. It means that people can train LLMs on the test data to get better results. By merging the best models, we also contaminate our own results. It is safe to assume that Marcoro14–7B-slerp is contaminated and some models used in this merge have been trained on the test set. If you want to create the best model and not hack the leaderboard, I recommend only using non-merge models to create your own merges.
This is why we don't want to only rely on the OpenLLM Leaderboard. For NousResearch benchmark suite, I used 🧐 LLM AutoEval to compute the scores automatically with a simple Colab notebook. Here are the results compared to the excellent OpenHermes-2.5-Mistral-7B:

We get a significant improvement over this model on every benchmark. Note that NousResearch benchmark suite shares some tasks with the Open LLM Leaderboard: ARC-Challenge, TruthfulQA, HellaSwag, and Winogrande. To the best of my knowledge, Bigbench is the only benchmark that is 100% different (feel free to contact me if that's not the case). However, one of the models we used in this merge could still have been trained on Bigbench.
Conclusion
In this article, we introduced the concept of merging LLMs with four different methods. We detailed how SLERP, TIES, DARE, and passthrough work and provided examples of configurations. Finally, we ran SLERP with mergekit to create Marcoro14–7B-slerp and upload it to the Hugging Face Hub. We obtained excellent performance on two benchmark suites: Open LLM Leaderboard (best-performing 7B model) and NousResearch. If you want to create your own merges, I recommend using my automated notebook 🥱 LazyMergekit.
Another way of combining multiple models is to merge them in a Mixture of Experts (MoE) architecture. In the next article, we'll discuss how to do this in detail and create our own Mixtral-like model. If you liked this article, please follow me on Medium and Twitter @mlabonne.
Learn more about machine learning and support my work with one click — become a Medium member here: