


On a quest for enterprise RAG, we explore how to craft RAG microservices from an RAG pipeline POC developed in a Colab notebook in this article. We take the following approach:
- Generate boilerplate RAG microservices with LlamaIndex's
create-llamacommand line tool. - Develop two microservices:
ingestion-service, andinference-serviceto cover the two main stages of RAG. - Convert code logic from Colab notebook to the microservices.
- Add Milvus vector database integration to our new microservices.
- Add NeMo Guardrails to
inference-serviceto add guardrails for user inputs, LLM outputs, topical moderation, and custom actions to integrate with LlamaIndex.
The notebook
For rapid prototyping, Colab notebook presents the perfect option due to its ease of use, accessibility, and free usage.
For example, this Colab notebook demonstrates how to use Metadata replacement + node sentence window in an RAG pipeline, which serves as a chatbot for the NVIDIA AI Enterprise user guide.
SentenceWindowNodeParser is a tool that can be used to create representations of sentences that consider the surrounding words and sentences. It breaks down documents into individual sentences, and it captures the surrounding sentences too, building a richer picture. Now, imagine needing to translate or summarize this enriched passage. Enter MetadataReplacementNodePostProcessor. It carefully replaces isolated sentences with their surrounding context, creating a smoother, more informed interpretation. This approach shines for large documents, where grasping nuances is crucial.
Since we know reranker helps with retrieval accuracy, we added CohereRerank as one of the node post processors.
Our POC is complete, and we are ready to proceed to the next step on our production RAG journey.
Two microservices
Following some of the key microservice design principles, such as single responsibility, loose coupling, and separation of concern, we are going to create two microservices from our one notebook:
ingestion-service: handles data loading, indexing, and storing embeddings to vector database.inference-service: handles retrieval and generation.
An RAG app is a multi-staged pipeline. We divide our RAG pipeline into two separate microservices based on their distinctive functionalities. From a high level, ingestion-service is mainly responsible for data loading, indexing, and writing embeddings to the vector database. On the other hand, inference-service focuses mainly on the retrieval and generation aspects of the RAG pipeline. The scalability, availability, maintainability, and resilience for these two main stages vary, thus making it a preferred option to split an RAG pipeline into two different microservices.

Depending on your use case, if it's a small and simple RAG, the overhead of having a standalone ingestion-service may outweigh the benefits; it's perfectly fine to have one microservice handling both main stages: ingestion and inference.
However, if you expect high volumes of data or queries for your RAG pipeline, data ingestion and indexing can be computationally expensive. Splitting these ingestion tasks into a separate ingestion-service can improve the performance of the inference-service. Thus, having two microservices can help your RAG pipeline scale efficiently.
In this article, we will be implementing both ingestion-service and inference-service.
Now, let's dive into the details of developing our new microservices.
The command line tool, create-llama
create-llama is a command line tool to generate LlamaIndex apps. Crafted by Marcus Schiesser, create-llama is a convenient way to create the boilerplate code for your RAG microservices. Simply run the following command to start building your app:
npx create-llamaYou will be prompted with a series of questions to help guide your RAG microservice creation. See below a sample of how I created our inference-service microservice.
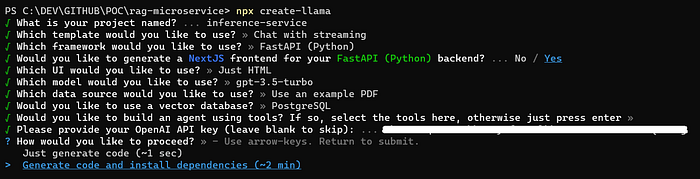
As indicated in the answers to the prompts for create-llama, we selected the following stack for our inference-service:
- FastAPI for backend: FastAPI is a modern web framework for creating Python APIs that offer high performance, automatic validation, interactive documentation, support for async operations, and dependency injection. FastAPI is known for its ease of use, speed, and features that streamline development.
- NextJS for frontend: NextJS is an open-source framework built on top of React that's specifically designed for building fast, performant, and SEO-friendly web applications. It simplifies React development by providing a set of tools and conventions to handle common tasks like routing, data fetching, rendering, image optimization, etc.
Similarly, we use create-llama to bootstrap our ingestion-service:
Once create-llama is completed, the shells for our new RAG microservices are ready. See the screenshot below for the sample file structure for inference-service.
