

With the trend of using increasingly more specialized prompts and LLMs for different applications, organizations need to be able to route user's queries to the most appropriate expert for a given use case. One example might be to offload coding tasks to Claude while using GPT 4o for general-purpose queries and Gemini for grounded responses. If we are to build such a system, we need a routing model that is fast, scalable, cost-effective, and responsive.
In this blog post, I'll look at building an LLM router using OpenAI's embedding model and compare it against the state-of-the-art alternative using ModernBERT. For more information about using ModernBERT for this application, check out this blog post from a technical lead in Hugging Face.
Context
A while back I wrote a blog post about building a state-of-the-art classifier using OpenAI embedding models and argued that they may be the most cost-effective way to do simple classification for many applications and organizations that need better cost, scalability, and potentially serverless serving and can benefit from something simpler than fine-tuning an LLM. I recently read a blog post from Philipp Schmid, a technical lead in Hugging Face, on using ModernBERT for an LLM routing use case, and I thought I'd compare it against my suggested platform. Both ways have their own merits, and AI engineers need to be able to understand these differences and pick the best option for a given application.
LLM Router
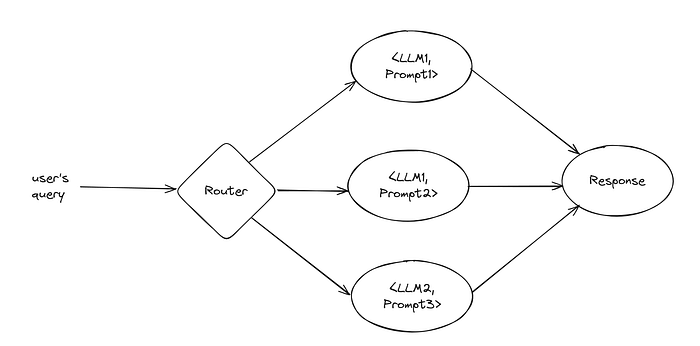
The LLM landscape expanded significantly in 2024, and the trend should continue in 2025. We now have access to multiple frontier LLMs from different organizations like OpenAI, Google, and Amazon along with open-weight models from DeepSeek, Mistral, or Meta. Each model seems to excel in some types of queries or have different cost-performance tradeoffs. For example, as of December 2024, Claude excels at coding, while GPT 4o-mini is a great general-purpose model, GPT 4-o is great at reasoning, and GPT o1 excels at tough scientific problems.
In parallel, using LLMs in production may require very detailed prompts to improve the results. With all of this, we need a way to route the user's query to the best LLM<>Prompt combination fit to serve that query. Here we'll go over a prototype of this, testing it on two different datasets: 1) DevQuasar/llm_router_dataset-synth which is a synthetic dataset to route simple queries to a small LLM (e.g., GPT 4o-mini) and more complex queries to a large LLM (e.g., GPT-4o); 2) legacy-datasets/banking77, a dataset comprising online banking queries, mapping them to one of 77 possible intent classes (e.g., card arrival, change pin).
Training Code
Most of the code is copied over from my previous blog post, so I won't repeat most of it. Our model is built in 2 steps:
- generate embeddings from raw text and store them in a CSV file.
- use the embeddings to train and evaluate a model.
Here is the code for the first step, I'm using OpenAI's text-embeding-3-large model for this experiment.
Here is the code for the second part, I used a very simple fully connected neural network, which might be enough for most use cases. I didn't tune the learning rate and other hyperparameters too much, so we definitely can squeeze some more performance out of the model by tuning them.
The Results
OK, now let's get to the results. I wanted to look at the wall time for training, estimated cost, number of parameters trained by us, and maintainability factors.
ModernBERT-Base: This model has 139M parameters, and the experiments cited were run on an Nvidia L4 GPU with 24GB VRAM (reference), this model would require us to use modern GPUs for both inference and training.
EmbeddingNet: This is the model generated from the code above, it has 61.5K parameters (excluding OpenAI embedding model weights, since it isn't trained or served by us) and thus doesn't need GPUs for training or inference. The model weights take only around 246KB and this should mean that the model is lightweight enough to even be served by serverless or edge workers.
Dataset #1: LLM Router
This dataset includes ~15K synthetic prompts and an LLM router label. For this dataset, EmbeddingNet took around 2–3 minutes to embed the texts, and around 5–6 minutes to train. One thing to keep in mind is that our code is not efficient at all and based on the training curve we could certainly benefit from a smaller learning rate. Our model achieved an F1 score of around 0.990.
The reported results in this blog are F1 scores of 0.993 for ModernBERT (in 5–6 minutes) and 0.990 for the original BERT (in 17–18 minutes).
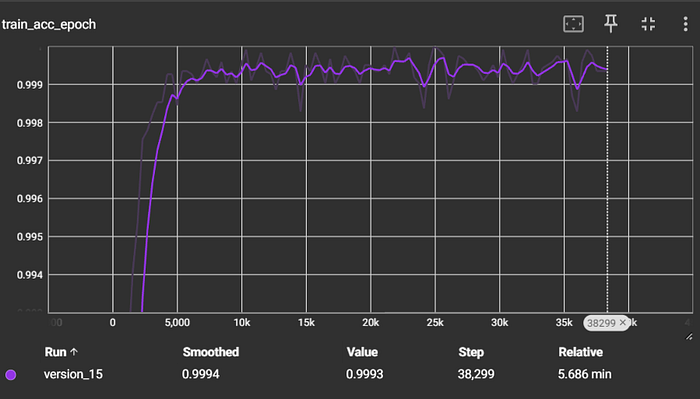
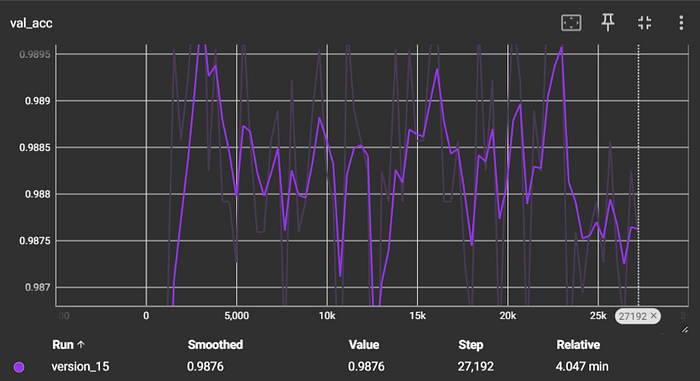
Dataset #2: Banking77
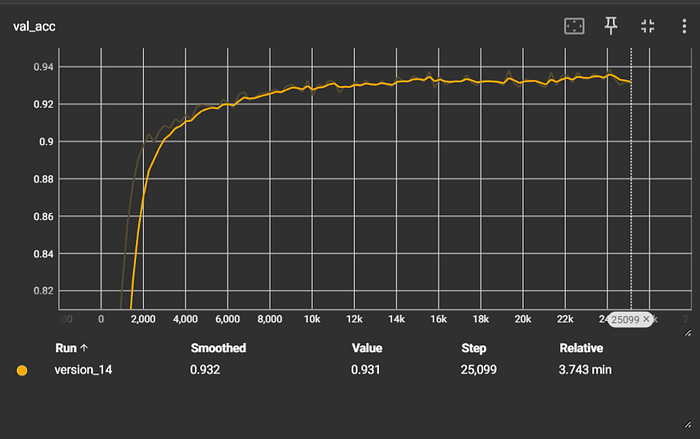
This dataset includes ~13K customer service queries with 77 classes for a banking application (e.g., change card pin, lost card, ATM support). For this dataset, our model took around 1-2 minutes to embed the texts, and around 3–4 minutes to train. Our model achieved an F1 score of 0.934.
The reported results in this blog are F1 scores of 0.93 for ModernBERT and 0.90 for the original BERT.
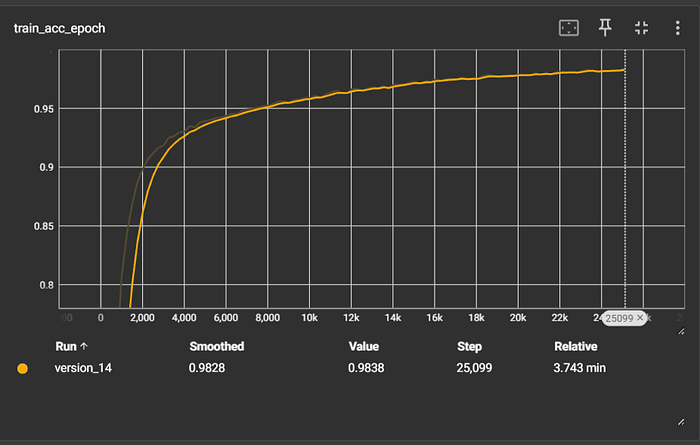
Comparison
As you saw, the solution we went over here matches or surpasses the state-of-the-art results from ModernBERT in terms of accuracy while being very cheap to train and serve. The training is simple enough to be run on a GitHub worker, and serving is portable and lightweight enough to be served in serverless settings. A major cost for deploying most AI applications like this is GPUs, but by outsourcing that to OpenAI, you can achieve a serverless-like payment structure, only paying for the GPU time you are actually using and not the idle times (which can sum up to a big portion in small or medium-scale applications).
