

In recent years, Deep Learning has made remarkable progress in the field of NLP.
Time series, also sequential in nature, raise the question: what happens if we bring the full power of pretrained transformers to time-series forecasting?
However, some papers, such as [2] and [3] have scrutinized Deep Learning models. These papers do not present the full picture. Even for NLP cases, some people attribute the breakthrough of GPT models to "more data and computing power" instead of "better ML research".
This article aims to clear the confusion and provide an unbiased view, using reliable data and sources from both academia and industry. Specifically, we will cover:
- The pros and cons of Deep Learning and Statistical Models.
- When to use Statistical models and when Deep Learning.
- How to approach a forecasting case.
- How to save time and money by selecting the best model for your case and dataset.
Let's dive in.
If you are interested in Time-Series Forecasting, check my list of the Best Deep Learning Forecasting Models.
Makridakis et al. Paper [4]
We can't discuss the progress of different forecasting models without considering the insights gained from Makridakis competitions (M competitions).
Makridakis competitions are a series of large-scale challenges that demonstrate the latest advancements in time-series forecasting.
Recently, Makridakis et al. published a new paper that:
- Summarizes the current state of forecasting from the first 5 M-competitions.
- Provides an extensive benchmark of various statistical, machine learning, and deep learning forecasting models.
Note: We will discuss the limitations of the paper later in this article.
Benchmark Setup
Traditionally, Makridakis and his associates release a paper summarizing the results of the last M-competition.
For the first time, however, the authors have included Deep Learning models in their experiments. Why?
Unlike NLP, it was only in 2018–2019 that the first DL forecasting models were mature enough to challenge traditional forecasting models. In fact, during the M4 competition in 2018, the ML/DL models ranked last.

Now, let's see the DL/ML models that were used in the new paper:
- Multi-layer Perceptron (MLP): Our familiar feed-forward network.
- WaveNet: An autoregressive neural network that combines convolutional layers (2016).
- Transformer: The original Transformer, introduced in 2017.
- DeepAR: Amazon's first successful auto-regressive network that combines LSTMs (2017)
Note: The Deep Learning models are not SOTA (state-of-the-art) anymore (more to that later). Also MLP is considered an ML and not a "deep" model.
The statistical models of the benchmark are ARIMA and ETS (Exponential Smoothing) — well-known & battle-tested models.
Moreover:
- The ML/DL models were fine-tuned first through hyper-parameter tuning.
- The statistical models are trained in a series-by-series fashion. Conversely, the DL models are global (a single model trained on all time series of the dataset). Hence, they take advantage of cross-learning.
- The authors used ensembling: An Ensemble-DL model was created from Deep Learning models, and an Ensemble-S, consisting of statistical models. The ensembling method was the median of forecasts.
- The Ensemble-DL consists of 200 models, with 50 models from each category: DeepAR, Transformer, WaveNet, and MLP.
- The study utilized the M3 dataset: First, the authors tested 1,045 time series, and then the full dataset (3,003 series).
- The authors measured forecasting accuracy using MASE (Mean Absolute Scaled Error) and SMAPE (Mean Absolute Percentage Error). These error metrics are commonly used in forecasting.
Next, we provide a summary of the results and conclusions obtained from the benchmark.
1. Deep Learning Models are Better
The authors conclude that on average, DL models outperform the statistical ones. The result is shown in Figure 2:

The Ensemble-DL model clearly outperforms the Ensemble-S. Also, DeepAR achieves very similar results with Ensemble-S.
Interestingly, Figure 2 shows that although Ensemble-DL outperforms Ensemble-S, only DeepAR beats the individual statistical models. Why is that?
We will answer that question later in the article.
2. But, Deep Learning Models Are Expensive
Deep Learning models require a lot of time to train (and money). This is expected. The results are shown in Figure 3:

The computational difference is significant.
Hence, lowering the forecasting error by 10% requires an extra computational time of about 15 days(Ensemble-DL). While this number seems enormous, there are some things to consider:
- The authors do not specify what type of hardware they used.
- They also don't mention if any parallelization or training optimization is used.
- The computational time of Ensemble-DL can be significantly reduced if fewer models are used in the ensemble. This is displayed in Figure 4:

I mentioned previously that the Ensemble-DL model is an ensemble of 200 DL models.
Figure 4 shows that 75 models can achieve comparable accuracy to 200 models with only one-third of the computational cost. This number can be further reduced if a more clever method to do the ensemble is used.
Finally, the current paper does not explore the transfer-learning capabilities of Deep Learning models. We will also discuss that later.
3. Ensembling is All You Need
The power of ensembling is indisputable (Figure 2, Figure 3).
Both Ensemble-DL and Ensemble-SL are the top-performing models. The idea is that each individual model excels at capturing different temporal dynamics. Combining their predictions enables the identification of complex patterns and accurate extrapolation.
4. Short-term vs Long-Term Forecasting
The authors investigated whether there is a difference in models' ability to forecast in the short-term versus the long-term.
There was indeed.
Figure 5 breaks down the accuracy of each model for each forecasting horizon. For example, column 1 displays the one-step ahead forecast error. Similarly, column 18 displays the error of the 18th step-ahead forecast.
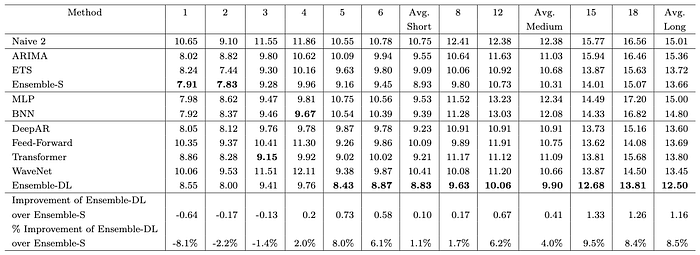
There are 3 key observations here:
- First, long-term forecasts are less accurate than short-term ones (no surprise here).
- In the first 4 horizons, statistical models win. Beyond that, Deep Learning models start becoming better and Ensemble-DL wins.
- Specifically, in the first horizon, Ensemble-S is 8.1% more accurate. However, in the last horizon, Ensemble-DL is 8.5% more accurate.
If you think about this, it makes sense:
- Statistical models are auto-regressive. As the forecasting horizons increase, the errors accumulate.
- In contrast, deep learning models are multi-output models. Hence, their forecasting errors are distributed across the entire prediction sequence.
- The only DL autoregressive model is DeepAR. That's why DeepAR performs very well in the first horizons contrary to the other DL models.
5. Do Deep Learning Models improve with more data?
In the previous experiment, the authors used just 1,045 time series from the M3 dataset.
Next, the authors re-run their experiment using the full dataset (3,003 series). They also analyzed the forecasting losses per horizon. The results are shown in Figure 6:

Now, the gap between Ensemble-DL and Ensemble-S narrowed. The statistical models matched the deep learning models in the first horizon, but after that, the Ensemble-DL outperformed them.
Let's further analyze the differences between Ensemble-DL and Ensemble-S:

As the prediction step increases, Deep Learning models outperform the statistical ensemble.
6. On Trend and Seasonality Analysis
Finally, the authors investigate how statistical and DL models handle important time series characteristics like trend and seasonality.
To achieve this, the authors used the methodology by [5]. Specifically, they fitted a multiple linear regression model that correlated sMAPE error with 5 key time series characteristics: forecastability(randomness of errors), trend, seasonality, linearity, and stability(optimal Box-Cox parameter transformation that decides data normality). The results are shown in Figure 8:

We observe that:
- DL models perform better with noisy, trended, and non-linear data.
- Statistical models are more appropriate for seasonal & low-variance data with linear relationships.
These insights are invaluable.
Hence, it is crucial to conduct extensive exploratory data analysis (EDA) and understand the nature of the data before selecting the appropriate model for your use case.
Study's Limitations
This paper is undoubtedly one of the best studies on the current state of the time-series forecasting landscape, yet it has some limitations. Let's examine them:
Lack of ML algorithms: Trees / Boosted Trees
The family of Boosted Trees models has a significant place in time series forecasting problems.
The most popular ones are XGBoost, LightGBM, and CatBoost. Besides, LightGBM won the M5 competition.
These models excel with tabular-like data. In fact, to this day, Boosted Trees are the best choice for tabular data. However, the M3 dataset used in this study is simple as it mostly contains univariate series.
In a future study, it would be a great idea to add Boosted Trees to the dataset, especially for more complex datasets.
Choosing M3 as the Benchmark Dataset
Professor Rob Hyndman, Editor-in-Chief of the IJF journal said: "The M3 dataset has been used since 2000 for testing forecasting methods; newly proposed methods must beat M3 to be published in IJF."
However, by modern standards, the M3 dataset is considered small and simple, and therefore not indicative of modern forecasting applications and practical scenarios.
Of course, the choice of the dataset does not diminish the value of the study. Nevertheless, conducting a future benchmark with a larger dataset could provide valuable insights.
The Deep Learning Models are not SOTA
Now, it's time to address the elephant in the room.
The Deep Learning models of the study are far from being state-of-the-art.
The study identified Amazon's DeepAR as the best DL model in terms of theoretical forecasting accuracy. That's why, DeepAR was the only model capable of outperforming the statistical models on an individual level. However, the DeepAR model is now more than 6 years old.
Amazon has since released its improved version of DeepAR, called Deep GPVAR. In fact, Deep GPVAR is also outdated — Amazon's latest Deep forecasting model is the MQTransformer, which was published in 2020.
Moreover, other powerful models like Temporal Fusion Transformer (TFT) and N-BEATS (which was recently outperformed by N-HITS) are also not used in the Deep Learning ensemble.
Therefore, the deep learning models used in the study are at least two generations behind the current state of the art. Undoubtedly, the current generation of deep forecasting models would have produced much better results.
Forecasting is not Everything
Accuracy is essential in forecasting, but it's not the only important factor. Other critical areas are:
- Uncertainty quantification
- Forecast interpretability
- Zero-Shot Learning / Meta-Learning
- Regime Shift Segregation
Speaking of Zero-Shot Learning, it's one of the most promising areas in AI.
Zero-shot learning is a model's ability to correctly estimate unseen data, without being specifically trained on them. This learning method better reflects the human perception.
All Deep Learning models, including the GPT models, are based on this principle.
The first well-acclaimed forecasting models that leverage this principle are N-BEATS / N-HITS. These models can be trained on a vast time-series dataset and produce forecasts on completely novel data with similar accuracy as if the models had been explicitly trained on them.
Zero-shot learning is just a specific instance of meta-learning. Further progress with meta-learning on time-series has been made since. Take the M6 competition for example, whose goal was to find if data science forecasting & econometrics can be used to beat the market, like legendary investors do (e.g. Warren Buffet). The winning solution was a novel architecture that used, among other, neural networks and meta-learning.
Unfortunately, this study does not explore the competitive advantage of Deep Learning models in a zero-shot learning setup.
The Nixtla Study
Nixtla, a promising start-up in the field of time-series forecasting, recently published a benchmark follow-up to the Makridakis et al. paper [4].
Specifically, the Nixtla team added 2 additional models: Complex Exponential Smoothing and Dynamic Optimized Theta.
The addition of these models reduced the gap between statistical and deep learning models. Furthermore, the Nixtla team correctly pointed out the significant difference in cost and resources required between the two categories.
Indeed, many data scientists are misled by the overhyped promises of Deep Learning and lack the proper approach to solving a forecasting problem.
We will discuss this further in the next section. But before that, we need to address the criticism that Deep Learning faces.
Deep Learning Under Fire
The progress of Deep Learning during the past decade is phenomenal. And there are no signs yet of slowing down.
However, every revolutionary breakthrough that threatens to change the status quo is often met with skepticism and criticism. Take GPT-4 for example: this new development threatens 20% of US jobs in the next decade [6].
The dominance of Deep Learning and Transformers in the field of NLP is undeniable. And yet, people in interviews ask questions that go something like this:
Are the advances in NLP attributed to better research, or simply to the availability of more data and increased computer power?
In time-series forecasting, things are worse. To understand the reason behind this, you must first comprehend how forecasting problems were traditionally tackled.
Before the widespread adoption of ML/DL, forecasting was all about crafting the right transformations for your dataset. This entailed making the time-series stationary, removing trends and seasonalities, accounting for volatility, and using techniques like box-cox transformations, among others. All of these approaches required manual intervention and a deep understanding of mathematics and time series.
With the advent of ML, time-series algorithms became more automated. You can readily apply them to time-series problems with little to no preprocessing aside from cleaning (although additional preprocessing and feature engineering always help). Nowadays, much of the improvement effort on such a project is limited to hyperparameter tuning.
Therefore, people who used advanced maths & statistics cannot grasp the fact that an ML/DL algorithm can outperform a traditional statistical model. And the funny thing is, researchers have no idea how and why some DL concepts truly work.
Time-Series Forecasting in Recent Literature
As far as I know, the current literature lacks sufficient evidence to illustrate the advantages and disadvantages of various categories of forecasting models. The 2 papers below are the most relevant:
Are Transformers Effective for Time Series Forecasting?
One interesting paper [2] displays the weaknesses of some forecasting Transformers models. The paper explains for example how positional encoding schemes, used in modern Transformer models fail to capture the temporal dynamics of time sequences. This is true — self-attention is permutation-invariant. However, the paper fails to mention the Transformer models that have effectively addressed this issue.
For example, Google's Temporal Fusion Transformer (TFT) uses an encoder-decoder LSTM layer to create time-aware and context-aware embeddings. Also, TFT uses a novel attention mechanism, adapted for time-series problems to capture temporal dynamics and provide interpretability.
Similarly, Amazon's MQTransformer uses its novel positional encoding scheme (context-dependent seasonality encoding) and attention mechanism (feedback-aware attention).
Do We Really Need DL Models for Time Series Forecasting?
This paper [3] is also interesting as it compares various forecasting methods across statistical, Boosted Trees, ML, and DL categories.
Unfortunately, it falls short of its title, as the best model among the 12 models is Google's TFT, a pure Deep Learning model. The paper mentions:
… The results in Table 5 above underline the competitiveness of the rolling forecast configured GBRT, but also show that considerably stronger transformer-based models, such as the TFT [12], rightfully surpass the boosted regression tree performance..
In general, be cautious when reading sophisticated forecasting papers and models, particularly regarding the source of publication. The International Journal of Forecasting (IJF) is an example of a reputable journal focusing on forecasting.
How to Approach a Forecasting Problem
This is not simple. Each dataset is unique, and the objectives of each project vary, making forecasting challenging.
Nevertheless, this article offers general advice that may be beneficial for most approaches.
As you have learned from this article, Deep Learning models are an emerging trend in forecasting projects, but they are still in their early stages. Despite their potential, they can also be a pitfall.
It is not recommended to prioritize Deep Learning models for your project right away. According to Makridakis et al. and Nixtla's studies, it is best to start with statistical models. An ensemble of 3–4 statistical models may be more powerful than you expect. Also, give boosted trees a try, especially if you have tabular data. For small datasets (in the order of thousands), these methods may be adequate.
Deep Learning models may provide an additional 3–10% accuracy boost. However, training these models can be time-consuming and expensive. For some fields, such as finance and retail, that extra accuracy boost may be more beneficial and justify using a DL model. A more accurate product sales prediction or an ETF's closing price might translate to thousands of dollars in incremental revenue.
On the other hand, DL models like N-BEATS and N-HITS have transfer-learning capabilities.
If a large enough time-series dataset is constructed, and a willing entity pre-trains those 2 models and shares their parameters, we could readily use these models and achieve top-notch forecasting accuracy (or perform a small fine-tuning to our dataset first).
Closing Remarks
Time-series forecasting is a key area of Data Science.
But it's also very undervalued compared to other areas. The Makridakis et al. paper[4] provided some valuable insights for the future, but there is still a lot of work and research to be done.
On top of that, DL models in forecasting are largely unexplored.
For example, Multi-Modal architecures in Deep-Leaning are everywhere. These architectures leverage more than one domain to learn a specific task. For instance, CLIP (used by DALLE-2 and Stable Diffusion) combines Natural Language Processing and Computer Vision.
The benchmark M3 dataset contains only 3,003 time series, each with no more than 500 observations. In contrast, the successful Deep GPVAR forecasting model consists of an average of 44K parameters. In comparison, the smallest version of Facebook's LLaMA language Transformer model has 7 billion parameters and was trained on 1 trillion tokens.
So, regarding the original question, there is no definitive answer as to which model is the best since each model has its own advantages and shortcomings.
Instead, this article aims to provide all the necessary information to help you select the most suitable model for your project or case.
Thank you for reading!
- Subscribe to my newsletter!
- Follow me on Linkedin!
References
[1] Created from Stable Diffusion with the text prompt "a blue cyan time-series abstract, shiny, digital painting, concept art"
[2] Ailing Zeng et al. Are Transformers Effective for Time Series Forecasting? (August 2022)
[3] Shereen Elsayed et al. Do We Really Need Deep Learning Models for Time Series Forecasting? (October 2021)
[4] Makridakis et al. Statistical, machine learning and deep learning forecasting methods: Comparisons and ways forward (August 2022)
[5] Kang et al. Visualising forecasting algorithm performance using time series instance spaces (International Journal of Forecasting, 2017)
[6] Eloundou et al. GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models (March 2023)
All images used in the article are from [4]. The M3 dataset as well as all M-datasets "are free to use without further permission by the IIF".