
Hi everyone, today I want to show why you should always test websites that have no "/" directory and what many other Bug Bounty hunters might be missing out on.
Let's be honest — Bug Bounty Hunting is exhausting, especially if you are a full-time Penetration Tester / Web Developer etc. You are able to test mostly in the after hours and this leaves little to no room for flexibility — you must find vulnerabilities fast (we all hate duplicates) and you have to be good.
However, recently I have noticed that in the search of Critical/High vulnerabilities, many Hunters out there are immediatelly disinterested in websites that look like this:

Here the saying just fits perfectly:
One man's trash is another man's treasure
Many Hunters will quickly turn away from such websites (with seemingly no content). However, just because there is no content in the / directory, doesn't mean that there is no content at all.
Example 1:
While doing Bug Bounty Hunting on a wildcard subdomain Scope (*.example.com), I run my usual tools for subdomain enumeration and after some time, stumble upon a subdomain returning 404 Not Found. For the purpose of anonymization let's use the subdomain example1.example.com
After identifying such a website -> Step 1 is to start content discovery. For this I use the dirsearch tool with my own wordlist:
https://github.com/ViktorMares/ultimate_discovery
So, I start my content discovery with the following command:

And the results:
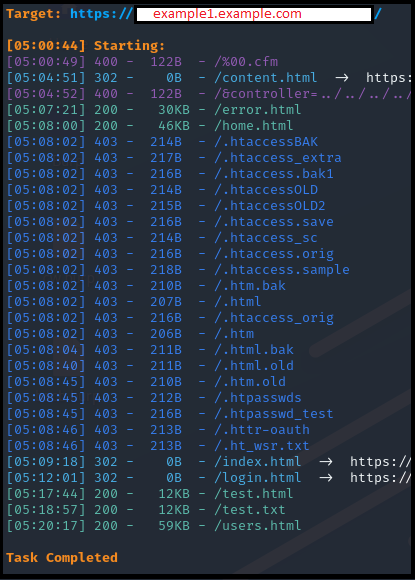
So, from a 404 Not Found, we can see that there are a few static pages.
We go to each of the static pages, one by one and at some point are able to find the following in the source code
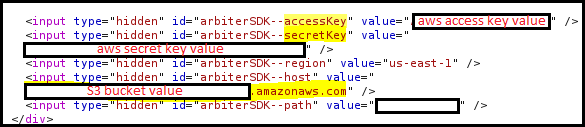
With the AWS Access Key and Secret Key, we might be able to get access to the S3 buckets and also inside the AWS infrastructure.
To see if the AWS secrets are valid, we can use the following repo:
Use the AWS Access Key and Secret Keys values and let the tool work.
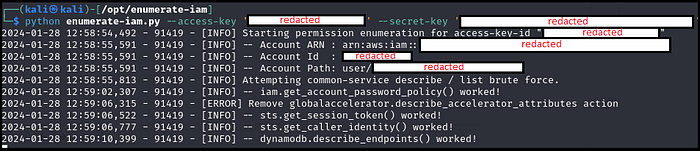
As you can see from the above, we have found credentials for AWS IAM. The user also has access to an API, however I only show the image above for Proof of Concept purposes.
So we report this vulnerability with the detailed steps and get the following response:
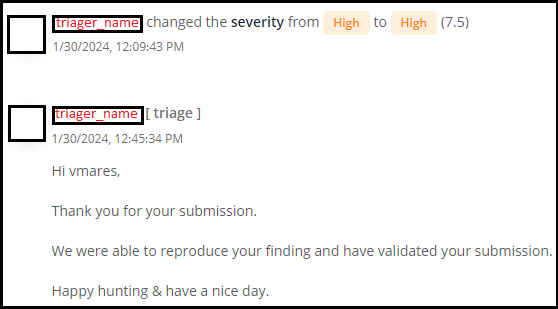
Example 2:
Once again, we start by finding subdomains (wildcard scope) and stumble upon another website (example2.example.com) that has nothing behing the / directory.

We run the dirsearch command with the custom wordlist and find the /sites webpage -> https://example2.example.com/sites which retulrs the following:
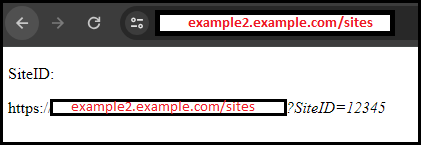
The html content shows that we can use a ?SiteID parameter to load a static site. However, the SiteID parameter is vulnerable to Reflected Cross-Site-Scripting. The tricky part is that the length of the parameter is limited, so we need to use the shortest possible XSS payload, which is <svg/onload=alert()>
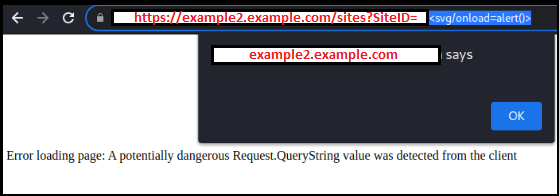
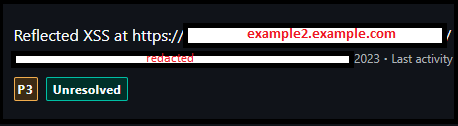
Once again, we report the finding and boom:
I hope that you found this methodology interesting and you will not be leaving any website untouched. Hopefully, this can help you with future engagements and bug bounties!
Thank you for making it so far into the story and if you really enjoyed reading it, please consider supporting me by getting an affiliate medium membership: https://medium.com/@mares.viktor/membership
Happy Hunting!