I also wanted to mention that this solution doesn't always give you the best cost<>performance tradeoff, especially if your application has a large enough scale. The ModernBERT-base model has 139M parameters and it is likely smaller than the text-embedding-3-large model from OpenAI, so if your application is getting tens of thousands of requests per minute, you can likely saturate a couple of GPUs and might be able to run your models cheaper than OpenAI can. But for a lot of applications, especially internal applications in a company, this solution may give you a cost-efficient and maintainable solution.
But before wrapping up, I wanted to also show you how you can deploy this model in a JavaScript application as an API endpoint. If that interests you, keep reading.
Serving The Model in JavaScript (express.js)
If you noticed, I'm saving my model as an ONNX file at the end of my training code. ONNX is an open representation of ML models, and you can find converters for Sklearn, PyTorch, or TensorFlow models for it. It supports several programming languages, operating systems, and hardware accelerators. For a full list of compatible runtime environments, check out this page.
To showcase its flexibility, I opted to use JavaScript on express.js to load and serve the final model. The code below loads both models (Banking77 and LLM Router, each occupying about 200KB of RAM), gets the OpenAI embeddings and runs the model on top of it. The end-to-end latency is around 300–400ms on my connection, and the total incremental latency on top of OpenAI's embedding is <5ms, with model runtime taking <1ms CPU time. Please note that the embedding latency on my OpenAI account is relatively high (since I have an individual account), but using a service like Azure OpenAI services or an OpenAI enterprise account you can get much better latency for this component.
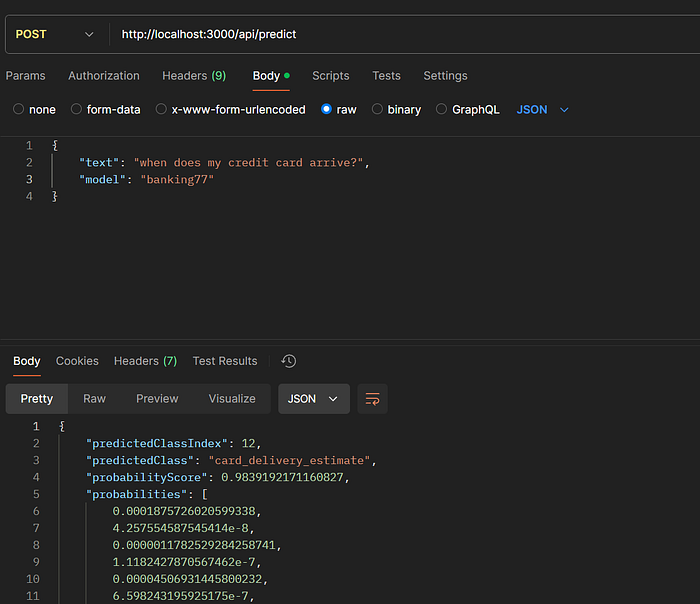
The request and response look something like the screenshot below, please note that you need to send a "x-openai-api-key" header with your OpenAI API key for this request to work, but I'm not showing it here.
Conclusion
Building an LLM router using OpenAI embeddings provides a cost-effective, scalable, and lightweight alternative to traditional approaches like ModernBERT. By leveraging OpenAI's text-embedding models, you can offload the computational heavy lifting and achieve competitive performance with minimal infrastructure requirements. This solution excels in scenarios where low operational overhead and serverless deployment are critical, making it ideal for internal tools or small- to medium-scale applications.
That said, the choice between OpenAI embeddings and ModernBERT ultimately depends on your application's specific needs. If your system requires handling a high volume of queries and can maximize GPU utilization, ModernBERT might offer better cost-efficiency in the long term. However, for most organizations seeking simplicity, quick setup, and flexible scaling, embedding-based routing models are a compelling option.
As the LLM landscape continues to evolve, having versatile routing solutions like this will become increasingly important. By adopting a framework that is easy to train, deploy, and maintain, you can focus on optimizing the user experience while staying agile in an ever-changing ecosystem of language models.
About Me
I'm currently a Machine Learning Engineer at Meta, working on ways to improve the users' experience on our ads products. Before that, I was a Machine Learning Engineer at TELUS and a Ph.D. graduate from the University of Alberta. What I wrote here is a result of my personal interest in this space and a way to organize my thoughts and findings.
In case you want to know more about me, check out my website. The views expressed on this account are mine alone and do not necessarily reflect the views of my employer.