


There are now many methods to align large language models (LLMs) with human preferences. Reinforcement learning with human feedback (RLHF) was one of the first and brought us ChatGPT, but RLHF is very costly. DPO, IPO, and KTO are notably cheaper than RLHF as they don't need a reward model.
While DPO and IPO are cheaper, they still require to train two different models. One model for the supervised fine-tuning (SFT) step, i.e., training the model to answer instructions, and then the model to align with human preferences using the SFT model for initialization and as a reference.
ORPO is yet another new method for LLM alignment but this one doesn't even need the SFT model. With ORPO, the LLM jointly learns to answer instructions and human preferences.
In this article, I explain ORPO and review its performance. I show how to use it to turn Mistral 7B into a chat model using consumer hardware.
Joint SFT and Preference Optimization
ORPO is presented in this paper:
ORPO: Monolithic Preference Optimization without Reference Model
The authors motivate very well ORPO by demonstrating that the SFT step is not ideal in the alignment pipeline. While fine-tuning the model on instruction datasets indeed adapts the model to answer instructions in a particular domain, the probability of generating answers that humans would reject is also increased.
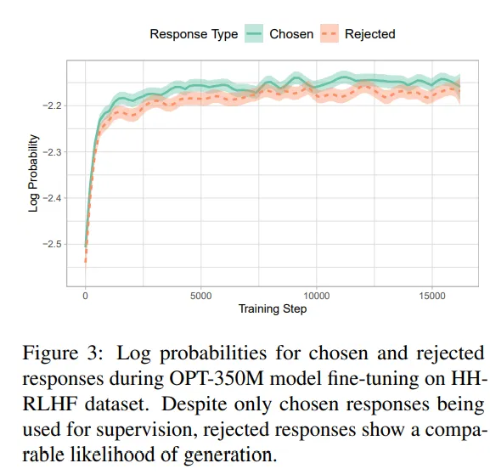
This is intuitive. Chosen and rejected responses may share a lot of common points: same domain, same format, etc. hence the increased probability of generating an answer relevant to the task but incorrect.
Techniques like DPO are then necessary to decrease the probability of the rejected responses while increasing the probability of the chosen responses, i.e., increasing the gap between the curves in the figure above. Preference optimization techniques are trained on datasets made of:
- prompt
- chosen answer
- rejected answer
As for SFT, it is trained on prompts paired with chosen answers. The dataset used for SFT can be the same as preference optimization but without the "rejected" answers.
So, intuitively, we should be able to fine-tune a base LLM to learn how to answer instructions while also learning to penalize and prefer answers, using the same dataset.
This is what ORPO does.
ORPO simply modifies the training loss by complementing the negative log-likelihood loss with an OR loss (OR for Odd Ratio):
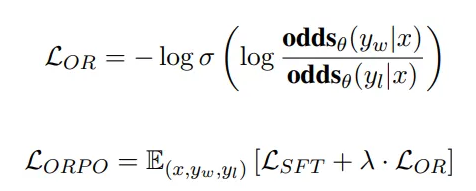
The OR loss weakly penalizes the rejected answers while it strongly rewards the chosen ones. Note that a hyperparameter lambda weighs the OR loss.
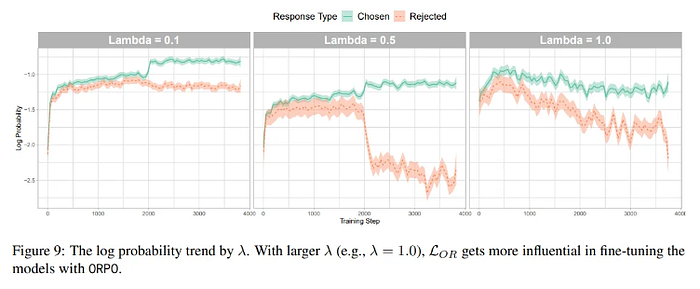
Lamba at 0.1 seems to work well. If set to 0.5, the discrimination between chosen and rejected outputs is stronger but the probability of the chosen answers is also decreased. Nonetheless, it might be better to set lambda to 0.5 for specific applications where rejecting bad answers is more critical than getting correct answers.
With ORPO's loss, the model learns what it would have learned during SFT while also learning human preferences, using only one training dataset and one model.

One downside of this method is that it might require larger datasets of preferences than the ones that would have been enough for preference optimization with other techniques.
Running ORPO with TRL
All the code described in this section is also ready to use in this notebook:
The notebook also includes an example of ORPO training with GaLore.
Hugging Face's TRL library already supports ORPO but it has been added recently so we need to install it from source, along with all the other following packages:
pip install -q -U bitsandbytes
pip install --upgrade -q -U transformers
pip install -q -U peft
pip install -q -U accelerate
pip install -q -U datasets
pip install -q -U git+https://github.com/huggingface/trl.gitThen, import:
import torch, multiprocessing
from datasets import load_dataset
from peft import LoraConfig, prepare_model_for_kbit_training
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
)
from trl import ORPOTrainer, ORPOConfigI import "multiprocessing" since I will use it to apply the chat template to the dataset. We also need to import ORPOConfig which we will use to configure ORPO. It inherits from Transformers' TrainingArguments.