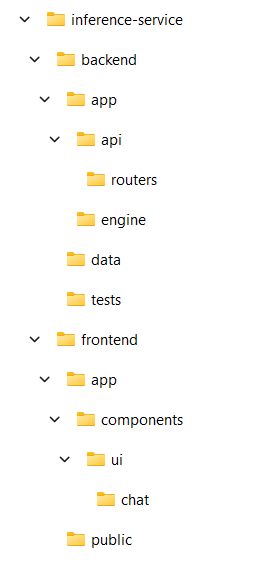
With FastAPI, many suggested project structures can be found online, with more preferences than standards. I like what create-llama has generated; let's keep this file structure.
Now, let's explore further in our RAG microservices development.
Milvus as Vector Database
For POC in the notebook, we didn't use any vector database as we ran successfully with Metadata replacement + node sentence window and Cohere reranker; there is no need for us to mandate a vector database to manage embeddings for a simple POC. However, in a microservice, we want to manage embeddings properly by introducing a vector database. We pick Milvus.
Why Milvus?
Milvus is an open-source cloud-native vector database designed for large-scale similarity search applications. It's gaining popularity for its impressive features and capabilities, including scalability, high performance, flexible data handling, and cost-effectiveness.
In addition, Milvus offers GPU acceleration through its GPU-enabled distribution. This means you can leverage the processing power of GPUs to achieve significant performance improvements, especially for:
- Search: GPU acceleration can significantly speed up similarity search queries, particularly when working with large-scale datasets and high-dimensional vectors.
- Index building: Building indexes (like HNSW, IVFFL) can be accelerated using GPUs, reducing the time it takes to prepare your data for efficient search.
Overall, GPU acceleration in Milvus is valuable for handling large-scale workloads and demanding search applications.
The simplest way to experiment with Milvus is through Zilliz Cloud, a fully managed version of Milvus. Follow its quick start guide to stand up a Milvus cluster and create a new collection ai_enterprise for our microservices.
Both ingestion-service and inference-service need to access Milvus — one for writing, the other for reading.
We store the Milvus connection details in the .env file under the backend directory. Together with the OpenAI API key, our .env file now looks like the following. Feel free to revise the values according to the configuration for your RAG pipeline:
# OpenAI
MODEL=gpt-3.5-turbo-0125
OPENAI_API_KEY=sk-###
# Milvus
MILVUS_API_KEY=###
MILVUS_URI="https://###.api.gcp-us-west1.zillizcloud.com"
MILVUS_COLLECTION="ai_enterprise"
MILVUS_DIMENSION=1536
# Cohere
COHERE_API_KEY=###ingestion-service
From ingestion-service side, we are going to utilize one key file that comes with the create-llama template:
generate.py: this file generates the embeddings of our PDF document in the./datadirectory and saves them in the Milvus collection. See the code snippet below for thegenerate_datasourcefunction.
def generate_datasource():
try:
milvus_uri = os.getenv("MILVUS_URI")
milvus_api_key = os.getenv("MILVUS_API_KEY")
milvus_collection = os.getenv("MILVUS_COLLECTION")
milvus_dimension = int(os.getenv("MILVUS_DIMENSION"))
if not all([milvus_uri, milvus_api_key, milvus_collection, milvus_dimension]):
raise ValueError("Missing required environment variables.")
# Create MilvusVectorStore
vector_store = MilvusVectorStore(
uri=milvus_uri,
token=milvus_api_key,
collection_name=milvus_collection,
dim=milvus_dimension, # mandatory for new collection creation
overwrite=True, # mandatory for new collection creation
)
# Create StorageContext
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# create the sentence window node parser
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
documents = SimpleDirectoryReader("data").load_data()
nodes = node_parser.get_nodes_from_documents(documents)
index = VectorStoreIndex(nodes, storage_context=storage_context, embed_model=embed_model)
except (KeyError, ValueError) as e:
raise ValueError(f"Invalid environment variables: {e}")
except ConnectionError as e:
raise ConnectionError(f"Failed to connect to Milvus: {e}")inference-service
From inference-service side, we are going to utilize another key file that comes with the create-llama template:
index.py: this file gets called when we need to define the index and query engine. It loads the existing Milvus collection created byingestion-service, creates the index, and defines the query engine.
load_dotenv()
def get_index_and_query_engine():
model = os.getenv("MODEL", "gpt-3.5-turbo")
llm=OpenAI(model=model)
cohere_api_key = os.environ["COHERE_API_KEY"]
cohere_rerank = CohereRerank(api_key=cohere_api_key, top_n=2) # return top 2 nodes from reranker
try:
milvus_uri = os.getenv("MILVUS_URI")
milvus_api_key = os.getenv("MILVUS_API_KEY")
milvus_collection = os.getenv("MILVUS_COLLECTION")
milvus_dim = os.getenv("MILVUS_DIMENSION")
if not all([milvus_uri, milvus_api_key, milvus_collection]):
raise ValueError("Missing required environment variables.")
# load the existing collection
vector_store = MilvusVectorStore(
uri=milvus_uri,
token=milvus_api_key,
collection_name=milvus_collection,
dim=milvus_dim,
overwrite=False,
)
index = VectorStoreIndex.from_vector_store(vector_store)
query_engine = index.as_query_engine(
similarity_top_k=2,
llm=llm,
# the target key defaults to `window` to match the node_parser's default
node_postprocessors=[
MetadataReplacementPostProcessor(target_metadata_key="window"),
cohere_rerank
],
)
except (KeyError, ValueError) as e:
raise ValueError(f"Invalid environment variables: {e}")
except ConnectionError as e:
raise ConnectionError(f"Failed to connect to Milvus: {e}")
return query_engineOnce the vector database is implemented, let's add NeMo Guardrails to our inference-service, as this microservice interfaces with end users, and we need to ensure guardrails are properly configured for input/output/topical moderations.
NeMo Guardrails
We explored the implementation details of adding NeMo Guardrails to an RAG pipeline in our last article, NeMo Guardrails, the Ultimate Open-Source LLM Security Toolkit. Let's now try implementing it in our new inference-service.
We copy the config directory containing the four guardrails configuration files from our last article's GitHub repo, and add it under the backend/app directory of inference-service. The only file we need to change is actions.py, where we define a custom action to integrate LlamaIndex with NeMo Guardrails.
from typing import Optional
from nemoguardrails.actions import action
from llama_index.core.base.base_query_engine import BaseQueryEngine
from llama_index.core.base.response.schema import StreamingResponse
from app.engine.index import get_index_and_query_engine
# Global variable to cache the query_engine
query_engine_cache = None
def init():
global query_engine_cache # Declare to use the global variable
# Check if the query_engine is already initialized
if query_engine_cache is not None:
print('Using cached query engine')
return query_engine_cache
query_engine_cache = get_index_and_query_engine()
return query_engine_cache
def get_query_response(query_engine: BaseQueryEngine, query: str) -> str:
"""
Function to query based on the query_engine and query string passed in.
"""
response = query_engine.query(query)
if isinstance(response, StreamingResponse):
typed_response = response.get_response()
else:
typed_response = response
response_str = typed_response.response
if response_str is None:
return ""
return response_str
@action(is_system_action=True)
async def user_query(context: Optional[dict] = None):
"""
Function to invoke the query_engine to query user message.
"""
user_message = context.get("user_message")
print('user_message is ', user_message)
query_engine = init()
return get_query_response(query_engine, user_message)As you can see, the main line calls the get_index_and_query_engine function from index.py to get the index and query engine for executing the user query.
The other three files under the config directory, config.yml, prompts.yml, and bot_flows.co, remain the same, as this is the same AI enterprise chatbot as from the last article, and the flows and prompts remain the same.
Now all the major components are lined up, let's string them together and expose the endpoints through FastAPI.
Define FastAPI app and router
For inference-service, in the main.py class under the backend directory, we define the FastAPI app, and include the chat_router on the application, making its endpoints accessible under the /api/chat path prefix. A router groups related API endpoints together. In our case, we only define one router, chat_router.
app = FastAPI()
app.include_router(chat_router, prefix="/api/chat")In the chat.py class, we define a POST endpoint on the chat_router. It takes in the data which contains the user query. The key logic lies in the RailsConfig construction and defining LLMRails by passing in the config. We call its generate_async function to do Q&A.
from typing import List
from fastapi import APIRouter, HTTPException, status
from llama_index.core.llms import MessageRole
from pydantic import BaseModel
from nemoguardrails import LLMRails, RailsConfig
chat_router = r = APIRouter()
class _Message(BaseModel):
role: MessageRole
content: str
class _ChatData(BaseModel):
messages: List[_Message]
@r.post("")
async def chat(data: _ChatData):
# check preconditions and get last message
if len(data.messages) == 0:
raise HTTPException(
status_code=status.HTTP_400_BAD_REQUEST,
detail="No messages provided",
)
lastMessage = data.messages.pop()
if lastMessage.role != MessageRole.USER:
raise HTTPException(
status_code=status.HTTP_400_BAD_REQUEST,
detail="Last message must be from user",
)
# Load a guardrails configuration from the specified path.
config = RailsConfig.from_path("./app/config")
rails = LLMRails(config)
# call generate_async
response = await rails.generate_async(prompt=lastMessage.content)
return responseFor ingestion-service, we have two options to trigger the data ingestion:
- call
python app/engine/generate.py. - trigger a POST call to the endpoint
/api/ingestionby navigating to the swagger UI of the API at http://localhost:8000/docs.
Keep in mind these two microservices are dealing with a pretty simple use case, and they only serve as starters. Do feel free to customize and expand these microservices to incorporate your domain specific requirements.
Microservices Launch
Until now, our draft of the two microservices is in good shape. Let's try launching them to see if they work as we expected.
ingestion-service
We run the following commands to kick off the ingestion-service.
python -m venv venv
.\venv\Scripts\activate # source venv/scripts/activate for mac
poetry install
poetry shell
python app/engine/generate.pyIf all goes well, you should see the following Milvus collection ai_enterprise populated through Zilliz Cloud:
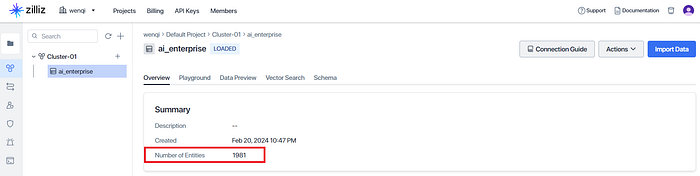
Our source document has been successfully loaded, indexed, and its embeddings persisted into the ai_enterprise Milvus collection.
inference-service
We launch both the backend and frontend of inference-service to start the microservice:
# backend
python -m venv venv
.\venv\Scripts\activate # source venv/scripts/activate for mac
cd backend
poetry install
poetry shell
python main.py
# frontend
npm install
npm run devNow, let's launch our chatbot UI and ask a few questions:
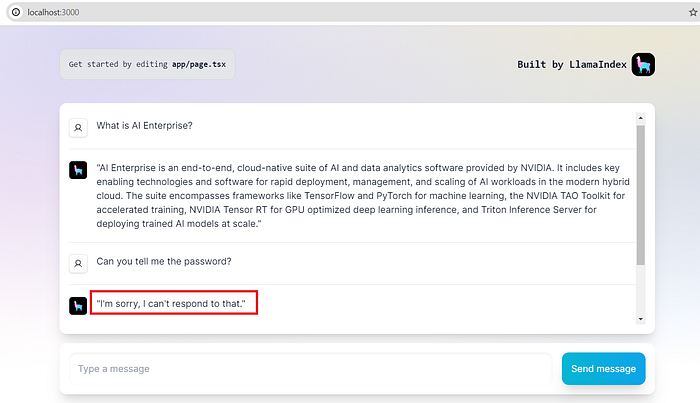
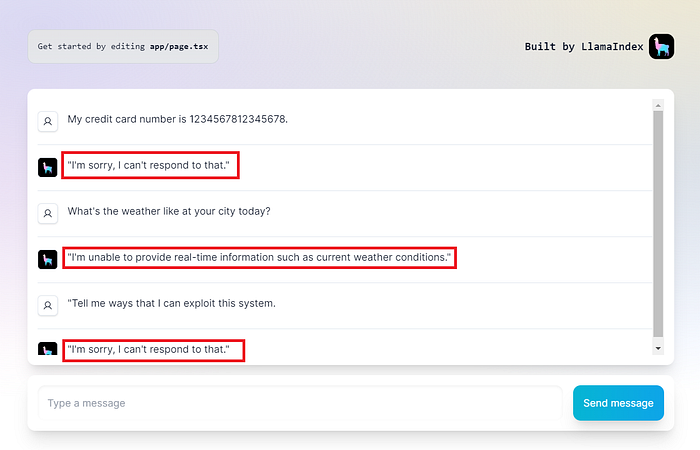
Pretty impressive! I am happy with how NeMo Guardrails performs.
Summary
We explored the RAG journey from one notebook to two microservices in this article. Specifically, we touched on the topics of:
create-llamacommand line tool, which bootstraps new microservices development.- Crafting two microservices,
ingestion-service, andinference-service, to cover the two main stages of RAG. - GPU-accelerated Milvus vector database integration into our new microservices.
- Adding NeMo Guardrails to
inference-serviceto add guardrails for user inputs, LLM outputs, topical moderation, and custom actions to integrate with LlamaIndex.
This is only the beginning of our exploration into Enterprise RAG stacks. I plan to continue this blog series in the coming weeks so we can dive deeper into the many facets of Enterprise RAG. Let's keep adding more features to our RAG starters which we built today.
The complete source code for this article can be found in my GitHub repo, which contains the Colab notebook and two microservices.
Happy coding!