

What is attention?
In any autoregressive model, the prediction of the future tokens is based on some preceding context. However, not all the tokens within this context equally contribute to the prediction, because some tokens might be more relevant than others. The attention mechanism addresses this by allowing the model to concentrate on the important context words selectively, while generating each output word or token. Consider the popular example that explains the attention mechanism.
"The animal didn't cross the street because it was too tired".
In this sentence, the pronoun "it" could refer to either "animal" or "street". Attention helps the model to associate "it" with "animal" rather than "street" by weighing the relative importance of each word. This helps the model to understand the relationships between words and capture the contextual meaning in various NLP tasks.
How is attention calculated?
There are various types of attention mechanisms today, beginning with the Multi-Head Attention (MHA), which introduced the attention concept in the seminal paper. More recently, advanced variants like Multi-Latent Head Attention (MHLA) have been employed in popular models like Deepseek. This blog aims to cover the fundamentals of each attention mechanism, including the core ideas, advantages, limitations, etc.
Key Concepts in Attention Mechanisms
Before diving into specific types of attention, we need to understand some fundamental concepts that underpin all the various attention mechanisms.
The main idea behind the attention mechanism is to dynamically weigh, and focus on relevant parts of inputs. Attention is required in both the encoding and decoding stages. But in this blog, we will be discussing this from a decoder's point of view.
During each generation step, we need to understand the attention weights, which help us to get a better contextual representation for the next word prediction. At its core, attention operates through three fundamental components — queries, keys, and values — that work together with attention scores to create a flexible, context-aware vector representation.
- Query (Q): The query is a vector that represents the current token for which the model wants to compute attention.
- Key (K): Keys are vectors that represent the elements in the context against which the query is compared, to determine the relevance.
- Attention Scores: These are computed using Query and Key vectors to determine the amount of attention to be paid to each context token.
- Value (V): Values are the vectors that represent the actual contextual information. After calculating the attention scores using Query and Key vectors, these scores are applied against Value vectors to get the final context vector
- KV Caching: Since the key and value vectors are for previous tokens, we can skip this computation for those tokens that are already calculated. KV caching stores the precomputed keys and values from the previous computations, which helps in faster decoding in autoregressive models by reusing the cached vectors. However, the Query vectors cannot be cached, since they are calculated for the current token.
To understand how each of these vectors are scores are calculated you can refer to this blog.
The high-level concepts remain consistent across all types of attention mechanisms. However, the key difference lies in how efficiently each of them executes the attention process without compromising on performance. Innovations focus on computational speed, reducing memory usage, improving scalability across longer sequences, etc.
Now, let's dive into each of these techniques
Multi-Head Attention (MHA)
In multi-head attention, for computing the attention weights for the ith token, first, a query vector is calculated for that token. To calculate the attention weights for the token, this query vector is compared with all the preceding tokens. For that, key vectors are calculated for all the preceding tokens. These comparisons will generate an attention score, which is then used to produce a weighted score for each token using the corresponding value vectors.
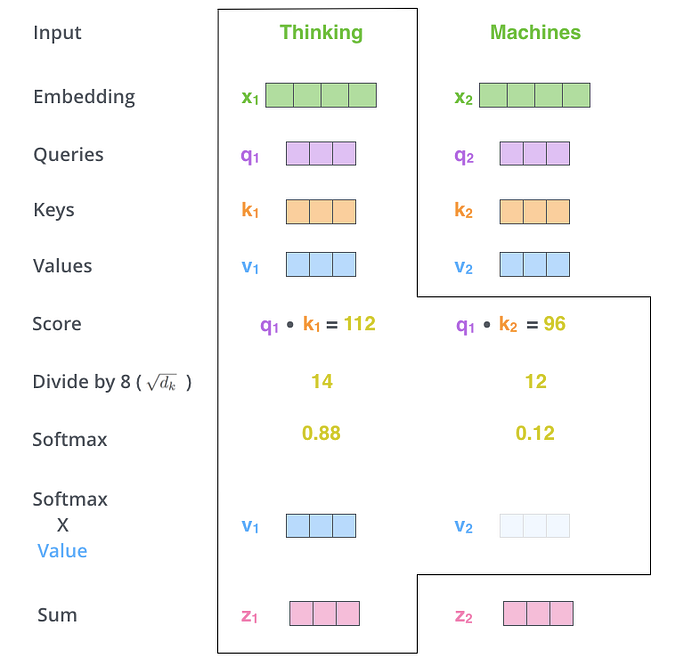
In multi-head attention, this process is repeated in parallel across multiple attention "heads". Each head has its own query, value, and key vectors, using which it calculates the relationship between the words. The final output context vector will be the concatenated output from all the attention heads.
Now, this seems straightforward. However, as the context grows, the number of Key and Value vectors will increase dramatically, because these vectors need to be calculated and stored for all the context tokens. For a sequence length of n, each query vector must be compared against all n key vectors and then perform the weighted combination using n value vectors. This results in a quadratic complexity in both computation and memory.
KV cache can help in reducing the computation and memory overhead during inference. But as the context grows, the size of the cache grows linearly with sequence length to store all the keys and values for all the preceding tokens. KV cache reduces the redundant computations, but will not reduce the fundamental cost of attending to all the previous tokens.
Models using MHA – Bert, RoBerta, T5, etc.
Multi-Query Attention (MQA)
A significant challenge with MHA was the high computational and memory overhead associated with storing and processing separate Key and Value vectors for each attention head.
MQA addresses this problem by using multiple query heads but sharing a common set of Key and Value vectors across all the heads. In other words, there are still "h" distinct Query projections using which the model attends the current token from multiple perspectives. But the same Key and Value vectors are used for every head.
This approach will greatly reduce the memory bandwidth requirements without significantly sacrificing the model performance. By sharing the Key and Value vectors, MQA enables an efficient inference, especially for Large language models with long context lengths.
Here, the Key and Value vectors need to be calculated only once for a token instead of "h" times, which reduces the computation cost of Key/Value projection. But note that for calculating the attention score, each query head is still multiplied by the Key vectors and then weighed using the Value vectors. So this remains the same.
Also, with MQA only one set of Key-Value pairs needs to be cached, regardless of the number of Query heads. This lets the KV cache size grow gradually as the sequence length grows, leading to much lower memory requirements when compared to MHA
Models using MQA – PaLM, Falcon
Grouped Query Attention (GQA)
Grouped Query attention offers a balance between the MHA and MQA. As we saw earlier, traditional MHA requires significant memory and computation overhead due to separate Key-Value vectors for each Query head, and the computation overhead even increases as the number of heads increases. MQA addresses this by having a shared Key-Value, which reduces the computation cost and memory, but it may impact the model performance.
GQA offers a compromise between these two extremes. Instead of having a common Key-Value for all the heads, GQA divides the Query heads into "g" groups and lets each group share a common Key and Value head. We can say, MHA and MQA come as two extreme cases of GQA, with g=1 leading to MQA and g=h leading to MHA. This approach reduces the memory and computational requirements compared to MHA while retaining a better performance than MQA.
Models using GQA – Llama2, Llama3, Mistral
Multi-Head Latent Attention (MHLA)
While GQA performs better than MQA, but still may not match MHA's performance in some complex tasks.
MHLA is a recent innovation in transformer architecture introduced in models like DeepSeek. Its main goal is to dramatically reduce memory usage and accelerate inference, especially for large language models (LLMs), without loss in model performance.
The idea is to attain a performance near MHA. So we need to consider separate Key value heads for each attention head, like in MHA, but also improve the inference speed by reducing the memory overhead for storing the large amounts of Key value vectors.
MHLA addresses the challenge of high memory usage and slow inference by compressing the Key and Value representations into a much smaller latent space using low-rank projections. Specifically, instead of storing the full Key and Value vectors for every token and head, MHLA applies a linear transformation that projects these vectors into a lower-dimensional space.
So during the inference:
- A down-projection weight matrix W(DKV) is introduced and is multiplied with the input sequence to obtain a compressed latent vector C(KV) for keys and Values. This latent vector is stored in cache, which is significantly smaller in size when compared to the full key and Value vectors
- This is then multiplied by an up-projection matrix W(UK) and W(UV) to get the Key and Value vectors
- Additionally, the matrix W(KR) is used to produce a decoupled Key that carries the Rotary Positional embedding
- Additionally, the same process is done for attention Queries as well, which will reduce the activation memory during training
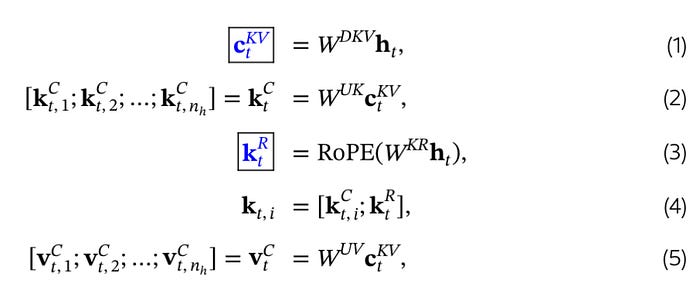
MHLA supports switching between two computation paradigms for different stages. During the training stage, which is computationally intensive, it operates similarly to MHA, where the computational overhead is slightly lower than conventional MHA. During inference, it can seamlessly switch to a paradigm similar to MQA. Here, the cached KV head interacts with all query heads to produce the final output.
Models using MHLA– Deepseek- V2, Deep seek V2
Conclusion
In addition to the topics discussed, there are various innovative methods that are designed to optimise the challenges of the traditional attention technique. Some of these include sparse attention, efficient attention, memory augmented attention, etc. These approaches reflect the focus on ongoing research for making the attention more scalable, faster, and adaptable across various tasks and requirements.
Thank you for reading this post! Let me know if you liked it, have questions, or spotted an error. Please feel free to contact or follow me through LinkedIn, Twitter, or Medium.