I also systematically run the following code to be sure that FlashAttention and bfloat16 will be used if compatible with the GPU:
import os
major_version, minor_version = torch.cuda.get_device_capability()
if major_version >= 8:
os.system("pip install flash-attn")
torch_dtype = torch.bfloat16
attn_implementation='flash_attention_2'
print("Your GPU is compatible with FlashAttention and bfloat16.")
else:
torch_dtype = torch.float16
attn_implementation='eager'
print("Your GPU is not compatible with FlashAttention and bfloat16.")Next, we can load the dataset. I use "HuggingFaceH4/ultrafeedback_binarized" (MIT license) which has been compiled by Hugging Face to train the Zephyr models. I apply a chat template to the "chosen" and "rejected" columns to stringify the JSON.
dataset = load_dataset("HuggingFaceH4/ultrafeedback_binarized", split=["train_prefs","test_prefs"])
def process(row):
row["chosen"] = tokenizer.apply_chat_template(row["chosen"], tokenize=False)
row["rejected"] = tokenizer.apply_chat_template(row["rejected"], tokenize=False)
return row
dataset[0] = dataset[0].map(
process,
num_proc= multiprocessing.cpu_count(),
load_from_cache_file=False,
)
dataset[1] = dataset[1].map(
process,
num_proc= multiprocessing.cpu_count(),
load_from_cache_file=False,
)Then, we load the tokenizer, configure it, and load the model.
model_name = "mistralai/Mistral-7B-v0.1"
#Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, add_eos_token=True, use_fast=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = 'left' #Necessary for FlashAttention compatibility
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
model_name, torch_dtype=torch_dtype, quantization_config=bnb_config, device_map={"": 0}, attn_implementation=attn_implementation
)
model = prepare_model_for_kbit_training(model)
#Configure the pad token in the model
model.config.pad_token_id = tokenizer.pad_token_idThe model is quantized on the fly with bitsandbytes' NF4 data type (configured with BitsAndBytesConfig). Don't forget "prepare_model_for_kbit_training" which enables gradient checkpointing and saves a lot of memory.
For the configuration of LoRA, I use standard hyperparameters. To get better results, you might want to increase "r" but it would also increase the memory consumption.
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.05,
r=16,
bias="none",
task_type="CAUSAL_LM",
target_modules= ['k_proj', 'q_proj', 'v_proj', 'o_proj', "gate_proj", "down_proj", "up_proj"]
)You can also set "use_dora=True" in LoraConfig to train a better (but slower) adapter with DoRA.
Then, we set the ORPOConfig and start the training:
orpo_config = ORPOConfig(
output_dir="./results/",
evaluation_strategy="steps",
do_eval=True,
optim="paged_adamw_8bit",
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
per_device_eval_batch_size=2,
log_level="debug",
logging_steps=20,
learning_rate=8e-6,
eval_steps=20,
max_steps=100,
save_steps=20,
save_strategy='epoch',
warmup_ratio=0.1,
lr_scheduler_type="linear",
beta=0.1, #beta is ORPO's lambda
max_length=1024,
)
trainer = ORPOTrainer(
model=model,
train_dataset=dataset[0],
eval_dataset=dataset[1],
peft_config=peft_config,
args=orpo_config,
tokenizer=tokenizer,
)
trainer.train()ORPOTrainer is different from SFTTrainer and DPOTrainer in the sense that it doesn't seem to accept TrainingArguments as args. I needed to pass it an "ORPOConfig" which has slightly different arguments. Note: The "beta" mentioned in the ORPOConfig is the "lambda" described in the paper and which weighs the OR loss.
I only train for 100 steps. I used the new L4 GPU of Google Colab which is 4 times faster than the T4 but it still takes more than 9 hours. However, most of this time is actually for running validation. ultrafeedback's validation split is quite large. You might want to increase eval_steps and only use a subset of the validation set.
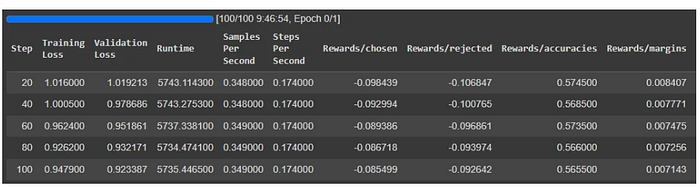
The training and validation losses both decrease. The model is learning. As for the other columns, we would like the margins and accuracies to increase. This is not the case here.
Let's look again at the learning curves of ORPO from the paper:
It is clear from the curves that it takes thousands of training steps for ORPO to learn how to discriminate the chosen from the rejected responses. To obtain similar results, we should train ORPO for at least 2,000 steps with a total batch size of 64 (as in the paper). Using one high-end consumer GPU, e.g., an RTX 4090, it is feasible but it would take several days.
Conclusion
ORPO is a new method for fine-tuning and aligning instruct LLMs in a single step. It doesn't require any reward or SFT model. ORPO is simpler than DPO and RLHF.
According to the paper, ORPO performs on par with DPO or slightly better. However, it takes several thousand training steps for ORPO to learn the difference between the good and the bad responses. This is intuitive since the model needs to learn first how to answer instructions, which is normally done with the SFT step of DPO and RLHF.
Should you use ORPO from now on?
If you want a simple and effective method, I recommend ORPO. However, if you want the best results, it's unclear whether you should use ORPO.
I think we are still missing a full comparison with all the other methods proposed for preference optimization. The paper compared ORPO with RLHF and DPO, but it is unclear how good ORPO is compared with more recent methods such as KTO and IPO.
To support my work, consider subscribing to my newsletter for more articles/tutorials on recent advances in AI: